2.5 莫名其妙的“整型”
“与整数相关的类型”(Integral Types)是C89中的概念,是char类型、有符号整数类型、无符号整数类型及枚举类型的总称。在GB/T 15272-94中被翻译为“整型”。所以,目前在国内“整型”是一个相当混乱与含糊的概念。
无论是GB/T 15272-94中的“整型”、C89中的Integral Types还是C99中的Integer Types都有一个共同的特点,就是它们都是指使用整数二进制进行编码的那些类型。在本书中,这些类型被统称为整数类型(Integer Types)。
2.5.1 unsigned int类型
1.名称
也可以写成unsigned。unsigned也是C语言的一个关键字。
2.存储空间和值的范围
存储空间:和int一样,为32bits。
除了_Bool类型和枚举类型,所有的signed整数类型都有一个对应的unsigned整数类型,其存储空间相同。
值的范围:0~UINT_MAX(在Dev C++中是232-1,TC 2.0中是216-1)。
3.unsigned类型常量的写法
基本规则同int类型常量写法,不同之处在于以下两点。
(1)值在unsigned类型值的范围之内。
(2)加后缀U或u。
例如:
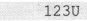
4.unsigned变量的定义方法
unsigned变量的定义有以下两种方法:

或
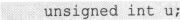
它并没有什么特别的,本篇后面也将不再提到变量定义这个话题。
5.unsigned类型的运算及规则
显然,只要结果在unsigned的值的范围内,“+”(二元)、“-”、“*”、“/”、“%”以及“+”(一元)都可以。
但是unsigned值是否可以进行“-”(一元)运算,以及一个小的unsigned值是否可以减去一个大的unsigned值,则是个比较复杂的问题。
C语言规定:-unsigned类型值的含义是0U-unsigned类型值。这样,两个问题就可以放到一起来讨论了。
值小的unsigned值减去一个值大的unsigned值,会得到一个负数,然而这个负数并不在unsigned类型表示的值的范围之内,但是这个值在int类型表示值(补码)的范围内,如果把这个int类型值的补码形式理解为相同形式的unsigned类型,那么这个就是结果。比如:
-3U
等价于0U-3U,等到的是-3,而int类型的-3的补码为
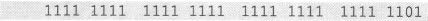
如果把这个补码形式的机器数理解为一个unsigned类型的机器数,那么这就是答案。所以:
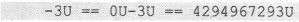
此外另一种计算的方法是:
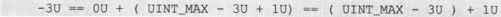
这个例子再一次说明了C语言所有的运算都与数据类型有关。在-1和-1U中的两个“-”的运算含义是不同的。只有清醒地了解数据类型才可能谈得上运算。这是掌握、精通C语言的一个秘诀,“一般人儿我不告诉他”。招聘面试的时候,常把“数据类型”挂在嘴边,会让优秀的面试官对你刮目相看。
此外需要指出的,即使结果不在unsigned的值的范围内,“+”(二元)、“-”、“*”、“/”、“%”以及“-”(一元)这几个运算对于unsigned类型的数据也是确定的、有明确定义的(但对于int 类型则不是这样)。
6.一些讨论
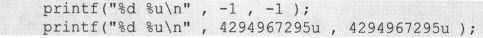
这两条语句的输出结果是意味深长的:

这表明printf()不介意-1或4294967295u的类型,它本身拥有根据%u或%d对-1或4294967295u这32bits的内容的解释权。也就是说无论-1或4294967295u本身是什么类型,%u都将把表示这个值的32bits按照无符号类型进行解释,并求出其相应的十进制格式的字符序列,插入到格式说明%u所在的位置进行输出。%d的意义也类似于此。
此外需要顺便提一下的事情是,sizeof运算得到的结果的类型是某种unsigned类型,具体由编译器确定。
2.5.2 long、short关键字描述的整数类型
long类型:亦写做long int、signed long、signed long int。C语言要求这种类型精度至少为32bits。具体编译器中值的范围由limits.h文件中的符号常量LONG_MIN、LONG_MAX规定。在Dev C++中和TC2.0中均为-231~231-1。在代码中写long类型的常量,无论是以十进制、八进制还是以十六进制方式写,均应(17)加后缀L或1。
尽管在Dev C++中long类型和int类型非常一致,但它们依然是两种类型。
unsigned long类型:亦写做unsigned long int、unsigned long。这种类型的位数和long一样。在limits.h文件定义这种类型最大值的符号常量是ULONG_MAX。在Dev C++中和TC2.0中这个值都等于232-1。unsigned long类型常量的后缀标志是LU、lu、Lu或lU。
short(short int、signed short int)及与之对应的unsigned的都被要求至少具有16bits的精度。但具体的数值范围则取决于编译器和机器采用的码制。这种类型没有对应的常量的写法。
long long类型及unsigned long long是C99中出现的新类型,标准要求它们都必须是64位或64位以上的二进制数,在Dev C++中这两种类型都是64位。在用补码表示整数的前提下,其数值范围显然应该分别是-263~263-1和0~264-1。long long类型常量的后缀标志是LL、lL或Ll。
练习
按照C语言源代码的格式要求写出下列各常数。
(1)7,890
(2)215
(3)(07AB89)16
(4)(11100110)2
2.5.3 没有常量的char类型
计算机处理文字的基本原理是首先把文字编上号,然后在计算机内部以二进制格式存储处理这个编号。输出时候根据这个编号由特殊的软件在输出设备上“画”出相应的文字形状。编码工作一般由国家或权威的标准制订机构完成。历史上有过几套文字编码方案。
1.ASCII码
最初,计算机只处理128个字符(主要是你在键盘上看到的那些),这128个字符被编号为0~127号,这个编号叫做ASCII码(18)值。编号对应的字符的样子或图案叫ASCII码符,这是计算机最常用的字符集,是由美国国家标准协会制订的一套标准(1968年),全称叫美国信息交换标准码。这套编码方案被国际标准化组织(International Organization for Standardization, ISO)批准为国际标准,因此也是目前使用最广泛的一套编码。
标准ASCII码使用7个二进位(bit)对字符进行编码,对应的ISO标准为ISO646标准。虽然标准ASCII码是7位编码,但多数CPU的基本处理单位一般为8bits,所以一般仍以8bits来存放一个ASCII字符的编号。多余出来的一位(最高位)在计算机内部通常保持为0(在数据传输时可用作奇偶校验位)。
128个字符中有96个是可打印字符,包括常用的字母、数字、标点符号等,另外还有32个控制字符,通常在键盘上没有对应的键,一般无法通过键盘直接输入,在显示器上的显示也是五花八门,换句话说,是由具体实现来定义的。
适当地仔细观察、了解并记住ASCII码表对于学习C语言是有益的和必要的。至少应该了解在这个表中字母和数字是按照顺序编号的。此外还应该知道字母A的编号是01000001B或者65D以及大小写字母的编号相差00100000B或32D。否则你可能看不懂某些代码也无法写出某些程序。
本书后面对char类型的讨论,除非特别说明,以ASCII码为讨论基础。这并不等于说C语言只能处理ASCII码这种字符,事实上C语言可以处理各种编码方案的字符,而且事实上即使对于拉丁字母,也不仅仅有ASCII码这样一种表示方案在使用。
2.char类型的不确定性
char是描述这种数据类型的关键字。和前面几种整数类型类似,有signed char和unsigned char两种对应的类型。在C标准中char类型、signed char类型和unsigned char类型被统称为character类型。
和前面几种整数类型不一样的是,C语言没有规定char类型究竟是signed char类型还是unsigned char类型。编译器可以决定自己的char究竟是signed char类型还是unsigned char类型。所以“signed是可以省写的”这一说法,如果不说是错误的,那么至少也是不严谨的。
char类型的长度也不确定,C语言规定char类型至少应该是8bits,这个值同样在limits.h文件中规定(CHAR_BIT)。
char类型的这种不确定性,使得对这种类型全面的讨论变得十分困难烦琐。所以在后面的讨论中,均假定char类型为8bits,且char类型等价于signed char类型。但请特别注意这并不是普遍的情形。
在我们假设的情况下,char类型值的范围是-128~127的整数。存储ASCII码值只用到其中的0~127。
3.字符常量不是char类型
可以根据ASCII码符,直观简洁地写出与之对应的常量。方法是把这个字符写在两个“'”之中。C语言用这种方法区别描述作为代码的字符(比如标识符A)与程序要处理的字符。例如,对于程序要处理的字符A,代码中写做'A',而作为代码成分的字符则直接写成A。
然而'A'却并非char类型,事实上它是int类型,根据ASCII表可以知道它的值为65。下面的一个简单代码的运行结果可以让我们确认这一点。
程序代码2-9

运行结果如下:

很显然,'A'不可能是char类型。为了叙述方便,后面将把'A'称呼为“字符常量”,但需要特别清楚的是字符常量不是char类型而是int类型。
这样,主流教材中所谓“字符型数据”的概念,就完全是一种有意无意的、但却是彻头彻尾的误导。因为在C语言中根本就不存在char类型的常量。而所谓的“字符型数据和整数型数据是通用的”也就成了无的放失。在了解了'A'是int类型之后,还会有人对下面语句的输出感到惊奇吗?
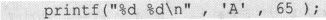
输出结果如下:

而对于下面的语句:
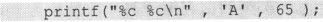
其输出结果如下:

其实同样不值得大惊小怪,因为%c的含义本来就是把一个int类型的量转化为它所对应的字符输出。%c并不是用于char类型的,它本来就用于int类型。
当无法写出这种与字符对应的字符常量时,可以使用其他办法。比如,直接写字符的编号也没什么不可以的。但那样的写法由于缺乏可读性而不被提倡。比较专业的写法有,前一章提到的所谓的转义序列。
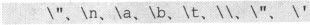
但是要注意的是把转义序列写到字符串文字量内,也就是""之内的时候是不用写“'”的,而单独写成一个字符常量时需要用一对“'”括起来。比如:

另外两种转义序列的写法是:
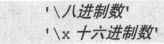
其中的八进制数和十六进制数就是字符编号。这种字符同样也可以写在字符串文字量中,只是不再需要两边的“'”。
4.char类型变量几乎总不是char类型
如程序代码2-9的运行结果所揭示的那样,尽管字符常量是int类型占32bits,但char类型却是占8bits。比如变量定义:
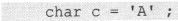
中定义的变量c。可以证实sizeof c的值是1。
原则上,应该使用相同类型的数据给一个变量赋值,但对于char类型的变量这几乎是不可能的。前面的变量定义中:
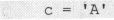
实际上是在用一个int类型的常量给char类型的变量赋值,也就是说是在用一个位数较多的数据给一个位数少的变量赋值。这显得有些滑稽,好像是在试图给int类型的数据穿小鞋。实际上这在C语言中也是容许的,但我们必须了解这样赋值的前提条件。目前阶段需要掌握一个原则,那就是对于整数类型来说,所赋的值应在两种类型的值的公共范围之内。
现在,只有一个问题可能让严谨的初学者感到困惑。那就是,既然char类型变量是1个字节,那么为什么可以这样写:
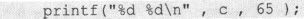
这样的语句,%d所要求的被转换的机器数不是int类型或者是一个32bits的整数类型的吗?难道真的有“字符型数据和整数型数据之间可以通用”这回事情吗?其实不是的。真相其实是在printf("%d %d\n", c, 65);中出现的那个c并不是8bits而是32bits。这可能有些让人难以理解,且容我慢慢道来。
我们知道,一个变量名,其含义并不是完全可以孤立地确定的,而是根据它在代码中的上下文具体场合而定的。变量名可以表示变量名所命名的存储空间所表示的值,也可以表示存储这个值的那块内存空间。在c='A'和sizeof c中c毫无疑问表示的是后一种含义,即内存空间的含义。有一个简单的特点可以帮助你判断变量名究竟是何种含义。那就是,变量名表示一块内存空间含义时,运算的结果与内存中的值无关!在其他场合变量名代表的则是变量名所命名的那块内存空间内的值。即是下面这样:

其中,c很明显表示的是c内存中的值。C语言规定,char类型的值在编译时一律替换为int类型的值。这也就是说,在下面语句中:
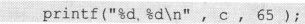
c实际上就是一个int类型的65。
这样看来,在代码中,其实char类型的变量也几乎不存在,只要是char类型的值,同样也是int类型。也有少数的几种例外,如被赋值时,做sizeof运算时……因为这时结果与变量原来的值无关。
5.在标准输出设备上输出单个字符
在C语言中,标准输出设备通常指的是控制终端的显示器。这种设备的功能是把计算机内部的数据用字符这种人类可以清楚感知的形式表示出来(19)。
比如函数调用“printf("ABC123")”的功能之一是把A、B、C、1、2、3这几个字符组成的连续字符序列在屏幕上依次显示出来。
计算机内部的数据通常是无法直接显示的,如“123”这个常量,必须通过调用printf()函数把这个计算机内部的二进制数转换成的连续的字符序列之后才能输出。例如,“printf("%d", 123)”就是把计算机内部的用32位二进制数表示的123转换成1、2、3这个连续的字符序列插入到字符串中输出。
因此,printf()函数用于让标准输出设备输出一个字符串,或是把某种计算机内部的数据转换成字符串再输出。
在C语言中,如果想让标准输出设备输出单个字符,可以通过调用putchar()函数实现。putchar()函数的调用方法是在括号内写一个int值,函数调用的结果是求出与这个int值相适应字符的编号,另一个作用是在标准输出设备上输出这个相对应的字符。例如:

输出结果为:

而putchar(97)的值是97。为了证实这一点,请自己试一下下面语句的效果:
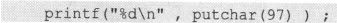
这里解释一下“求出与这个int值相对应字符”,它的意思是取这个int值的最低位的7个bits。不信?试一下下面这个语句:
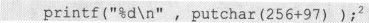
2 把256改成128的结果是很有意思的,但这与初学者无关。请初学者不要碰这个问题。
此外不难看出,由于putchar()函数的“()”应该写一个int类型的值,所以'A'这样的int类型的所谓字符常量显然也是可以的。但应当特别清醒的是'A'于"A"是完全不同的东西。最核心的区别是它们属于不同的数据类型。前者是一个int类型的“字符常量”,而后者是一个“裸串”(String-Literal),这种数据类型将在后面有关章节专门介绍。在存储上两者也有很大的不同,后者不但需要存储与'A'对应的字符还要额外存储一个串的结束标志——与'\0'对应的那个字符(一般叫空字符,null character)。
printf()函数“()”内的格式控制字符串必须是“裸串”(String-Literal)或其他种字符串,而putchar()函数的“()”里面需要写一个int类型的值,实际的输出效果及putchar()调用得到的值通常只与这个int类型值的最低7位有关。
使用putchar()函数时同样要对标识符“putchar”加以必要的说明,方法同样是通过在调用前putchar()加入预处理命令:

当然,如果已经写过这条命令就不用写第二次了。因为#include<stdio.h>的含义是把stdio.h中的内容完全地“复制”并“粘贴”到这里。
2.5.4 其他
没有讲到的整数类型还有枚举类型和C99新增加的_Bool类型。实际上对于语言的功能来说这两者是可有可无的,没有这两种类型C代码也可以工作得很好。
枚举类型是一种体现了C语言尚美精神的类型,其本质就是一种整数类型的小的子集;而_Bool类型,说实话,我个人感觉它比鸡肋还缺乏味道。
本书将在后面适当时候介绍这两种类型。但是请确信,不知道它们,你的代码也可以工作得很好。
下面介绍浮点类型(Floating Types),或者说是C99的实浮点类型(Real Floating Types)。
