5.3 for语句
5.3.1 语法要素
关键字:for
语法:for([表达式1]; [表达式2]; [表达式3])语句
其中,表达式1、表达式2和表达式3部分可以没有,但是()内的2个“;”永远都是必须的。这样for语句就成了唯一一个可能带有3个“;”的C语言控制语句。
执行过程如下。
(1)求表达式1的值,如果表达式1不存在则直接进入下一步。
(2)求表达式2的值,如果这个值为0则结束for语句,程序的控制权转给for语句的下面一句,否则执行(3),如果表达式2不存在则直接转入(3)。
(3)执行语句。
(4)求表达式3的值,然后转向(2),如果表达式3不存在则直接转向(2)。
大体上,for语句相当于对while语句的一种补充,如果借助while语句的N-S图来描述的话,那么for语句的执行过程可表示为如图5-3所示。
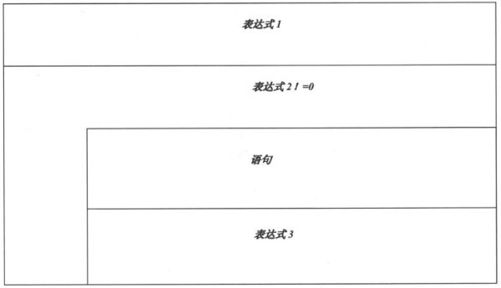
图5-3 for语句的流程图
也就是说for语句等价于下面的语句:

需要说明的是,当for语句的表达式2缺省时等价于下面的语句:

在C99中,表达式1部分可以定义仅仅在for语句内部使用的变量。例如:
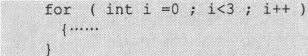
但目前支持这一写法的编译器尚不多。
由于for语句本身结构的特点,所以特别长于表达次数一定的循环(当然for语句同样也可以表述次数不确定的循环)。对于次数一定的循环,最重要的一件事情是把循环的次数写正确。但是令人遗憾的是,并不是每个人都会数数。这样说估计有些人会感到恼怒,然而在编程时的确如此。100米长的道路,每10米设立一根电线杆,一共需要多少根电线杆?对于这种小学生的题目,如果你能脱口而出地回答出“10”这个不正确的答案,十有八九你会在写循环语句时把循环次数弄错。如果你觉得这问题不那么容易回答,那么恭喜你,这是for语句开始入门的标志。所以让我们从学习数数开始。先来学习写一个循环3次的for语句。
程序代码5-6

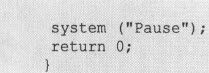
如果能一眼看出这段代码的输出结果,表明已经正确地理解了for语句。可以直接阅读下一小节。

循环体部分执行了一共3次,这个次数是由i的初始值0以及条件表达式1<3确定的(当然还有i++)。在这3次循环中,循环变量i的值依次为0、1、2。循环结束是因为i的值变成了3。
专业人士在多数情况下总是用这种方式写for语句的。对于他们来说,for(i=0;i<3;i++);这个语句一共循环3次是一个不须加以思索的定理。初学者在这里往往要认真地想一想,到底应该写i<3还是i<=3,匆忙之中循环次数不是多了一次就是少了一次。
for语句结束后i的值为3,这一点也常被忽视。实际上这恰恰是这条for语句结束的条件。正是由于i的值为3,因而i<3的值为0,所以for语句才结束。
当然,for语句的具体写法还要视具体问题及算法而定,但是把:

这样的语句作为一个“句型”来理解,知道这样的循环进行m次,循环结束后i的值为m,没有什么不妥。因为这样的句式太常见了,无论是在读代码时还是在写代码时。
for语句的()内有两个“;”,初学者很容易忘记这点,所以这里再次友情提醒一下。其实在比较专业的人士那里,忘记或忽略这两个“;”几乎是不可能的事情,因为这里的“;”的作用和语句后面的“;”一样,具有着“序点”的作用——程序执行到序点时必须完成前面的规定动作,就如同一个学生必须修够学分才能毕业一样,至于学分哪个是先修的哪个是补修的是没所谓的。这个常识,在日常生活中许多人都懂,但在C语言中却容易犯晕。下面讲解与此有关的一个运算符++,这个运算被很多人深深地误解和误读,以至于在这个问题上,许多有志于学习C语言的初学者都曾被深深地误导,甚至丧失了继续学习的勇气。
练习
1.求1×1+2×2+3×3+……+100×100(这个题目不容易测试,可以先计算数目少些的平方和测试)。
2.计算并输出2的0到10次方。
3.111111的个位、十位、百位是几?
4.Fibonacci数列指的是这样一个数列:1、1、2、3、5、8、13、21……这个数列从第三项开始,第一顼都等于前两项之和。编程求该数列的第20项。
5.3.2 “++”之惑
在前面for语句的例句中,i++和i = i + 1所起到的效果是完全相同的,但实际上这两个表达式真正的含义却并不相同。由于++很容易给初学者带来困惑,所以有必要在此详细剖析一下。
1.有几种“++”?
一共有两种++运算符。一种++运算符是写在运算对象的后面,如前面小节代码中的i++,另一种++运算符是写在运算对象的前面,如++i。
写在运算对象后面的++叫后缀加运算符(Postfix increment operator)(1);写在运算对象前面的叫前缀加运算符(Prefix increment operators),是个一元运算符。这两种运算符一模一样,但是它们的优先级和结合性却完全不同。前者的优先级是16(最高级别,和函数运算同级),结合性从左到右;而后者的优先级是15(和所有一元运算符相同),结合性从右到左。
这情形和“-”既可以作为减法运算符也可以作为求负值运算符一样。在“5-3”这个表达式中,“-”是减法运算符,优先级为12;而在“-3”这个表达式中,“-”是求负值运算符,优先级为15。编译器可以通过“-”所处的上下文判断出它究竟是哪种运算。代码的编写者更应该清楚两者之间的差别。
在这一点上,很多初学C语言的人都很容易轻率地认为两者是同一个东西。但是,从以上介绍来看,它们两者之间真的是相去甚远。
不过,无论是后缀加还是前缀加,其运算对象都必须是左值表达式(严格地说是可修改的左值表达式)。而所谓的左值表达式,到目前为止我们只见过一种,就是单个变量名构成的初级表达式(也可以在变量名外面加上(),这种写法十分罕见,但含义一样)。
2.两种“++”运算符的区别
上面说的是++运算符具有两种不同的意义,那么在实际操作中,两种运算符究竟又有什么不同呢?下面以int类型变量i为例进行介绍。
对于一个int类型变量i,++i的确切含义是求i的值,此外这个运算还有一个“副效应”(Side effects),即是在求i值之前,先将i赋值为i+1。而i++的确切含义同样是求i的值,这个运算也有一个副效应,即是求完i值之后,将i赋值为i+1。
现在核心的问题就出现了。上文中的“求i值之前”和“求完i值之后”,这只是一个时间范围,而并不是一个确切的时间点,因此我们还是不知道到底在何时i会被赋值为i+1。总不能在程序一开始运行的时候就加1吧,要知道那时候变量可能还不存在或者还没定义呢;也总不能等程序运行结束之后再加1吧,那样的副效应还有什么意义呢?
此时,必须借助“序点”(Sequence Point)这个概念才能把这个问题说清。所谓序点,简单地说,就是程序执行时一些虚拟的“节点”,这些“节点”对应着代码中一些特定的位置。在这些“节点”之前代码所要求计算机执行的所有动作(包括副效应)在这个“节点”处必须完成。由此可见,序点是C语言用于规定或说明运算次序的一个基本概念。
就目前为止,我们见过的序点有语句的结束标志“;”或“}”,“?”(问号),“,”(逗号),if语句、while语句、do-while语句及for语句中的()的“)”,for语句“()”中的“;”,此外main()函数的“{”实际上也是一个序点。
因此,不难理解,表达式“i++”的真正含义即是,在求得i值之后,下一序点之前,完成i=i+1这个副效应操作(表达式永远是用来求值的,其余的都是副效应)。而表达式“++i”的真正含义是在前一序点之后,求i值之前,完成i=i+1这个副效应操作。
同理,“—”运算符也有两个不同的意义,即后缀减运算符和一元前缀减运算符,除了表示在求变量值之后(之前)变量的值需要被减去1之外,其性质和对应的“++”运算符是一致的。
此外要说明的是,“++”、“—”(无论是前缀还是后缀)的运算对象可以是任何整数类型、实浮点类型或指针类型。
3.使用“++”的常见错误
到目前为止,我们终于将两种“++”运算符不同的运算含义解释清楚了。然而,在现实的运用中,这个两个“++”运算符还是会经常让我们感到头痛,甚至很多成熟的编程团队也会将其定义为尽量避免使用的运算符。那么,这个谜一样的运算符,为什么会成为不少程序员极力回避的禁忌呢?
我们首先来看看下面这个简单的代码片段:
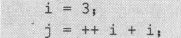
按照前面我们讲过的原理,在第二行的表达式里,CPU读取第一个i值(求++i的值)之前,需要完成将i赋值为i+1这个副效应。但问题在于,在前后两个序点之间,CPU需要两次读取i的值,我们并不清楚会先读哪个i,这个次序选择权在于编译器。我们根本无法控制。也就是说,上面那句话可能表示两种不同的运算语意,产生两种完全不同的运算结果。
■ 语意一:
完成副效应i=i+1(i的值变为4);
读第一个i值(此时赋值的副效应已经完成,i的值为4);
读第二个i值(i值已经变为了4,这个i值自然也不例外);
两次读得的i值相加,把结果写入j内存(结果即是8)。
■ 语意二:
读第二个i值(此时i值为3);
完成副效应i=i+1(i的值变为4);
读第一个i值(此时赋值的副效应已经完成,i的值为4,于是出现了第一个i值和第二个i值之间的值并不相等的现象);
两次读得的i值相加,把结果写入j内存(结果竟然是7)。
由于C语言并未明确规定这些运算的次序,因此在完全符合C语言语法规则的前提下,竟然能得到两种结果,这就是所谓的“二义性”。
编写程序时候是不可能容忍代码存在这种“二义性”的,否则程序很可能就变成了“鸡同鸭讲”。代码必须具备唯一确定的语意。
除了涉及到序点,C语言没有规定编译器在这种情况下应该究竟选择哪种语意,这样,表达式j=++i+i就成了一种未定义行为。如同前面曾经提到的那样,这种未定义行为尽管不违背C语言的语法规则,但本质上却是一种错误的代码。
以这里讨论的表达式为例,在求“+”运算符右边的i值的时候,从C语言或代码的角度来说,并不能确定i在内存中确切的值。因为在求“+”左面的操作数——表达式“++i”的值的时候可能改变i的值。由于没有规定求“++i”的值和求“+”右边的i值这两个动作之间的次序,于是求表达式“++i+i”的值就成了一个未定义的行为。
未定义的行为出现在代码中,就是一个“语病”。只不过这里我们说的“语病”不是那种不符合语法要求的语病,而是那种语法上符合要求,但在语言或代码层面却无法确定其唯一含义的语病。比如,有一个大家很熟悉的广告词——“××皮鞋,足以自豪的皮鞋”,语法上这句话绝对没有问题,但那个“足”字显然是一语双关的,作为广告语这很好,但编程不是做广告,计算机也不会听你忽悠,它只接受具体明确的、不带有“二义性”的指令。而代码中没有语法错误的“二义性”会导致编译器为你“胡乱”选择一种语意。这当然是不可接受的。
根据程序运算结果揣测j=++i+i这样未定义行为没有确定含义的表达式的含义是肤浅幼稚的。因为未定义行为不但是不可能预测的,同样也不可以逆向推测。它产生什么样的后果都不奇怪,哪怕让机器死机,关闭电源甚至火山爆发。C语言的学习者之间经常会出现很多类似这样的可笑对话:一个学习者问,为什么这个计算机(编译器)说“足以自豪的皮鞋”里面的“足”字是“脚”的意思,而不是“足够”的意思?另一个学习者立刻反驳,不对!我的计算机(编译器)明明说“足”是足够的意思嘛!
这两个不明就里的学习者也许会争论上好一阵子,却也得不出一个所以然来。本书的读者对此应该有个清晰的认识,能够很轻松地告诉他们代码“二义性”的来龙去脉。
下面,列出了一些C语言中典型的“二义性”例子。

这些例子,都会让编译器陷入那个“足”是脚还是足够的疑惑。写出这种表达式的人,说明其对于运算符的真实含义还是缺乏了解。可惜的是,在现在国内很多专业的C语言论坛中,还是会有不少程序员,在这个问题上疑惑不解。
这些人往往都还有另一个误区,这个误区就是把优先级和结合性与运算次序相混淆,他们难以理解为什么优先级高的反而后计算。比如下面的表达式:

在这个表达式中,“++”的优先级最高,但这个运算却不是最先进行的。这里的优先级只是决定了“++”这个运算符的运算对象是i,而不是“j+i”,即:
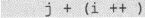
也就是说这个表达式的意义是计算“j+i”的值,再加上一个副效应。而这个副效应发生的时间,我们只知道会是在编译器求完i值之后,但我们无法知道会是发生在计算“j+i”值的之前还是之后。
然而,不少人把优先级理解成了小学里的“先乘除后加减”,这是完全的误解。这里需要再次强调的是,优先级和运算次序完全是两回事!
对于初学者来说,另外一个错误不得不提。就是,++或—(无论前缀或后缀),只能用于左值。比如,int i;“++i”是可以的,因为i是左值;但++(i+1)是一个语法错误。因为(i+1)只有值的含义不可能表示一块连续的具有类型含义的内存(左值),因此(i+1)只是一个右值表达式。在目前这个学习阶段,只有变量名这种初级表达式是左值表达式。
4.总结
好了,现在我们完全搞清了“++”运算符的来龙去脉。那么,在代码中应该如何避免上面所提到的“二义性”问题呢?
首先,我们需要把握一个原则,即不在两个序点之间更改同一个变量(严格的术语是对象)两次或更多次(a += a -= a * a就是违背了这种原则的错误代码),如果两个序点之间只写一次某一对象的值,但同时还存在着读这个对象值的情况,那么必须确保写这个对象的值发生在读这个对象值之后。所以,表达式i=i+1的行为是确定的,而表达式++i+i则属于未定义的行为。
其次,尽量少使用可能引发“二义性”的复杂表达式。熟练的程序员在使用“++”这类运算符时是极其审慎的,在利用“++”的副效应时,一定要确保不会发生出乎自己意料之外的结果。
或许有人会问,这么麻烦干什么,直接取消可恶的“副效应”不久可以了吗?然而,“副效应”真的那么可恶吗?是否取消了副效应就可以一了百了了呢?其实不是的。
副效应不一定是什么坏事。比如前面例子中for语句中的“++”就是利用了其将i值加1的副效应使得代码写得非常简洁,而求得的1值本身倒是没有什么用处的。
而且,没有副效应的表达式语句,在编译器看来是可以不理睬的废话。比如:

这句话,几乎所有的编译器都不会执行。我们最常用的printf()函数,其实多数情况下使用的是它的副效应,而函数调用得到的值几乎很少被用到。编译器对这样有副效应的表达式语句不可能置之不理。
因此,副效应是非常有用的,有时候甚至是必须的。作为一个合格的程序员,应该善于使用副效应。但是在涉及到改变变量在内存中的值的表达式中,一定要慎重,否则就会像前文中那些例子一样,画虎不成反成犬。
5.3.3 for语句应用
1.求最大公约数和最小公倍数
例题:输入两个正整数,求它们的最大公约数和最小公倍数。
程序代码5-7

代码是根据最大公约数和最小公倍数的定义编写的,在l到m之间,不满足m%i!=0||n%i!=0的就是m、n的公约数。由于i是从m到l逐次递减的,找到第一个公约数之后循环语句结束,因此找到的是最大公约数。求最小公倍数的道理与此类似。
程序没有考虑输入的不是两个正整数的情况,这是应该也是必须改进的地方。
此外,这种算法的效率可以进一步提高。因为,两个正整数的最大公约数显然不会大于这两个正整数中较小的那个,而两个正整数的最小公倍数显然不会小于这两个正整数中较大的那个。所以,如果从两个正整数中较小的那个开始寻找最大公约数,从两个正整数中较大的那个开始寻找最小公倍数,效率显然要更高些。
更好的改进如下。
2.改进
程序代码5-8

结果如下:

由于保证循环变量i从m、n中较小的数开始,循环次数至少不多于前面的代码,所以效率得到了提高。但对于m、n的值较大的情况而且其最大公约数较小的情形,由于i每次只减去1,所以循环次数还是很可观的。
进一步提高效率的算法基于这样的原理,正整数m与n(假设m>n)的最大公约数和m-n的最大公约数与n是一样的,进而也与m%n与n的最大公约数一样。请自己想清楚这个道理,在后面习题部分将有这个练习。
练习
依由小到大次序输出所有分母为30的真分数。
3.验证一个简单的数学常识
例题:分别计算出自然数中前1个、前2个……前5个奇数的和并输出。
题目比较简单,用于累加的变量的初值应为0。
程序代码5-9

结果如下:

其中表达式i ++,js++,js++由于序点(“,”)的存在,并不属于在相邻序点之间多次改变对象值的情形,因而是确定的表达式,当然这个表达式也可以写成i ++,js += 2 ;。
这个题目的输出结果很有趣,它实际上提供了一个判断一个正整数是否是完全平方数的算法(严格的证明是一个简单的数学问题),甚至提供了一个求一个整数平方根精确值或近似值的算法。
4.判断一个正整数是否为素数
例题:判断一个正整数m是否为素数(质数)(2)。
素数的定义是只能被1和自身整除的、大于1的正整数。从一般意义上讲,除了根据素数的定义,目前还没有什么特别有效的方法可以判断一个正整数是不是素数。代码算法依据的原理主要就是这点,从2到m-1一个一个的去试除这个数,如果皆有余数,那么m就是素数。然而1和2显然并不适合用2到m-1逐个判断这种方法,必须另外考虑。
除了2以外,所有的素数都是奇数。因此对于大于2的偶数都不用检验是否是素数。
此外,由于m如果有不等于1的因子,那么必然有小于或等于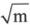 的因子,这样就不必从2试到m-1了,从2到
的因子,这样就不必从2试到m-1了,从2到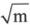 显然在多数情况下大大减少了循环的次数。而这个
显然在多数情况下大大减少了循环的次数。而这个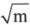 的近似值可以应用程序代码5-9所揭示的原理求得。
的近似值可以应用程序代码5-9所揭示的原理求得。
由于现在还没有讲到更好的停止循环的办法,所以代码中设置了一个标志变量bsss,这个值如果为1表示不是素数,为0表示是素数。初值为0,一旦在试除时余数为0,则把bsss赋值为1,并通过这个办法结束循环。
程序代码5-10


