11.4 更自由地使用内存
11.4.1 100!=?
用纸笔计算100!并不需要复杂的计算步骤,只要从1开始不断地乘下去就能得到正确的结果。
然而,这样做有一个前提,那就是必须有足够的纸张,因为100!是一个很大的整数。
用程序计算这样的问题时,也必须为存储这个结果提供足够的空间,此外还存在着另外一个问题,那就是C语言所提供的基本数据类型中没有一个能够精确地表示这样大的一个整数。
后一个问题比较容易解决。可以效仿平时的记数方法,用多个“位”表示一个比较大的数。比如,如果“int”类型为4B,那么可以表示最大正整数可以达到“2147483647”,这是一个10位的数,那么如果用两个“int”就完全可以表示出一个20位的数。事实上,我们平时书写数字时就是这样做的。
这样看来,表示100!的计算结果时只要为它提供足够的存储空间就可以了。比如说,如果需要记录一个20位十进制整数123454678901234567890,在代码中可以分别用两个“int”数据类型的数据记录其前10位和后10位。
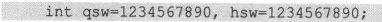
当然,对于这样的大“整数”,其运算不能直接用“+”、“-”等运算符来完成。而必须通过代码重新定义实现。但是毕竟得承认,这个问题可以解决了。
11.4.2 老土的办法
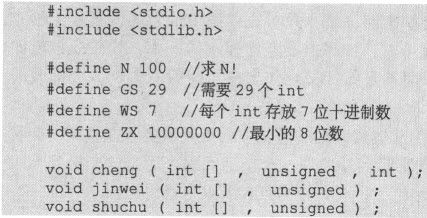
在确定了用多个“int”数据来表示一个较大的整数这个方案之后,首先要面临的一个问题是需要多少个“int”?这个问题的答案一方面取决于100!大致有多少位数,另一方面取决于代码中用一个“int”表示几位十进制数。
出于保守的考虑,由于100!<10099,后者是一个199位的十进制数,所以要求采用的数据至少要能存储下199位的十进制数。
“int”类型的数据所能表示的最大的正整数是INT_MAX(4B的情况下为2147483647,这个数据在limits.h中给出)。由于用来表示100!的每个“int”类型的数据都需要做乘法运算,最大要乘以100,代码必须保证此时不会产生溢出,所以每个“int”类型的数据最多只能表示INT_MAX/100这样大的10位数,这样才能保证在进行乘法运算时不会产生溢出。
对于INT_MAX为2147483647的编译器来说,INT_MAX/100的值为21474836,是一个8位数,因此如果输出的是十进制结果,那么每个“int”存储7位十进制数比较合理。这样,存放100!就至少需要“199/7+(199%7!=0)=29”个“int”类型的数据。在代码中可以把它们定义为数组。下面是按照这种方案给出的代码。
程序代码11-7

程序输出如图11-7所示。

图11-7 老土的办法
这类问题很难测试,因为事先并不清楚100!究竟是多少。但是可以把代码中的N改小些进行测试,因为N比较小时,N!的值容易知道。
最后100!得到的是个158位的十进制数。也就是说,实际上只需要23个“int”数据就够了。所以,这样取内存空间上界的办法无疑要浪费一些内存。
这种写法并不是很好。除了浪费内存空间以外,在不能事先估计出所需要内存的上限情况下,这种办法根本无效。下面介绍另一种办法。
11.4.3 动态分配内存函数
C语言通过调用库函数实现动态分配内存。
所谓动态分配内存,是与前面通过变量定义的方法相对的。动态分配内存不是通过事先定义变量的方式来获得可以使用的内存,而是在程序运行过程中通过函数调用来申请对内存空间的使用权。
在C语言中,这种可以申请使用内存空间的函数一共有3个,其函数原型分别如下所示。

不难发现,这些函数的返回值类型都是“void ”类型,这是因为这些函数在编写时无法预料应该返回什么样类型的指针,所以只能返回一个所获得的内存起始字节的地址。在C语言中,由于“void ”类型的指针可直接赋值给其他类型的数据指针变量,不需要类型转换(反过来也是),所以这种类型的指针有时被叫做通用指针。
3个函数原型中的“size_t”是一种数据类型的名称,通常是某种“unsigned”整数类型的另一个名字而已,在C语言早期,该类型也被称为是某种“int”类型的别称。这个类型名称正如其名字所提示的那样,用于描述内存空间的尺寸大小。事实上,“sizeof”运算的返回值就是这种类型。定义这种数据类型是为了加强代码的可移植性。
3个函数的功能如下。
void *malloc(size_t size):申请“size”个字节连续内存空间,返回值为得到的内存空间起始字节的地址。返回0值(一般用NULL符号常量表示)时表示申请失败。
void *calloc(size_t nmemb, size_t size):申请“nmemb×size”个字节连续内存空间,返回值为得到的内存空间起始字节的地址。返回0值(一般用NULL符号常量表示)时表示申请失败。和malloc()函数不同的是,calloc ()函数所申请到的内存空间被按位清零。
void realloc (void ptr, size_t size):一般用于再次申请内存空间的情况。申请“size”个字节连续内存空间,返回值为得到的内存空间起始字节的地址。返回0值(一般用NULL符号常量表示)时表示申请失败。“ptr”为此次申请前所申请空间的起始地址,那块内存中的数据将被copy到新申请的这块内存中。很显然,如果“ptr”的值为NULL的话,那么调用realloc()函数等价于调用malloc()函数。
申请内存空间并不是一定能够成功,在失败的情况下,3个函数的返回值都是“NULL”。在写代码时应该考虑到申请内存可能失败这种可能。
此外要注意的是,不要一直占用这些临时申请的内存,一旦不再需要就把它们应该释放掉。否则将会导致内存资源紧张,程序崩溃。释放内存的函数的函数原型如下。
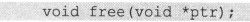
以上4个函数统称为内存管理函数,其函数原型都在“stdlib.h”这个文件中。
11.4.4 改进的方法
考虑使用多少内存就申请多少内存的写法,无疑需要时刻记住在每一时刻数组究竟有多少元素。为此,可以把存放结果的数据类型(或数据结构)表示为:

其中“gs”用来表示数组内当前有几个元素,“kt”指向用于存放数据的连续内存空间中开始的那个“int”数据。按照这种方案可以得到下面的代码。
程序代码 11-8


这段程序的输出结果和前面那个计算100!的程序输出结果是一样的。
11.4.5 C99中的柔性数组成员(C99)
在C99中,“DASHU”这样的数据还有另外一种描述方法:

这个结构体数据类型惊人地定义了一个长度为0的数组作为数据成员,这个长度为0的数组成员必须是结构体中最后一个成员,叫做柔性数组成员(flexible array member)。一般是用来申请一块存储这个“struct ds”结构体数据和紧随其后的存储数组数据的内存空间,比如:

之后就可以通过“p->sz[i]”这样的表达式直接访问紧跟在结构体数据之后的数组内的数组元素了。本质上等价于C89中的:


但是C99中的写法更简洁、更直观一些。
顺便说一句,说明柔性数组成员时,“[]”中的0也可以不写,即以一种不完全数据类型的方式描述。
11.4.6 进一步的思考
前面的程序实现了使用多少内存就申请多少内存的目的,然而需要注意其中的ds->kt=realloc (ds->kt, sizeof (int) * (ds->gs + 1 ) );一句。realloc()函数的返回值可能与原先的“ds->kt”相同,也可能不同。也就是说所申请的内存可能是在原来申请的内存块基础上的一个自然延伸,也可能是另外寻找了一块内存,然后把原来申请的内存块的内容复制到了新的内存块中,这种复制肯定要消耗时间。这可能是这段程序的一个短板。
如果不希望这种把数据在内存中无聊地搬来搬去的事情发生,做到用一块内存就申请一块内存,但又把申请过的内存都记住以便能够随时访问,这时应该如何处理呢?
这个问题的另一种提法是,程序要求申请使用多块内存,但块数无法事先确定,这时应该如何实现?问题的难点在于,申请到的内存一般可以记录在某个指针变量中,但是由于需要申请内存的块数不定,也就无法通过事先定义变量的方法记录所有申请到的内存。
解决的办法只能是在每次申请内存空间时,都同时多申请一块记录下次申请内存空间所需要的记录空间。听起来很拗口,是吧?下面更具体地解释一下。
假设每次都需要申请“T”类型大小的空间记录“T”类型的数据,但是由于还需要留出记录下次申请的记录空间,所以每次都多申请一块数据指针大小的内存空间。这样就自然地得到一种新的数据类型:

这种包括一个指向自身数据类型指针成员的结构体类型叫做自相关结构,其特点是用指向自身类型的指针来描述自身,这有点像描述一只在努力咬另一只小猫尾巴的小猫。尽管看起来有点玄,因为多少有几分递归定义的意味,但其实它不是。C语言不容许用“struct zxg”类型来说明“struct zxg”结构体类型本身,然而容许用“struct zxg *”类型来说明“struct zxg”结构体类型。
这样一种结构几乎把C语言描述和创造数据类型的能力发挥到了极至。举例来说,仍以求100!为例,如果把记录结果的各个段统称为“duan”的话,用C语言可以这样描述它。

在代码中只需要一个指向第一段的指针就可以了。

当需要存储第一段时,只要:

就可以得到存储第一段的内存。如果需要存储第二段,那么可以通过:
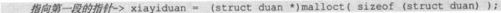
来实现。按照这种方法,可以依次读写各段的数据,只要在后一段加上一个结束的标记。这个结束的标记一般是通过把最后一段的“xiayiduan”成员赋值为0(即NULL)来表示。这样组织起来的数据结构就叫做链表(link list),每一个数据段被叫做链表的节点。
由前面的分析可以发现,只要知道指向链表开头的指针(通常称之为链表的头),就可以实现对链表中各个节点的访问。阿基米德曾说过,给他一个支点他就能撬动地球,如果见识过链表,他也许会说,给他一个链表的头他就能操纵一个链表。
链表在某些方面与数组相似,比如它们所组织的数据都是相同类型且按照一定次序排列。然而链表中的各个节点在物理上不一定是在内存中顺序排列,链表中的节点只是在逻辑上顺序排列着的,对链表节点的访问也不如数组那样直截了当,只能从链表开头一个节点一个节点地找过去。这看起来似乎有些不方便,然而对链表的另外一些操作要比对数组进行同样的操作容易得多。比如删除链表中的一个节点形成一个新的链表,是很容易的事;但是对于数组来说,删除中间的一个元素,可能需要把这个元素后面所有的元素都向前移动。向一组有序数据中插入一个数据也是如此,把数据安排为链表,代码写起来更容易、更自然。
11.4.7 用链表解决问题
程序代码11-9



