8.5 “小的变量”——位段
编程时,有些数据值的范围可能很小(比如前一小节中,存储是否为素数这个信息只需要一位就足够了),即使使用基本数据类型存储也显得非常奢侈浪费。这时可以把若干个数据紧凑地“压缩”、“打包”在一个存储空间之内。前面的位运算提供了一种操作这种数据的可能性。另一种实现这种“压缩”、“打包”的技术手段就是位段(Bit Fields)。
8.5.1 位段概述
所谓位段是指在结构体或联合体中被指定了拥有特定位数的成员,这些成员必须是整数类型。例如,考虑一个存储年、月、日的数据类型,由于年只要4位十进制数,折合成二进制需要14位;月的数值范围在1~12之间,所以只需要4位二进制数;而日的取值范围在1~31之间,所以需要5位二进制数。这时可以考虑采用下面的数据结构

“:”后的数字表示的是该成员所占的位数。这样的存储方案可以极大地节省内存。
8.5.2 如何定义位段
在结构体或联合体类型中定义位段成员的一般方法是:
数据类型[成员名称]:数据宽度;
这里的数据类型可以是“signed int”、“unsigned int”、“int”,这几种类型是标准规定的,此外C99还允许_Bool类型。有些编译器在此基础上还允许其他类型,比如char类型。
数据宽度必须是一个非负的整数类型常量表达式。这个数据宽度不允许过大。一般来说,通常以计算机的字长为限。
成员名称是可以省略的,但这样的成员在代码中是无法引用的,其作用是在数据之间起到间隔或填充的作用。这样的位段通常被叫做无名位段。
如果一个无名位段的数据宽度为0,表示的含义是下一位段需要存放到下一个“存储单元”。但这种“存储单元”究竟以什么为单位很难一概而论,通常是由编译器自行定义的,大多数情况下是指一个计算机字。
位段成员同样不能跨越“存储单元”的边界,如果遇到一个“存储单元”中剩余的位数不够存储下一个位段的情况,编译器会将这个字段安排在下一个“存储单元”之中。
8.5.3 位段的性质
位段的值(右值)可以参加运算,运算时一律转换为“signed”类型或“unsigned”类型,但是“int”类型的位段很难说是“signed”类型还是“unsigned”类型。
如果编译器规定“char”类型为“signed char”类型,那么“int”类型的位段也是“signed”类型;反之,如果编译器规定“char”类型为“unsigned char”类型,那么“int”类型的位段也是“unsigned”类型。
位段成员可以被赋值,但基本上无法把位段成员当作左值,因为无法给出位段的位置的C语言表达。位段无法作为左值参与“sizeof”、“&”等左值才能参与的运算,但可以进行“++”、“——”这种运算。
由于C语言无法表达位段的内存位置,所以也不可以构造位段数组。
可以用%d、%x、%u和%o等格式字符,以整数形式输出位段的值。但是由于位段成员无法进行一元“&”运算,所以无法直接通过调用scarf()函数输入位段的数据。
8.5.4 按二进制输出float类型数据
float类型的存储格式并不是C语言规定的,而是由ISO/IEEE Std 753-1985标准规定的。许多CPU都遵守这个标准,但必须明确的是这并不是C语言的特别要求,因为在这个标准之前,C语言就已经存在了。本小节所讨论的只是一种C语言中支持的ISO/IEEE Std 753-1985标准的float类型,这是一种很普遍的情形。
粗略地说,在ISO/IEEE Std 753-1985标准中,float浮点数首先要化成下面的形式:
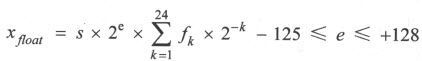
在存储时,用1位表示浮点数的正负号(s),8位存储浮点数的指数部分加上127的结果(e+127),其余23位记录浮点数的尾数(f2~f24,f1不存,但要求必须为1)。这样总共需要32bit存储一个float数据。
通过位段可以很容易地取出float浮点数的各个组成部分。
程序代码8-15

程序输出如图8-10所示

图8-10 按二进制输出float类型数据
程序的运行结果就是1.2345的二进制形式。读者可以自己验算一下,实际上真正存储的数相当于十进制的1.23450005054473876953125。
此外需要说明的是,这段代码并不具有普遍意义。因为对于不同的计算机而言,位段的存储方式是不一样的:有的计算机是从左到右,有的是从右到左。另外一个影响因素是各种计算机的字长可能并不相同。但是在具体的一种硬件条件下,总能构造出与float类型数据相匹配的一种数据结构,只是这样的代码往往不具备可移植性。
毫无疑问,使用位运算也可以完成同样的工作。但是使用位段的最大好处是,可以通过名称直接读写各个位,这可以大大增强代码的可读性。
练习
按照二进制格式输出double数据。
8.5.5 对齐等问题
无论是位段还是位运算,都已经深入到了计算机内部最基本的细节问题。这些基本细节在不同的计算机上是不同的。正是由于这点,位段和位运算的代码一般不具备可移植性。
在写位段和位运算的代码时需要特别注意两点:数据的存储方向和数据对齐问题。
有的计算机上数据可能是先写高位再写低位,而另一些计算机上则可能相反。比如0XAABBCCDDU这个数据,在有的计算机中可能被存储成地址从低到高的“AA BB CC DD”这样4个字节,而另一些计算机中可能被存储成地址从低到高的“DD CC BB AA”这样4个字节。
此外,在有的计算机上,数据对象可能可以放在内存中任何地址开始的区域中;但在另一些计算机中,数据可能被要求一律放在地址为4的倍数开始的地方。而且即使是数据可以放在任何地址开始的区域中的计算机,有时也会由于运行速度等原因,通过编译器的编译选项,要求数据都从某些特定地址开始存放,这就是所谓的对齐(Alignment)。
这样就不难理解,结构体数据类型实际在内存中所占据的空间可能并不等于其各个成员所占据的宽度之和,有时是大于各个成员尺寸之和的。类似地,联合体所占据的内存空间也不一定等于其最大成员所占据的空间,而可能是大于其最大成员所占据的内存空间。
在数据类型层面上的编程,通常不需要了解这些细节。但是一旦深入到了数据的底层,就必须对这些知识有所了解。
