9.4 指针与一维数组
9.4.1 数据指针与整数的加减法
指向数据类型的指针,可以进行加法、减法运算。但C语言对另一个运算对象有严格的限制。
数据指针可以与一个整数类型数据做加法运算。为了考察这个加法的含义,首先看一下下面代码的输出。
程序代码9-10

在作者的计算机上的输出是
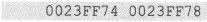
这个结果可能因为运行环境(编译器及计算机)的改变而有所不同。但有一点是确定的,那就是输出的“&i+1”的值在数值上比“&i”的值大“sizeof(int)”。这表明一个数据指针加1的含义是得到另一个同样类型的指针,这个指针刚好指向内存中后一个同类型的量。
对更一般的数据类型T,指向T类型的指针加1的含义是,得到指向内存中紧邻的后一个T类型量的指针,在数值上相当于加了sizeof(T)。如图9-9所示。

图9-9 数据指针+1的含义
加1的含义清楚了之后,加上其他整数的含义不难推之,减1的含义也就是得到指向内存中紧邻的前一个同类型量的指针。然而道理上虽然可以这样理解,但实际上C语言对指针加上或减去一个整数是有严格限制的。比如对于
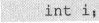
“& i+1”是有意义的运算,因为“& i+1”恰好指向“i”后面第一个“int”类型的数据,但“& i+2”是没有意义的,除非确信“& i+2”确实指向了一个“int”类型数据。只有在数组内部才可能确信如此。此外,尽管“& i+1”是有意义的运算,但是“*(& i+1)”并没有意义。
同理,除非是在数组内部,在确认一个指针减1确实指向某个数据对象的前提下,否则指针减1的运算是没有意义的。
这里,存在着指针加减法“不对称”的现象。对于一个数据对象(如前面的“i”),“&i+1”是有意义的,而“&i-1”是没有定义的。也就是说,除非通过运算得到的指针的值为0或者指向一个确实的数据对象,或者指向紧邻某个数据对象之后的一个“虚拟”的同类型的数据对象,否则这个指针是没有意义的,其行为是未定义的。
例题:编写函数,求一个一维“int”数组中元素的最大值。
假设这个数组的数组名为“a”,共“n”个元素。那么显然“&a[0]”是指向这个数组起始元素的指针,而且“&a[0]+1”、“&a[0]+2”……显然依次指向a[1]、a[2]……。这样只要把“&a[0]”和“n”作为实参传递给函数,函数就可以完成对数组的遍历。“&a[0]”和“n”的类型分别为“int *”和“unsigned”,求得的最大值为函数返回值,因此函数原型为
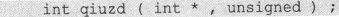
完整的代码如下。
程序代码9-11


练习
1.编写函数,求一个一维“int”数组中各元素之和。
2.如果把9.3.3分桔子问题中每人的桔子数目
11sm, 12sm, 13sm, 14sm, 15sm, 16sm
用一个数组表示,那么无论是“求最后每个人的桔子数”还是“逐步前推”的过程都可以用循环描述,代码将更为简洁。请自行完成之。
9.4.2 数据指针的减法
两个同类型的数据指针可以做减法(6),而且它们应该(7)是指向同一个数组的数组元素,或者是指向这个数组最后一个元素的下一个同类型的量。这个运算是指针与整数加减法的逆运算。所得到的结果是两个指针之间有几个这样类型的量,也就是它们所指向的数组元素的下标的差,结果的正负号表示两个指针的前后关系。
请说出下面程序的运行结果,然后再自己运行程序验证一下。
程序代码9-12

注意,这里出现了一个c[10]子表达式,但由于代码中并不涉及对c[10]的读写,只是求出指向这个char的指针,这个指针恰恰是c数组之后第一个指向char的指针,这在C代码中没有任何问题,不属于越界访问。
9.4.3 数据指针的关系运算
两个指针做“<”、“<=”、“>”、“>=”这些关系运算的前提,与两个指针做减法的前提类似最后的结果要么是0、要么是1,含义是两个指针在内存中哪个在前、哪个在后,或者是哪个不在另一个之前、哪个不在另一个之后。
两个不同类型的指针的比较及其规则或潜规则,基本上是个钻牛角尖的问题。如果有这个爱好及精力,请独立钻研C89/C99标准关于兼容性(Compatible Type)方面的阐述。事实上,在真正写代码的时候,正如记不清楚运算优先级可以加括号避开优先级问题、不同的类型之间的赋值可以通过类型转换避开转换规则一样,如果一定要在不同类型的指针之间进行关系运算,也完全可以通过类型转换避开令人烦恼的兼容性问题。毕竟,程序要解决的问题才是最重要的问题。
9.4.4 数据指针的判等运算
两个相同类型的数据指针做“==”或“!=”这两个等式运算的含义十分明显,无非是它们所指向的数据是否为同一个。
两个指针可以进行“==”、“!=”运算对操作数所要求的前提条件比做关系运算对操作数所要求的前提条件更为宽泛,具体的规则在后面将详细介绍。
9.4.5 “[]”运算
和多数运算符不同,下标运算(Subscripting Operator)“[]”的含义实际上是由另一个运算定义的。C语言规定下面两个表达式
表达式1[表达式2]与(*((表达式1)+(表达式2)))
是完全等价的。
这可能多少令人出乎意料,但事实的确如此。进一步想下去的推论可能更加令人惊奇:比如,由于+具有可交换性,如果
表达式1[表达式2]与
(*((表达式1)+(表达式2)))完全等价,那么是否可以说“Ex1[Ex2]”与“Ex2[Ex1]”
也完全等价呢?
的确如此。请看一下下面的代码。
程序代码9-13

它运行的结果会输出:

而且没有任何语法问题,你相信吗?如果你不相信,自己运行一下程序好了。
结论是,“i[0]”与“0[i]”这两个表达式是完全等价的,它们都等价于“(((i)+(0)))”,也就是“(i+0)”。如果理解这一点没有什么问题,说明你对数据指针的理解已经很有深度了。
测验:以上面的代码为背景,表达式“(i+1)[-1]*(-1)[i+1]”的值是多少?请在一分钟之内给出答案并上机验证。
此外我要郑重声明,“(i+1)[-1]+(-1)[i+1]”这种显得有几分诡异的表达式,只是为了测验你对指针概念的掌握和理解,在源程序中如果没有特别正当的理由,还是写堂堂正正、平易近人的代码为好。
如果你顺利地阅读到了这里,表明你对数据指针的概念非常清晰。指针这个令很多人感到头疼的东西,对你来说只会感到轻松愉快。甚至,下一小节的内容,你可能现在已经懂了。
9.4.6 数组名是指针
任意定义一个一维数组,比如:

从C语言数组的理论中可以知道,“d[0]”是这个数组的第一个元素,而且这个元素的类型是double类型。
从上一小节中可以得知,“d[0]”这个表达式等价于“(((d)+(0)))”,也就是等价于“d”。而“*”作为一元运算符时,它的运算对象是指针。那么数组名“d”除了是指针还能是什么呢?
显然,“d”是一个“double *”类型的指针,而且是指向这个数组起始元素的指针。这个结论非常重要,理解了这一点,指针部分就几乎不存在什么难点了。当然,这里所谓的“理解”是要能够自然而然地根据指针的概念自己得到这个结论,而不是死记硬背。如果理解这一点很吃力,请暂时不要继续读后面的内容,重读几遍前面的内容。
既然“d”是“double *”类型的指针,那么显然可以把它的值赋给一个同类型的指针变量。假设有:
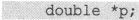
那么显然可以:
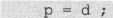
而且既然“p”与“d”类型相同,值也相同,而“d[0]”或“d”是这个数组的起始元素,那么“p[0]”或“p”显然也是同一个数据对象。
那么“p”与“d”的区别何在呢?答案是:“d”是个常量。这从“d”的意义就可以推知。
由于“d”是指向“d”数组的起始元素的指针,而“d”数组的存储空间是编译器而不是代码编写者负责安排的,那么这意味着代码书写者也不可能通过代码确定或改变起始元素在内存中的位置。这样,对于代码书写者来说,“d”就是一个不可以改变的量,也就是“常量”。
而“p”的值是可以改变的,它可以被赋值为“d”,可以被赋值为其他的值,也可以进行“++”、“——”等常量不可以进行的运算。
下面的代码演示了数组名与指针的这种等价性。
程序代码9-14


它运行的结果如图9-10所示。

图9-10 数组名是指针
注意代码中“int p=a;”的含义果对p初始化而非对p初始化。它等价于:

因为在“int p=a;”中定义的变量是“p”,“”在变量定义时只是一个类型说明符,不是运算符。
9.4.7 数组名不仅仅是指针
理解数据指针,最重要的也是最不容易弄清楚的并非指针变量,而是数组名这样遮遮掩掩着的指针常量。因为这种指针常量的类型往往并不那么明显。而如果不清楚一个数据的类型,那就表明对这个数据几乎一无所知。
数组名不但具有指针的性质,同时也具有一些本身独有的性质。
下面的代码用于演示数组名的特性。
程序代码9-15

这段程序的输出如图9-11所示。

图9-11 数组名不仅仅是指针
输出的前一项表明数组名是个指针,但是后一项“sizeof a=24”,却表明“a”同时也代表“a”数组所占据的那块内存(大小为“6*sizeof(int)”个字节),如图9-12所示。
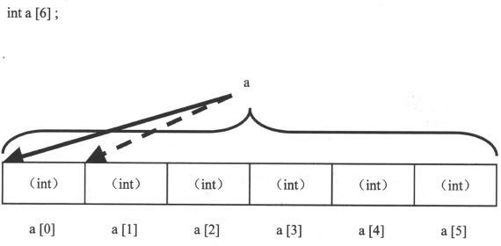
图9-12 数组名的两种含义
这个说法听起来似乎有些自相矛盾,但其实不然。所有的数据类型的变量名标识符都有两种解释:变量的值以及变量所在的内存,即右值和左值。比如下面的代码。
程序代码9-16

输出如图9-13所示。

图9-13 变量名标识符的两种解释
前一个结果中“i”表示“i”所在的那块内存中的内容所代表的值,而后一项结果中,“i”明显表示它自身所占据的那块内存。因此数组名一方面是个指针,而另一方面又代表数组所占据的内存,这并没有什么矛盾。
那么数组名的特殊性体现在哪里呢?
数组名的特殊性在于它的“值”(右值)并不是数组所占据的内存所代表的值。事实上,数组所占据的内存作为一个整体也没有“值”(右值)的含义(这点和结构体或联合体也不一样),数组名的“值”是指向数组起始元素的指针常量。另一方面,数组名作为内存(左值)看待时,也不像前面的“i”那样可以被赋值,因为在C语言中没有数组的整体赋值这样的运算。用术语来说就是,数组名不可以作为左值表达式被赋值。
那么什么时候该把数组名作为一个值什么时候该把数组名作为一块内存呢?这同样要根据具体的语境上下文确定。在C语言中,运算大体可分为两类,一类这里称为值运算,另一类这里称为内存运算。出现在“=”左边被赋值、“sizeof”运算、求指针运算“&”等都属于内存运算。在进行内存运算的时候得到的结果是与内存中的值是无关的。在进行关于内存的运算时,数组名和其他变量名一样是被作为一块内存参与运算的,运算的结果与内存中的内容是无关。而在值运算中,数组名和其他变量名一样是以“值”(右值)的意义参与运算的。对于简单的基本类型数据及结构体或联合体类型数据,值就是所在内存中二进制数代表的意义,而数组名的值则是指向起始元素的指针,因为数组作为一个整体其所占内存中的二进制数是没有什么意义的。
结论就是,当数组名被当做一个值(右值)参与运算时就是一个指针,而在参与其他内存运算时它不被作为指针而只是作为一块内存(左值)即数组所占据的内存。此外作为值,数组名是个指针常量,作为内存不可以被整体赋值。如表9-1所示,就是数组名的全部含义。
表9-1 数组名运算时的含义

后缀“++”、“——”和前缀“++”、“——”是4个有些特殊的运算,这些运算中的运算对象不但要被作为值,也要作为内存参与运算。作为值,数组名可以加1,但由于作为内存时数组名没有被赋值这种运算而且是一种常量,所以对于数组名来说,“++”、“——”运算都是非法的。
总之,从前面的分析可以得出这样的结果,“int a[6];”所定义的“a”有这样的性质:有时“a”是“int *”这样一个值,有时又表示“int [6]”这样连续存放6个“int”的内存。
9.4.8 指向数组的指针
对于数组,由于数组名也代表数组所占据的内存,所以也可以由数组名得到指向数组的指针。例如:
程序代码9-17

输出如图9-14所示。

图9-14 指向数组的指针
代码中的“&a”就是指向数组的指针,这也是一个指针常量。可以看到,在数值上它与“a”是完全相等的。这一点也不奇怪。因为一个数据指针,尽管指向的是一段内存中的所有字节,但是指针的值却只记录这段内存中第一个字节的地址。“a”与“&a”各自所指向的内存的起始位置是一样的,它们的值自然是相同的。
但是它们的类型是不同的,因而运算规则也不同。“a+1”与“&a+1”的值不同即表明了这种区别。
由于“a”是“int *”类型的指针,所以加1意味着在数值上加“sizeof(int)”。而“&a”是指向一个“int [20]”这样一个数组,因而加1意味着加上“sizeof(int [20])”,也就是加上十进制的80(十六进制的50)。
“&a”的类型用“it()[20]”描述:“”表示这是个指针类型,“int [20]”表示这个指针指向一个由20个“int”所构成的一维数组。
特别要注意的是,“”两边的“()”是必须的,这是因为“[]”的优先级比“”要高,为了强调这个类型是个指针而不是数组,必须在“*”两边加上“()”。定义与“&a”相同类型的变量时也是如此,如果希望定义一个与“&a”类型相同的指针变量,那么应该写成:

“*p”两边的“()”同样是必须的,如果误写成:

其含义是“p”是一个数组名,数组有20个元素,每个元素都是“int *”类型。
9.4.9 与数组名对应的形参
在使用数组名做实参时,前面讲过对应的形参的类型可以用不完全类型描述,实际上这种描述就是在描述一种指针类型。例如下面的代码:
程序代码9-18

与上面代码完全等价的一种写法是:
程序代码9-19


也就是说,类型描述形式为“int []”的形参“b”就是一个指针,类型为“int ”。这个“b”并不是数组名,因为数组名是常量,而形参显然是一个变量(函数调用时获得实参的值),数组名占据“元素个数元素尺寸”大小的内存,而形参“b”只占据指针类型大小的内存。
这给我们带来了一个启示,对于数组名可以做如下理解:比如“int a[1]”;,“a”的类型有时是不完全类型“int []”(“a”作为值使用时),有时是“int [1]”(“a”作为内存使用)。而前者实际上就是指针。
