13.1 简介
严格地说,预处理命令(Preprocessing Directives)并非C语言语法的组成部分,它只是对代码书写的一种约定和简化的表示方式。由于绝大多数C语言编译器都支持预处理功能,所以C标准也对预处理功能做了明确的定义和统一的规定。
编译预处理,顾名思义,是在编译之前对源代码进行的处理工作。这些处理工作在源代码中按照约定被写成预处理命令。
如图13-1所示,含有预处理命令的文本文件,即所谓源文件(Source Files),也叫做预处理文件(Preprocessing Files),需要经过预处理程序“加工”、“处理”之后才能形成编译器可以编译的不含预处理命令的翻译单元(Translation Unit)。
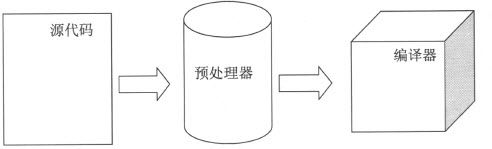
图13-1 预处理在编译前完成
C语言源程序可以由多个源文件组成。在一定条件下,部分源文件可以形成独立的预处理翻译单元(Preprocessing Translation Unit)单独进行预处理,单独编译。
从概念上来说,预处理与编译是两个独立的、一先一后进行地翻译源程序的过程,但在许多开发环境中,并不特别地区分它们,以至于很难察觉预处理过程的存在。
预处理器对源代码所做的“加工”无非是一些“替换”、“添加”、“拼接”、“删除”之类的工作。在代码中使用预处理命令的目的是提高编程的效率,增强代码的可读性、可维护性、可移植性,改善代码的结构,以便于调试及有条理地管理源程序代码。
13.1.1 一般特点
每条预处理命令逻辑上都占一行。预处理命令都以“#”开头。老式的C要求“#”在第一列,但现代的C语言预处理器容许“#”所在的行前面或后面有空白字符。
预处理不是一次性完成的,而是分为几个阶段逐步完成的。理解在预处理阶段预处理器工作的过程,可以对初始的源代码究竟被加工处理成什么样子有一个清楚的认识。
13.1.2 预处理的几个阶段
(1)首先进行的处理是把源文件中的不规范的字符替换为标准的C语言源字符。
比如,有的IDE可能使用特殊的字符表示文本中的换行符,这些将被替换为标准的源字符。
(2)删除换行字符。
比如下面的代码:
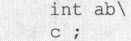
将被改为
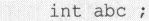
再比如
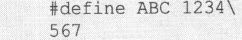
将被改写为
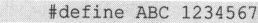
进行这样的处理,是因为预处理命令都是以行为单位的,只有先处理了这个问题,预处理器才能更容易地识别出各条预处理命令。
(3)识别预处理单词(1)(Preprocessing Tokens)并把注释部分替换为空格。
(4)开始执行预处理命令,进行宏展开,执行_Pragma(C99)运算。如果遇到#include预处理命令,则把相应的源文件包含进来,并对源文件反复做1~4步的预处理,直到源文件中没有预处理命令。
(5)把字符常量或字符串字面量中的转义序列替换为对应的字符。
(6)连接相邻的字符串字面量。比如把代码中的“"ABC" "DEF"”替换为“"ABCDEF"”。
此后,把预处理命令删除,就可以进行语法、词法分析从而转入编译阶段了。
下面详细讨论具体的编译预处理命令。
