11.1.1 实现原理
聊天机器人的实现原理是预先采集大量的问答知识,当收到用户的提问时,通过特定的算法找出与问题最贴切的答案。可以将聊天机器人的实现归纳为三步:构建问答库、索引和搜索,如图11-1所示。
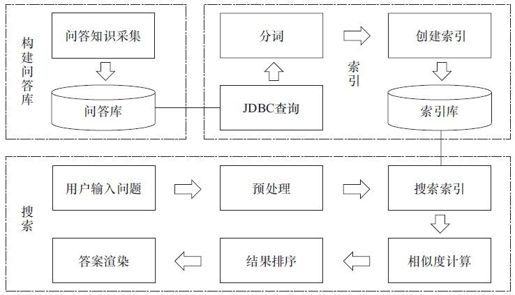
图11-1 智能聊天机器人的实现原理
问答库是聊天机器人的基础,问答库中的记录数越多、涉及知识面越广,能够回答的问题也就越多。对于企业公众账号而言,用户提的问题基本都可以通过企业客服知识库解决,企业客服知识库就是现成的问答库,为了使人机交互更加人性化,可以考虑加入一些日常寒暄语、笑话、网络流行语、百科等。构建问答库并不是一次性的工作,需要不断地迭代优化,这样才能保证机器人的回答越来越准确。如果问答库非常庞大,最好能够建立一套自学习机制,让机器人自我完善。
接下来要解决的问题是“如何根据用户的问题从问答库中找出最匹配的答案”,读者可能最先想到的是使用数据库LIKE查询,但LIKE查询存在着以下问题:
1)在问答库非常大的情况下,LIKE查询的速度非常慢。
2)LIKE查询只适用于关键词查询,不适用于自然语言查询。例如,用户的问题是“贵州的省会是哪”,问答库中有一条记录的问题是“贵州省的省会是哪个城市”,无论从字面上还是从意思上这二者都非常接近,但LIKE查询却无能为力。
3)LIKE查询无法计算内容相似度。例如,当LIKE查询返回多条问答记录时,无法按匹配度排序,也无法筛选出最匹配的答案。
很明显,LIKE查询根本不能满足要求,最好的解决方法是使用全文检索引擎,它能够根据词进行检索,无论是检索速度,还是检索结果的准确度,全文检索引擎的表现都很出色。
全文检索引擎的工作原理是扫描问答库中的每一条记录并分词建立索引,索引记录了词在每一条问答记录中出现的次数和位置,当收到用户的问题时,也会对问题进行分词,然后从索引中找出包含这些词的所有问答记录,再分别计算这些问答记录与用户问题的相似度,找出相似度最高的一条问答记录返回给用户。可以看出,全文检索引擎能够帮助我们完成图11-1中索引和检索两部分的重要工作。
在Java语言中有许多优秀的开源全文检索引擎框架可以使用,如Lucene、MG4J、Egothor、Xapian等,笔者推荐使用Lucene。
