4.4 正态概率图
对于指数分布、帕累托分布和威布尔分布,都可以通过简单的转换来判断一个连续分布是否能用于某份数据集的建模。
然而,对于正态分布就不存在这样的变换,但有一种称为正态概率图(normal probability plot)的方法。它是基于秩变换(rankit)的,所谓秩变换就是对n个服从正态分布的值排序,第k个值分布的均值就称为第k个秩变换。
习题4-9
编写一个Sample函数,生成6个服从μ=0,σ=1的正态分布的值,将其排序后返回。
编写一个Samples函数,调用1000次Sample,返回一个包含1000个列表的列表。
用zip函数处理这个列表组成的列表,可以得到6个包含1000个值的列表。计算每个列表的均值,输出结果。你得到的结果大概是这样:
{−1.2672, −0.6418, −0.2016, 0.2016, 0.6418, 1.2672}
随着调用Sample函数次数的增加,结果会收敛到这些值。
直接计算rankit是比较麻烦的,但有一些计算方法可以求出近似解。其中一个快捷且容易实现的方法如下。
- 从μ=0、σ=1的正态分布中生成一个跟你的数据集大小一样的样本。
- 将数据集中的值排序。
- 画出数据集中排序后的值跟第一步生成的随机值的散点图。
对于大数据集,这个方法效果很好。对于较小的数据集,可以通过生成m(n+1)−1个服从正态分布的值来提升效果,其中n是数据集的大小,而m是一个放大因子。然后从第m个元素开始选择第m个元素。
只要能生成所需的随机样本,该方法同样也可以用于其他的分布。
图4-7是一个简单的出生体重正态概率图。这个图的曲度表示数据集跟正态分布的差异;毕竟,在很多情况下,正态分布都是一个很好(至少是足够好)的模型。
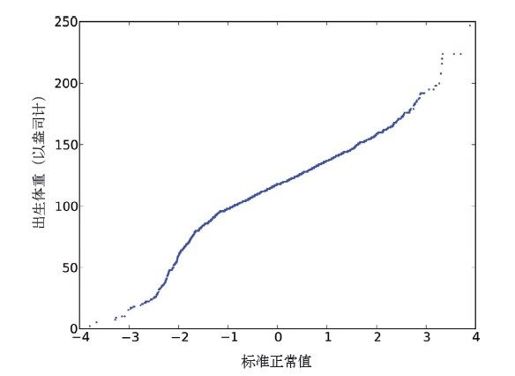
图4-7 新生儿体重正态概率图
习题4-10
编写一个NormalPlot函数,输入是一串值,生成一个正态概率图。答案在http://thinkstats.com/rankit.py。
用relay.py中的跑步速度生成正态概率图。正态分布适用于这份数据吗?答案在http://thinkstats.com/relay_normal.py。
