7.8 高效再抽样
如果读者之前学习过概率统计的知识,在看到图7-1时或许会觉得有点儿不屑一顾,因为我们花费了大量计算机资源去模拟一些本可以用很简单的理论分析就能得到的结果。
很显然,本书并没有把重心放在数学分析上面。我们更愿意通过计算机用一些貌似“愚蠢”的方法来讲述本书的内容,这样可能更容易让初学者明白这里的意义,也更容易让他们上手。所以只要我们的模拟不需要耗费很长时间,这种方式没有什么不妥。
但有时候,只需进行一些简单的分析就可以节省大量的计算,图7-1就是这样的一个例子。
我们之前是将两个分组的怀孕周期混在一起,然后再按原来每组的个数重新随机将数据分成两组,之后计算两个分组均值的差异。重复这样的过程,用这些数据构建分布。
这里,我们可以通过分析的方法直接计算均值差值的分布。假设怀孕周期服从一个分布,均值为μ,方差为σ2。我们从这个分布随机抽取n个样本,那么根据中心极限定理,样本的和渐进服从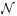 (nμ, nσ2)。
(nμ, nσ2)。
为了得到样本均值的分布,这里需要用到正态分布的一个性质:若X服从正态分布 ,那么
,那么

设a=1/n,b=0,等式两边同除以n则
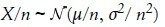
所以样本均值渐进服从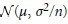 。
。
为了得到样本均值差值的分布,我们需要用到正态分布的另一个性质:若X1服从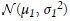 ,X2服从
,X2服从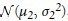 ,那么
,那么
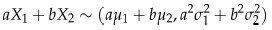
这种情况下有:
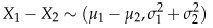
综上,可知图7-1的分布服从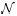 (0, fσ2),这里f=1/n+1/m。将n=4413和m=4735代入公式,得到最近的分布为
(0, fσ2),这里f=1/n+1/m。将n=4413和m=4735代入公式,得到最近的分布为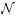 (0, 0.0032)。
(0, 0.0032)。
我们用erf.NormalCdf来计算均值差值的p值:
delta = 0.078sigma = math.sqrt(0.0032)left = erf.NormalCdf(-delta, 0.0, sigma)right = 1 - erf.NormalCdf(delta, 0.0, sigma)
计算得到的双边检验的p值为0.168,非常接近我们用重抽样的方法计算得到的结果0.166。
读者可从http://thinkstats.com/hypothesis_analytic.py下载本节所用到的代码。
