9.8 相关性和因果关系
一般说来,两个变量之间的相关关系并不能告诉我们一个变量的变化是否是由另一个变量的变化引起的;或许两个变量就没有直接的因果关系,而是因为其他原因导致二者同时发生了相同(或相反)趋势的变化;也或许就是因为偶然因素造成了它们之间的相关性。(参考http://xkcd.com/552/。)
维基百科的“Correlation does not imply causation”简要列出了可能导致两个变量产生相关性的原 因。读者可以参考http://en.wikipedia.org/wiki/Correlation_does_not_imply_causation。
那么我们怎么样才能从相关性的信号中得到因果关系的结果呢?
- 利用时间的先后关系。如果A事件在B事件之前发生,那么A就有可能是导致B的原因(但反之不成立,根据因果关系的常识是这样的)。事件发生的顺序可以帮助我们推断因果顺序,但是这并不能排除存在另外一些事件导致了A和B的发生。
利用随机性。如果我们将一个非常大的总体随机分成两部分,然后分别计算这些变量在两个子总体中的平均值。我们可以期望这些均值的差异会很小,因为中心极限定理保证了这一结果。
如果有一个变量在两个分组中有明显的差别,而其他所有的变量在两个分组里面都几乎一样,这时我们就可以排除掉一些虚假的相关性。
即使相关变量未知,这个方法也行得通,当然知道会更好,这样我们就能检查两个分组是否一致。
随机对照试验(randomized controlled trial)就是根据这些想法设置的。在这种试验中,被试者被随机地分成两组(或多组):实验组(treatment group)会接受某种干预,例如服用某种新药;而对照组(control group)则不接受这种干预,或者只接受已知效应的处理。
随机对照试验的结果在因果关系的鉴定上是最可信赖的方法之一,在循证医学中有广泛的应用。参考http://wikipedia.org/wiki/Randomized_controlled_trial。
不幸的是,随机对照试验只能用于实验研究、药物研发等少数情况。社会科学很少用到这种方法,因为这种试验可能无法进行,或者会引起伦理争端。
另外一种方式是进行自然试验(natural experiment)。在这种试验中,我们尽量控制群体在各个方面都是相似的,然后对不同的群体实施不同的处理。这里会涉及的一个问题是各个群体可能存在一些我们观测不到的差异。维基百科上给出了更详细的信息http://wikipedia.org/wiki/Natural_experiment。
在某些情况下我们能通过回归分析(regression analysis)推断出因果关系。线性最小二乘是用自变量解释因变量的简单回归。本章只讨论了有一个自变量时的情况,多个自变量的回归所用的技术与本章所用的基本相同。
本书并未涉及这些技术,有很多种方法可以控制虚假的相关性。例如,在NSFG的数据中,我们发现第一胎婴儿的体重倾向于比非第一胎婴儿的轻(参见3.6节),但是婴儿出生的体重还与母亲的年龄有关。而生第一胎婴儿的母亲的年龄倾向于比生非一胎婴儿母亲的小。
所以有可能是生第一胎婴儿的母亲更年轻导致了第一胎婴儿的体重更轻。为了控制年龄的影响,我们可以将母亲按年龄大小分组,然后比较同一个分组中第一胎婴儿的体重和非第一胎婴儿的体重。
如果这时体重的差异依然存在,那么我们就可以说这种体重上的差异跟母亲的年龄无关。但如果这时各个分组之间的体重差异消失了,那么我们得到的结论就是这种体重上的差异完全是由母亲的年龄造成的。或者,如果这些体重差异变小了,我们可以计算出母亲年龄对体重差异造成了多大的影响。
习题9-11
NSFG的数据中包含了一个记录婴儿出生时母亲年龄的变量agepreg。绘制母亲年龄和婴儿出生体重的散点图,两者之间关系如何?
用母亲年龄对婴儿出生体重进行最小二乘拟合。估计量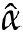 、
、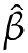 的单位是什么?是否可以用一两句话描述这个拟合结果的意义。
的单位是什么?是否可以用一两句话描述这个拟合结果的意义。
计算生头胎婴儿的母亲年龄的均值和生非头胎婴儿的母亲年龄的均值。两个分组的母亲年龄均值差异有多大才会影响到婴儿出生体重的差异?婴儿出生体重的差异有多大比例可以用分娩时母亲年龄的差异来解释?
读者可以从http://thinkstats.com/agemodel.py下载问题的答案。如果读者对多元回归感兴趣,可以浏览http://thinkstats.com/age_lm.py,这里展示了如何通过Python调用R这个统计计算软件。
