8.7 贝叶斯估计的实现
我们可以用Pmf和Cdf等表示分布的函数来表示先验分布,但是因为我们要将假设映射为概率,所以Pmf是更好的选择。
Pmf的每一个取值都代表了一个假设,例如,0.5表示假设λ=0.5。在先验分布中,所有假设的概率相等。所以我们可以这样构造先验分布:
def MakeUniformSuite(low, high, steps):hypos = [low + (high-low) * i / (steps-1.0) for i in range(steps)]pmf = Pmf.MakePmfFromList(hypos)return pmf
这个函数生成了λ先验的Pmf,Pmf所有取值构成了我们所有的假设,我们把这个假设的集合称为一个suite。所有假设有相同的概率,所以这个Pmf是一个均匀分布。
参数low和high定义了λ取值的范围,steps定义了假设的数量。
为了更新所有Hi的概率,我们输入先验Pmf和所有的观测数据(即所谓的“证据”):
def Update(suite, evidence):for hypo in suite.Values():likelihood = Likelihood(evidence, hypo)suite.Mult(hypo, likelihood)suite.Normalize()
对suite中的每一个假设,将假设的先验概率乘以在这个假设下的似然值,然后再对suite进行归一化。
在这个函数中,suite必须是一个Pmf,evidence数据可以是任意形式,只要Likelihood函数能够识别就行。
Likelihood函数的定义为:
def Likelihood(evidence, hypo):param = hypolikelihood = 1for x in evidence:likelihood *= ExpoPdf(x, param)return likelihood
在Likelihood中,我们将evidence当成是一组来自指数分布的样本,它可以计算上一节的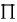 。
。
ExpoPdf计算指数分布在x处的概率密度:
def ExpoPdf(x, param):p = param * math.exp(-param * x)return p
将这些代码放在一起,我们就可以构造λ先验分布,并且计算其后验分布:
evidence = [2.675, 0.198, 1.152, 0.787, 2.717, 4.269]prior = MakeUniformSuite(0.5, 1.5, 100)posterior = prior.Copy()Update(posterior, evidence)
读者可以从这里下载本节用到的代码 http://thinkstats.com/estimate.py。
在考虑贝叶斯估计的时候,我会想象有满满一屋子的人在猜测一个我想要估计的值,在这个例子里这个值就是λ。 起初,屋里的每一个人都对自己猜测的值有一个置信度(即相信有多大的可能性猜对)。
当观测到新的证据后,所有人都根据P(E|H)对自己的置信度进行更新,这里P(E|H)指的是认为起初猜测正确的假设下,E的似然值。
通常似然函数会计算出概率,其最大值为1。因此,一开始每个人的置信度通常会下降(或保持不变),但当我们对结果进行归一化后,每个人的置信度又会上升。
所以,上述过程的净效应就是有些人的置信度上升了,有些人的下降了。而这取决于他们假设的相对似然值。
