2.1 收集数据
数据是任何可视化的精髓与核心。幸运的是,有很多途径可以找到它们,例如求助于领域内的专家,使用各种在线应用,或者靠自己的力量来收集。
2.1.1 由他人提供
这种途径非常普遍。如果你是自由设计师,或者是在大公司图形部门工作的设计师,那么就更是如此。这通常是一件好事,因为有人为你分担了数据收集这部分工作,但仍旧不能大意。数据在变成格式优美的电子表格呈现给我们之前,途中可能会出现很多错误。
在我们用电子表格来分享数据时,最常见的错误就是笔误。有没有漏掉零?这里是否应该是6而不是5?一般来说,除了带分隔符的文本文件之外,数据都是直接从来源读取,然后导入到Excel或其他电子表格程序里面,因此一些小的笔误很容易就会蒙混过关,来到我们手中。
上下文环境也需要检查。我们不必成为研究数据主题的专家,但至少应该知道数据的原始出处、收集的过程以及背后的主旨。这能帮助我们创建出更加优秀的数据图,让故事更加完整。假如你关心的是问卷调查,那么调查是何时举办的?是谁发起的?有哪些人参与?很明显,20世纪70年代的问卷调查结果和今天的必将截然不同。
2.1.2 寻找数据源
如果没有人提供数据,我们只能自己花力气寻找。从坏的一面来看,肩上的担子更重了,但从好的一面来看,找到相关度高的数据会越来越容易,而且机器可读性也会更高(也就是说,更方便输入到软件中去)。我们可以从以下方面着手。
1.搜索引擎
今天我们怎样在网上找东西?我们用Google。这几乎是顺理成章的事情,但仍然有很多人发邮件问我应该怎样才能得到某某数据、是否有什么便捷方法。我个人一般去的就是Google,偶尔也会去Wolfram|Alpha(这是一款带有计算能力的搜索引擎)。
►访问http://wolframalpha.com试用Wolfram|Alpha。如果你需要某方面的基础统计结果,这款搜索引擎会非常有帮助。
2.直接数据源
如果直接查询“数据”不能得到任何有用的结果,可以尝试求助于该领域的学者。有时候他们会在其个人网站上发布数据。如果没有,也可以翻阅他们的论文或学术报告寻求线索。你甚至还可以直接给他们发邮件,但要先确定他们确实作过相关的研究,否则只会是浪费大家的时间。
你也可以在《纽约时报》等新闻机构发布的图表中寻找数据源。这些来源通常都会以小字体附在图表的某处。如果这些地方没有,相关文章中也应该会提到。如果你在报纸或网上看到某个图表正好使用了你感兴趣的数据,这一招会很有用。搜索这个来源所属的网站,也许就能得到完整的数据。
自称是某某报纸的记者,直接向文章作者发邮件也是一条路。不过还是先试试能不能找到来源网站吧。
3.大学资源
作为一名研究生,我常常会利用学术资源,也就是大学图书馆。许多图书馆都扩充了它们的科研资源,拥有丰富的数据存档。一些统计学院系还登记了数据文件清单,其中有很多都对公众开放,虽然许多院系的数据库是为课程实验室和在籍学生的练习作业准备的。我建议访问以下资源。
□ 数据及故事图书馆(Data and Story Library,DASL,http://lib.stat.cmu.edu/DASL/)——有关数据文件以及讲述基础统计方法用法的在线图书馆,来自卡内基梅隆大学。
□ 伯克利数据实验室(Berkeley Data Lab,http://sunsite3.berkeley.edu/wikis/datalab/)——加州大学伯克利分校图书馆系统的一部分。
□ 加州大学洛杉矶分校统计数据库(UCLA Statistics Data Sets,www.stat.ucla.edu/data/)——加州大学洛杉矶分校统计学院的数据库,主要用于实验室和课程练习。
4.综合数据类应用
有关数据提供的综合性网络服务日益增多。有些网络应用提供了大型的数据文件,供人有偿或无偿下载。还有一些应用则由广大开发人员创建,通过应用编程接口(Application Programming Interface,API)获得数据。这能让我们运用某些服务应用(例如Twitter)的数据,并整合进自己的程序中去。以下是其中一些资源。
□ Freebase(www.freebase.com)——一个主要致力于提供关于人物、地点和事件的数据的社区。它在数据方面有点类似维基百科,但网站的结构更清晰。可以下载网友上传的数据文件,或者将你自己的数据进行备份。
□ Infochimps(http://infochimps.org)——数据市场,提供免费和收费的数据下载。你也可以通过他们的API来获得数据。
□ Numbrary(http://numbrary.com)——为网上的数据进行编目,主要为政府数据。
□ AggData(http://aggdata.com)——提供付费的数据集,多关注于各种零售业的地区性数据。
□ 亚马逊公用数据库(Amazon Public Data Sets,http://aws.amazon.com/publicdatasets)——更新不多,但确实有一些科研方面的大型数据集。
□ 维基百科(http://wikipedia.org)——在这个靠社区运转的百科全书中有大量HTML表格格式的小型数据集。
5.专题性数据
除了综合性的数据提供商之外,还有很多主题较单一的网站,它们提供了大量免费的数据。
以下是按部分主题进行的分类。
● 地理
只有绘制地图的软件,但却没有地理方面的数据?你走运了。有大量的形状特征文件和地区性数据资料任你调用。
□ TIGER(www.census.gov/geo/www/tiger/)——来自美国人口统计局,可能是目前最全、最详细的有关道路、铁路、河流及邮政区域等方面的数据。
□ OpenStreetMap(www.openstreetmap.org/)——最好的数据社区之一。
□ Geocommons(www.geocommons.com/)——既有数据,又有地图绘制软件。
□ Flickr Shapefiles(www.flickr.com/services/api/)——根据Flickr用户上传照片获得的地理数据。
● 体育
人们热爱体育竞技方面的统计,近几十年来的竞技数据都不难找到。你可以在《体育画报》等杂志或者各球队官方网站上找到它们,也可以去专门的数据型网站。
□ Basketball Reference(www.basketball-reference.com/)——提供每一场NBA赛事的详细数据。
□ Baseball DataBank(http://baseball-databank.org/)——可以下载到美职棒联赛完整数据的入门级网站。
□ databaseFootball(www.databasefootball.com/)——可浏览全美橄榄球联盟(NFL)所有球队、球员和赛季的数据。
● 全球
一些大的国际性组织都有关于全球性的数据,主要集中在卫生保健和发展指标等方面。不过需要筛选一下,因为大部分数据都相对稀疏。在各个国家的数据间建立统一的衡量标准也不太容易。
□ 全球卫生事实数据库(Global Health Facts,www.globalhealthfacts.org/)——世界各国医疗卫生方面的数据。
□ UNdata(http://data.un.org/)——来源众多的全球数据聚合。
□ 世界卫生组织(World Health Organization,www.who.int/research/en/)——同样是医疗卫生方面的数据,例如死亡率及平均寿命。
□ 经合组织统计(OECD Statistics,http://stats.oecd.org/)——各国经济指标数据的主要来源。
□ 世界银行(World Bank,http://data.worldbank.org/)——数百种指标数据,而且便于调用。
● 政府与政治
近年来开始强调数据的透明公开,因此许多政府机构都公布了数据,而类似阳光基金会(Sunlight Foundation)这样的组织也鼓励开发和设计人员对其加以利用。自从data.gov网站启动后,很多政府数据被集中到了一处。我们还能找到许多对政治家起到舆论监督作用的非官方机构网站。
□ 美国人口统计局(www.census.gov/)——大量的人口统计资料。
□ Data.gov(http://data.gov/)——为政府机构提供的数据进行编目。相对还比较新,但拥有很多资料来源。
□ Data.gov.uk(http://data.gov.uk/)——英国的Data.gov。
□ DataSF(http://datasf.org/)——专门提供旧金山市的相关数据。
□ NYC DataMine(http://nyc.gov/data/)——和DataSF相似,不过对应的是纽约市。
□ Follow the Money(www.followthemoney.org/)——大量工具和数据集,主要用于监督、调查美国政府的开支。
□ OpenSecrets(www.opensecrets.org/)——同样提供政府在竞选等方面花销的详细数据。
2.1.3 自动搜集数据
通常我们都能找到需要的数据,但有一个问题会很麻烦,那就是它们都不在同一个地方、同一个文件里,而是散落在多个网站、多个HTML页面中。这时候应该怎么办呢?
最简单直接、但也最耗时的方法就是访问每一个网页,把感兴趣的数据手工输入到电子表格中。如果你需要的只是几个页面,这当然没什么大不了的。
但如果有几千个页面呢?这种情况要花的时间可就长了,就算只有一百个页面也会让人难以忍受。如果这个过程能自动完成,事情就会轻松得多,而这正是“自动搜集”的含义所在。通过一点代码,程序就能自己访问大堆页面,从中抓取需要的内容并存储到我们的数据库或文本文件中。
说明 在搜集数据时,使用代码自然是最灵活的方式,但也不妨使用类似Needlebase或者Able2Extract PDF转换器这样的工具。它们的用法都非常简单,而且能为你节省时间。
1. 实例:自动搜集一个网站
要想了解如何自动搜集数据,最好的方法就是用实例来说明。假设你打算下载某个地区去年一整年的温度数据,但你找不到合适的数据来源:要么时间范围不对,要么不是你想要的地区。访问天气网站,一般都只能看到未来10天内的温度预报,而这和你想要的有很大距离。你需要的是以往的实际温度,而不是有关未来的预测。
幸运的是,Weather Underground网站提供了以往的温度。不过你每次只能看到单日的记录。
►Weather Underground的网址是http://wunderground.com。
让我们更具体一些,假设你需要查阅的是纽约州西部港市布法罗。在Weather Underground网站的搜索框里查询“BUF”,会进入布法罗市内尼亚加拉国际机场的天气页面(参见图2-1)。
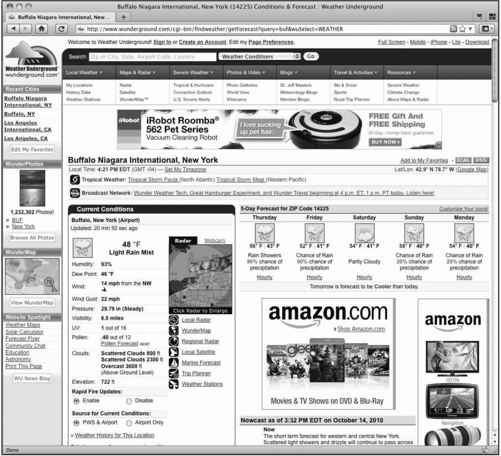
图2-1 布法罗市的气温,来自Weather Underground网站
页面的顶部提供了该地区当前的温度和其他细节,以及未来5天的天气预报。往下拉到页面的中间会看到History & Almanac(历史年鉴)面板,如图2-2所示。我们可以在下拉菜单中选择某个特定的日期。
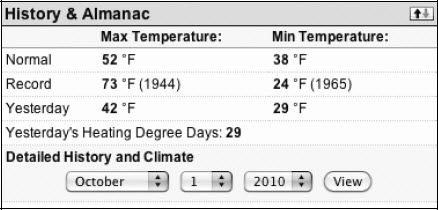
图2-2 通过下拉菜单选择日期,查看历史数据
在下拉菜单中设置2010年10月1日,单击View按钮。你会看到一个不同的视图,显示了这个日期的细节数据(参见图2-3)。
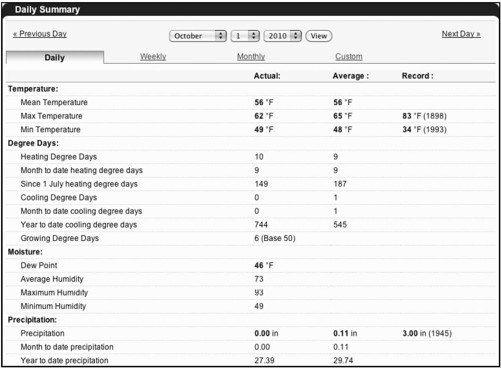
图2-3 单日的温度数据
页面上提供了温度、日度差、湿度、降雨量等众多数据,但现在你感兴趣的只是每天的最高温度。你可以在第二行第二列找到它。布法罗市在2010年10月1日的最高温度是62°F(1)。
获得这一个数据确实很简单。但要想拿到2009年里每一天的最高温度数值,应该怎么办?最不动脑筋的办法就是不断在下拉菜单那里设置日期。重复365遍,你就大功告成了。
这个过程有意思吗?当然没有。只需要一点点代码和窍门,你就能极快地加速这一过程。为了做到这一点,让我们看看编程语言Python,以及由Leonard Richardson开发的函数库Beautiful Soup。
在下面几段中读者将接触到代码。如果你曾经编过程序,阅读它们就会很轻松。即使你毫无编程经验也不用着急——每一步我都会解释清楚。很多人都把代码视为洪水猛兽、不敢越雷池一步,但请相信我,事情远没有那么可怕。哪怕只掌握一丁点编程技能,都会带来更多的可能性,从而更加自由地处理数据。准备好了吗?让我们开始吧。
首先,请确定你的计算机是否安装有合适的软件。如果你运行的是Mac OS X,那么Python应该已经预先装好。在终端Terminal(应用程序里面)输入“python”启动(参见图2-4)。
图2-4 在OS X里启动Python
如果你的计算机上安装的是Windows系统,那么可以访问Python网站,根据说明来下载和安装。(2)
►访问http://python.org来下载和安装Python。不用紧张,这并不难。
然后,你需要下载Beautiful Soup,它能帮助你方便快速地读取网页。将Beautiful Soup的Python文件(后缀名为.py)保存在你将要保存自己代码的目录中。如果你用过Python,也可以把它放到你自己的库文件路径里面,二者并无区别。
►访问www.crummy.com/software/BeautifulSoup/下载Beautiful Soup。下载的版本需要和你所用的Python版本相对应。
安装了Python并下载了Beautiful Soup之后,打开你喜欢的文本或代码编辑器(例如notepad),新建一个文件并存为get-weather-data.py。现在可以开始写代码了。
首先要做的是读取显示历史天气信息的网页。2010年10月1日的布法罗市天气数据的网页URL是:
www.wunderground.com/history/airport/KBUF/2010/10/1/DailyHistory.html?req_city=NA&req_state=NA&req_statename=NA
在这个URL里面,去掉.html后面的东西也一样能访问这个页面,所以让我们把它们去掉。你现在不用关心这些。
www.wunderground.com/history/airport/KBUF/2010/10/1/DailyHistory.html
我们发现,URL里面已经通过/2010/10/1标明了日期。由于我们要搜集2009年整年的温度数据,所以把下拉菜单的日期设置为2009年1月1日。现在的URL变成了:
www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html
所有地方都和10月1日的URL完全一致,只有标识日期的位置例外。现在是/2009/1/1。有意思。那么,如果不通过下拉菜单,怎样才能载入2009年1月2日的页面呢?很明显,只用改动URL里面的日期参数就可以了,它会变成:
www.wunderground.com/history/airport/KBUF/2009/1/2/DailyHistory.html
在浏览器里输入上面这个URL,你就会得到2009年1月2日的天气数据。所以要想获得某一天的天气数据,你要做的就是修改Weather Underground网站的URL。先记住这一点。
现在用Python来读取单个网页,通过下面一行代码先调用urllib2函数库:
- import urllib2
要在Python里读取1月1日的网页,调用urlopen函数。
- page=urllib2.urlopen("www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html")
这个操作会把该URL所指向的页面中的所有HTML都载入进来。下一步就是要从HTML中提取出我们想要的最高温度值。而Beautiful Soup会让我们很轻松地做到这一点。因此在urllib2后面我们还需要从Beautiful Soup库中调用BeautifulSoup模块:
- from BeautifulSoup import BeautifulSoup
在文件的最后,用Beautiful Soup来读取(也就是剖析)该网页。
- soup = BeautifulSoup(page)
笼统地说,这行代码是在读取HTML(其本质上也就是一个长字符串),然后以一种易于处理的方式来存储页面上的元素(如标题或图片)。
说明 Beautiful Soup提供了很多说明文档和简单实例。如果对任何地方感到困惑,可以去Beautiful Soup网站进行查阅(就是之前下载函数库的那个网址)。
比如说,如果你想找到该页面上的所有图片,可以这么用:
- images = soup.findAll('img')
这会把Weather Underground页面上所有用<img />标签显示的图片都列出来。只想要网页里的第一张图片?那就这么写:
- first_image = images[0]
只想要第二张图片?把0改成1。如果你想要第一个<img />标签中的src值,那么就这么写:
- src = first_image['src']
好了,我知道你不想要图片。你只想要一个数值:纽约州布法罗市在2009年1月1日的最高温度。那是26°F。用soup找这个数值比找图片要稍微麻烦一点,但方法是一样的。你只需要确定在findAll( )里面应该放什么就行了。我们来看一下HTML源文件。
各种主流浏览器都支持这么做。在Firefox里,可以右击页面,选择“查看页面源代码”(Page Source),当前页面的HTML就会在一个新窗口中出现,如图2-5所示。
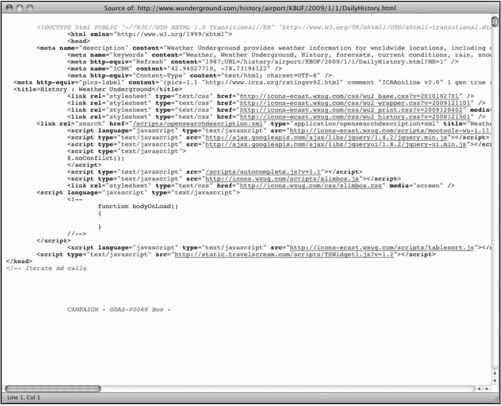
图2-5 Weather Underground页面的HTML源代码
往下拉到显示maximum temperature(最高温度)的地方,或者直接搜索该关键词,这种方法更快。找到26,它就是我们要提取的内容。
这一行有一对封闭的<span>标签,其中注明了类名是nobr。这就是关键。我们可以找到该页面中所有带有nobr类的元素。
- nobrs = soup.findAll(attrs={"class":"nobr"})
和之前一样,只要是带nobr类的元素都会被列出来。而我们感兴趣的是其中的第5个,可以通过如下方法找到:
- print nobrs[4]
这个操作带来的是整个元素,但我们只想要26这个数字。在带有nobr类的<span>标签中,还有另一个<span>标签,然后才是26。那么我们应该这样写:
- dayTemp = nobrs[4].span.string
- print dayTemp
啊哈!从HTML网页上我们搜集到了第一个数值。下一步就是在2009年的所有页面中进行搜集。要做到这一点,让我们回到最开始的URL。
www.wunderground.com/history/airport/KBUF/2009/1/1/DailyHistory.html
还记得手工修改URL来获得想要的日期吧?之前的代码是针对2009年1月1日的。如果你想要2009年1月2日的网页,只需对URL的日期部分进行相应改动即可。为了获得2009年的所有数据,需要读取每一个月(1~12)以及每个月中的每一天。以下是带有注释的脚本。把它保存到你的get-weather-data.py文件中。
- import urllib2
- from BeautifulSoup import BeautifulSoup
- # 创建/打开一个名为wunder-data.txt的文件(将会是一个以逗号分隔的文本文件)
- f = open('wunder-data.txt', 'w')
- # 按月和日进行循环访问
- for m in range(l, 13):
- for d in range(l, 32):
- # 检查该月是否已经完成
- if (m == 2 and d > 28):
- break
- elif (m in [4, 6, 9, 11] and d > 30):
- break
- # 打开wunderground.com的各个URL
- timestamp = '2009' + str(m) + str(d)
- print "Getting data for " + timestamp
- url = "http://www.wunderground.com/history/airport/KBUF/2009/" +
- str(m) + "/" + str(d) + "/DailyHistory.html"
- page = urllib2.urlopen(url)
- # 从页面上获取温度值
- soup = BeautifulSoup(page)
- # dayTemp = soup.body.nobr.b.string
- dayTemp = soup.findAll(attrs={"class":"nobr"})[5].span.string
- # 将月份格式化为时间戳记
- if len(str(m)) < 2:
- mStamp = '0' + str(m)
- else:
- mStamp = str(m)
- # 将日期格式化为时间戳记
- if len(str(d)) < 2:
- dStamp = '0' + str(d)
- else:
- dStamp = str(d)
- # 创建时间戳记
- timestamp = '2009' + mStamp + dStamp
- # 将时间戳记和温度写入到文本文件中
- f.write(timestamp + ',' + dayTemp + '\n')
- # 数据获取结束!关闭文件。
- f.close( )
你应该认得前两行代码,它们调用了必需的库文件urllib2和BeautifulSoup。
- import urllib2
- from BeautifulSoup import BeautifulSoup
在此之后,用open( )函数新建一个名为wunder-data.txt的文本文件,并赋予其写权限。你搜集的所有数据都会被存储到这个文本文件里,和你的脚本文件处于同一个文件目录。
- # 创建/打开一个名为wunder-data.txt的文件(将会是一个以逗号分隔的文本文件)
- f = open('wunder-data.txt', 'w')
下面的代码中使用了一个for循环,告诉计算机要读取每个月的数据。月份数字存储在m变量中。其后的循环告诉计算机读取每个月中的每一天。日期数字储存在d变量中。
- # 按月和日进行循环访问
- for m in range(1, 13):
- for d in range(1, 32):
►查阅Python说明,了解更多循环的工作原理:http://docs.python.org/reference/compound_stmts.html。
注意,我们使用了range(1,32)让程序按天数循环。这表示你可以遍历1~31。然而并不是每一个月都有31天。2月只有28天,而4月、6月、9月和11月都只有30天。没有4月31日的温度数据,因为这一天根本就不存在。所以需要根据月份采取相应的行动。如果当前是2月,在日期超过28的时候就应该中断(break)并前进到下个月。如果你打算搜集多个年份的数据,还需要添加if声明以便考虑闰年的情况。
与之类似,如果不是2月而是4月、6月、9月或11月,在当前日期超过30的时候也应该中断(break)并前进到下个月。
- # 检查该月是否已经完成
- if (m == 2 and d > 28):
- break
- elif (m in [4, 6, 9, 11] and d > 30):
- break
下面几行代码也应该很眼熟。我们曾通过它们从Weather Underground网站搜集过单个页面的数据。唯一的区别在于URL中的月份和日期变量,这两个地方不应该是静态的。调用urllib2库来载入页面,调用Beautiful Soup来分析页面中的内容,然后通过查找第5个nobr类来提取最高温度值。
- # 打开wunderground.com的各个URL
- url = "http://www.wunderground.com/history/airport/KBUF/2009/" +
- str(m) + "/" + str(d) + "/DailyHistory.html"
- page = urllib2.urlopen(url)
- # 从页面上获取温度值
- soup = BeautifulSoup(page)
- # dayTemp = soup.body.nobr.b.string
- dayTemp = soup.findAll(attrs={"class":"nobr"})[5].span.string
剩下的一块代码将根据年份、月份和日期来组成时间戳记。时间戳记的格式是yyyymmdd。当然,任何其他格式也都没问题。
- # 将月份格式化为时间戳记
- if len(str(m)) < 2:
- mStamp = '0' + str(m)
- else:
- mStamp = str(m)
- # 将日期格式化为时间戳记
- if len(str(d)) < 2:
- dStamp = '0' + str(d)
- else:
- dStamp = str(d)
- # 创建时间戳记
- timestamp = '2009' + mStamp + dStamp
最后,温度值和时间戳记都会通过write( )函数写入到wunder-data.txt文件中去。
- # 将时间戳记和温度写入到文本文件中
- f.write(timestamp + ',' + dayTemp + '\n')
在所有月份和日期都获取完成后,使用close( )来关闭wunder-data.txt文件。
- # 数据获取结束!关闭文件
- f.close( )
剩下的事情就是运行代码了,在终端输入:
- $ python get-weather-data.py
运行需要一段时间,请保持耐心。计算机在这个过程中实际上读取了365个网页,以对应2009年的每一天。在脚本运行结束后在你的工作路径下会出现一个名为wunder-data.txt的文件。打开它就会看到你想要的数据,以逗号分隔。第一列是时间戳记,第二列是温度值。看上去应该类似图2-6中的样子。
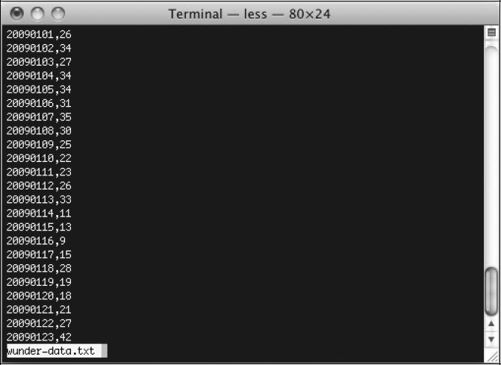
图2-6 搜集到的整整一年的温度数据
2.案例归纳
我们从Weather Underground网站上搜集到了天气数据,而对于其他数据来源,也可以借鉴这个过程。典型的自动搜集数据包括三个步骤:
(1)找出规律;
(2)循环;
(3)存储数据。
在上面这个例子中,我们必须找到两个规律。第一个在URL里面,第二个则是在网页中找到具体的温度值。要想载入2009年不同日期的网页,需要改动URL中的月份和日期部分。而温度值则位于HTML中的第5个nobr类标签中。如果在URL中没有明显的规律,可以换个角度想想怎样得到所有这些页面的URL。也许可以看一下网站地图,或者通过搜索引擎查阅网站目录。无论如何,你必须知道所有数据页面的URL。
在找到规律之后,我们要进行循环处理。也就是说,需要通过程序访问所有的页面,载入这些页面,然后读取并分析。例子中我们用到的是Beautiful Soup,它能让Python更容易地分析XML和HTML。如果你选择的是其他编程语言,也应该有类似的函数库。
最后,我们需要把数据存储在某个地方。最简单的办法是把数据存储为纯文本文件,以逗号作为分隔符,但如果你有自己的数据库,也可以存到那里面。
有些网页中显示的数据是通过JavaScript来调用的,这种情况就会麻烦一些,但整个搜集的过程还是一样。
