6.4 对照和比较
通常来说,将多个分布同时进行比较会带来更大帮助,而不是只考虑平均数、中位数和众数。毕竟这些摘要性质的统计只是对大局的一种“描述符”,它们讲述的只是故事的片段。
比如说,我可以告诉你2008年的全球平均出生率是每1千人口中有19.98个婴儿出生,而在1960年的平均数则是32.87。所以2008年的出生率要比1960年低39%。但这些只能告诉你整个分布的总体发生了什么。是否大多数国家的出生率其实并无显著变化,只是有少数国家在1960年的出生率过高,从而拉动了平均值?过去这几十年来出生率间的差距到底是在持续增加还是持续减少?
我们可以通过多种途径来进行比较。我们可以摒弃可视化、只靠分析来得出结果(我读研时花了一整年时间学习各种统计方法,而它们也只是冰山一角)。或者我们也可以利用可视化来达到同样的效果。这种方法得到的结果虽然不如周密的统计分析那么精确,但它们足以帮助我们在任何方面作出明智的决策。很明显,更多人都会选择可视化途径,这也是我写这本书的目的,不是吗?
多个分布图表
到目前为止我们只专注于一个分布情况,也就是2008年的出生率。但如果查看一下数据源文件或者R中的数据帧,我们就会发现其中提供了1960—2008年每年的出生率数据。唔,当然了,无论你看不看,它们都在那里。正如我之前所提到的,全球出生率呈现显著的下降趋势,但整个分布到底是如何变化的呢?
现在让我们直接为每一年都创建一个直方图,然后把它们以矩阵的形式进行组织。这种设计思路和本章一开始的散点图矩阵非常相似。
1.创建直方图矩阵
R中的lattice工具包让我们只需一行代码就能创建出一整套直方图,但有一个小问题:我们必须以这个函数接受的格式来向它传递数据。以下是R在一开始载入的文本文件的片段。
- Country,1690,1961,1962,1963...
- Aruba,36.4,35.179,33.863,32.459...
- Afghanistan,52.201,52.206,52.208,52.204...
- ...
可以看出,每一个国家都有一行数据。第一列是国家的名称,然后每一年都占有一列,因此算上标头共有50列234行数据。但我们需要这些数据按两列来呈现:一列是年份,另一列是出生率。这里并不需要国家的名称,因此数据的头几行看起来应该是这个样子:
- year,rate
- 1960,36.4
- 1961,35.179
- 1962,33.863
- 1963,32.459
- 1964,30.994
- 1965,29.513
- ...
比较一下这两个片段,不难发现在第二个片段中的数值对应的是前一个片段中的国家阿鲁巴(Aruba,加勒比海岛国)。所以每一个国家每一年的出生率都应占据一行,这样就会需要9870行数据(算上标头)。
那么怎样才能让数据变成我们想要的格式呢?还记得在第2章中用过的Python吗?我们在Python里载入CSV文件,然后循环处理其中的每一行,输出为我们想要的数据格式。现在也可以这么干。用你喜欢的文本编辑器新建一个文本文件并存为transform-birth-rate.py。请确保它的存放路径与birth-rate.csv相同。然后输入以下代码:
- import csv
- reader = csv.reader(open('birth-rate.csv', 'r'), delimiter=",")
- rows_so_far = 0
- print 'year,rate'
- for row in reader:
- if rows_so_far == 0:
- header = row
- rows_so_far += 1
- else:
- for i in range(len(row)):
- if i > 0 and row[i]:
- print header[i] + ',' + row[i]
- rows_so_far += 1
以上代码看上去应该很眼熟,不过现在让我们拆开来分析。我们导入了csv工具包,接着载入birth-rate.csv。然后输出标头,循环处理每一行每一列,从而让代码把数据输出为我们想要的格式。在控制台中运行以上脚本,并将输出保存为一个名为birth-rate-yearly.csv的新CSV文件。
- python transform-birth-rate.py > birth-rate-yearly.csv
提示 如果你希望将全部代码都写在R里,可以试试Hadley Wickham的reshape工具包。它能帮助你把数据帧改为需要的格式。
很好。现在用histogram( )来创建矩阵:让我们回到R,用read.csv( )载入新的数据文件。如果你刚才省略了改变数据格式那一步,我这里提供了一份修改后的数据文件,你可以直接通过URL来载入它。
- birth_yearly <-
- read.csv("http://datasets.flowingdata.com/birth-rate-yearly.csv")
现在把数据插入到histogram( )里面,生成一个10×5的矩阵,显示按年份划分的出生率。输出结果应如图6-33所示。
- histogram(~ rate | year, data=birth_yearly, layout=c(10,5))

图6-33 默认生成的直方图矩阵
效果不赖,但还有改善的余地。首先,有一个异常值出现在右侧很远的位置,导致其他所有柱形都被挤到了左侧。其次,矩阵的每一个单元中都有根橙色的竖线,随着年份的增加它会从左往右移动,但如果明确标出年份数字,反而会更加便于理解。最后一点(由于没有年份标签所以很难看出),这些直方图的顺序并不太合适。第一个年份,也就是1960年,出现在左下角,1969年在右下角。1960年那个单元的上方是1970年。也就是说,年代顺序是从下往上、从左至右排列的。这让人感觉很别扭。
要想找出那个异常值,让我们再次对birth_yearly使用summary( )函数。
- year rate
- Min. :1960 Min. :6.90
- 1st Qu.:1973 1st Qu.:18.06
- Median :1986 Median :29.61
- Mean :1985 Mean :29.94
- 3rd Qu.:1997 3rd Qu.:41.91
- Max. :2008 Max. :132.00
最大值是132。这看起来有些离谱,因为出生率几乎没有接近100的。是哪里出了问题?我们发现帕劳(西太平洋岛国)在1999年的出生率被记录为132。这很可能是一个笔误,因为帕劳的出生率在1999年前后都从未超过20。很可能应该是13.2,但我们也不能妄下结论,最好多加研究。就目前来说,让我们先移除这个数值。
- birth_yearly.new <- birth_yearly[birth_yearly$rate < 132,]
再来看看年份标签。如果标签的值是以数字存储的,那么lattice函数会自动用一根橙色竖线来指示数值。然而,如果标签处是字符,那么函数就会使用字符串,所以现在让我们来调整一下:
- birth_yearly.new$year <- as.character(birth_yearly.new$year)
我们还需要调整顺序。首先还是得创建直方图矩阵,然后将其存储为一个变量。
- h <- histogram(~ rate | year, data=birth_yearly.new, layout=c(10,5))
然后用update( )函数来改变直方图的顺序。
- update(h, index.cond=list(c(41:50, 31:40, 21:30, 11:20, 1:10)))
这样就调转了所有行的顺序。结果如图6-34所示,我们得到了一个标签清晰的直方图矩阵,而且由于移除了错误值,分布呈现得更加明确。此外,直方图的排列更具有逻辑性,读者可以从左至右、从上到下地阅读。视线从每一行中某个单元直接往下移动,就能看到分布在10年后的变化。

图6-34 修改后的直方图矩阵
现在的整个布局已经很不错了。如果你希望在Illustrator里继续美化图表,可以缩小标签的字体、调整边框和填充色,以及一些整体上的清理,结果如图6-35所示。这样一来可读性会得到进一步增强。要想让图表的意思更加明确,并且讲述故事的来龙去脉,你还可以添加适当的文字说明、数据来源,并且指出全球出生率的分布是如何逐渐往左(低出生率)偏移的。对于单独的图表来说这可能有点复杂,因此你需要提供充分的上下文背景,以便于读者完全理解数据的意义。
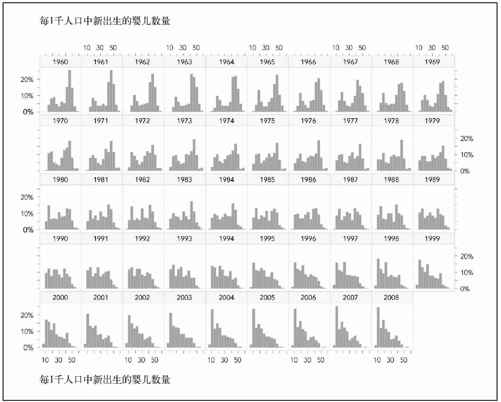
图6-35 在Illustrator中完善后的直方图矩阵
解决问题并不是只有这一种途径。我们还可以用Processing、Protovis、PHP或者任何能绘制柱形的工具来创建同样的直方图矩阵。甚至在R里也有多种方法可以绘制和上图一样的矩阵。比如说,我为FlowingData绘制了一幅有关2002—2009年家庭电视尺寸的分布变化图,如图6-36所示。
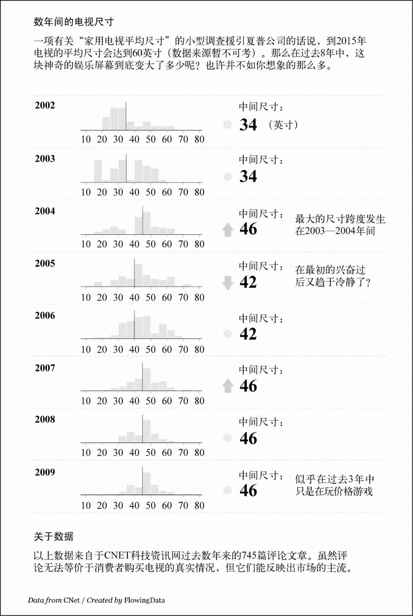
图6-36 数年间电视尺寸的分布
这段代码和我们之前写的有些出入,但总体逻辑是相似的:载入数据,过滤对异常值,然后画出一堆直方图。区别在于我没有用到lattice工具包中的histogram( )函数。图表的布局用到了R中常见于全局参数设置的par( )函数,而绘制直方图则用到了hist( )函数。
- # Load data
- tvs <- read.table('http://datasets.flowingdata.com/tv_sizes.txt',
- sep="\t", header=TRUE)
- # Filter outliers
- tvs <- tvs[tvs$size < 80, ]
- tvs <- tvs[tvs$size > 10, ]
- # Set breaks for histograms
- breaks = seq(10, 80, by=5)
- # Set the layout
- par(mfrow=c(4, 2))
- # Draw histograms, one by one
- hist(tvs[tvs$year == 2009,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2008,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2007,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2006,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2005,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2004,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2003,]$size, breaks=breaks)
- hist(tvs[tvs$year == 2002,]$size, breaks=breaks)
这段代码的输出如图6-37所示。图中有4行2列,这是由par( )里面的mfrow参数来指定的。而在最终发布的图表里,我把它们放在一列显示。重要的是,用R可以让我避免在Illustrator或者Excel里面输入一大堆数据来手动生成8个图表。
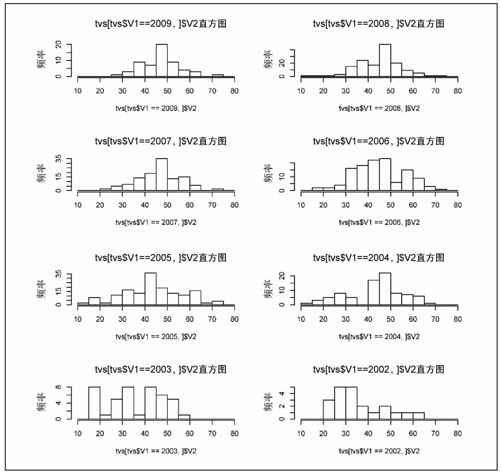
图6-37 直方图的网格布局
2.系列组图
将大量小图表归于一起的技巧通常被称作“系列组图”(small multiples)。这种图表方便读者多个群组和分类之间及其内部比较。此外,将有规律的多个图表整合到一起,还会显得更有组织性。
比如说,我曾经在烂番茄(Rotten Tomatoes)网站上浏览过很多“三部曲”系列影片的评分。可能有些读者不太熟悉烂番茄网,这个网站会聚合各种影片评论,并且将其划分为“好评”和“差评”。如果有60%以上的评论者声称他们喜欢某部影片,那么该影片就会被标记为“新鲜”。反之,自然就是“烂”了。我希望了解各大系列影片的续集和其首部曲相比,到底是更“新鲜”还是更“烂”。结论并不乐观,如图6-38所示。大结局得到的均分要比首部曲得到的均分低37%。换句话说,绝大多数首部曲都很“新鲜”,而绝大多数大结局都很“烂”。
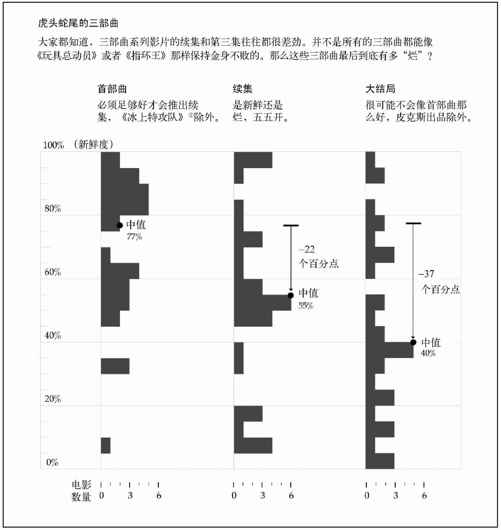
图6-38 三部曲系列影片从首部曲到大结局的评价趋势
① 《冰河特工队》(The Mighty Ducks)是迪士尼于1992、1994、1996年推出的三部曲系列影片,一气呵成、前后呼应,尤其是那些小童星从小演到大,是迪士尼非常成功的运动题材系列影片。
实际上,这就是对3个直方图进行翻转得到的结果。图6-39显示了R中原始生成的直方图。我只是在Illustrator里面对它们进行了一些美化。
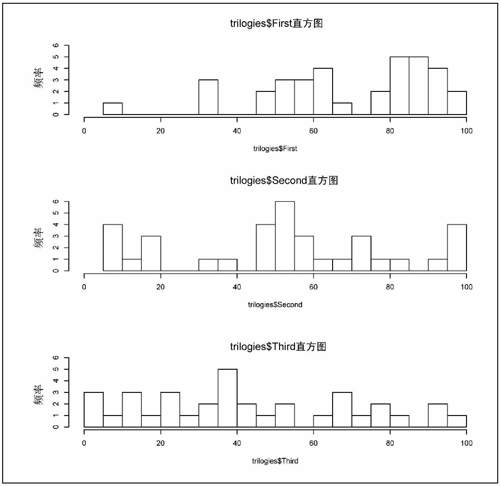
图6-39 原始的三部曲直方图
FlowingData的读者自然能够理解这些图表的意思——他们天生都对数据敏感。然而,这幅图表后来被IMDB,也就是网络电影资料库(Internet Movie Database)引用了。IMDB的受众群体要更为广泛,而且根据他们的评论来看,对数据不够敏感的读者在解读这些分布时非常吃力。
不过,图表的第二部分(见图6-40)看上去就容易理解多了。它运用了系列组图的概念,每一个柱形都代表一部电影的评分。红色的柱形代表“烂”,而绿色代表“新鲜”。

图6-40 三部曲评分的系列组图
可能有些人在想这是怎样做到的。它只是一大堆柱形图,我们可以像之前那样修改mfrow参数,并且用到plot( )或者polygon( )函数。不过我在这里用的是Illustrator里面的柱形图工具(Column Graph tool),因为当时它正好打开着。
在发表这幅图后,我学到了几件事情。首先也是最重要的是,集合与分布并不是每个人都能轻易理解的概念,因此我们需要尽力解释清楚,在讲故事时要倍加小心。我学到的第二件事情,就是人们忠于自己喜爱的电影,如果你对他们的挚爱横加批评,他们会很较真。
