8.3 地区
在地图上绘制圆点为我们带来的价值基本上就是以上这些,因为它们只能代表单个的位置。县、州、国和洲都是带有边界线的完整区域,而且地理数据往往都是通过这种方式生成的。比如说,与单个病人或医院的数据相比,找到某个州或某个国家的居民卫生数据通常都会容易得多。很多时候这些数据都是私人生成的,但聚集起来后,数据就很容易被公开。不管怎么说,我们经常会按这种方式来使用自己手中的空间数据,所以现在看看怎样对它们进行可视化。
根据数据来着色
等值区域图(choropleth map)是最为常见的绘制区域性数据地图的方式。根据某种度量方法,各个地区会根据我们定义的颜色标尺进行着色,如图8-11所示。地区和位置都已经定义好了,所以我们的工作就是选择使用一种合适的颜色标尺。
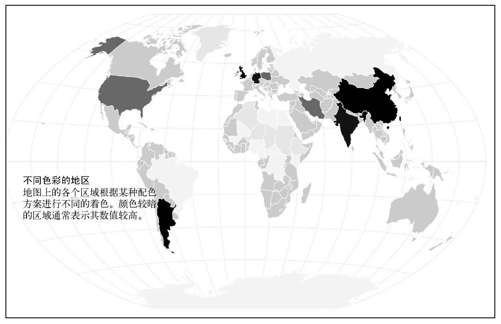
图8-11 等值区域图的基本框架
我们在上一章曾接触过Cynthia Brewer开发的ColorBrewer,它非常方便于选择颜色,对调色板的设计也有很大帮助。如果我们的数据是延续性的,可能就会希望有类似延续性的颜色标尺,在一个色度(或者多个相似的色度)内由浅到深进行渐变,如图8-12所示。

图8-12 ColorBrewer实现的连续性配色
如果数据代表的是正反两种品质,例如好和坏、高于或低于临界值,那么相互背离的配色方案可能会更为合适,如图8-13所示。
图8-13 ColorBrewer实现的相互背离的配色
最后,如果数据分属于不同的类,那么就需要为每一类填充唯一的颜色(见图8-14)。
图8-14 ColorBrewer实现的定性配色(另见彩插图8-14)
当我们有了自己的配色方案之后,还有两件事情要做。第一件是决定如何让选择的颜色与数据的范围相适配,第二件是根据我们的选择为每个地区安排颜色。在下面的例子中,我们可以用Python和可缩放矢量图形(Scalable Vector Graphics,SVG)来完成以上两件事情。
1.绘制县的地图
美国劳工统计局每个月都会提供县级别的失业率数据。我们可以从其官方网站上下载从数年前到最近的数据。不过,劳工统计局提供的数据表现形式有点过时了,操作也很麻烦,所以为了简单起见(也为了避免其网站改版),大家可以在http://book.flowingdata.com/ch08/regions/unemployment-aug2010.txt下载数据。数据共有6列,第一列是劳工统计局专用的编码,其后两列是唯一的ID,用于标识各个县。第4列和第5列分别是各县的名称以及月份,最后一列则是各郡县失业人数的估算百分比。在本例中,我们只用关心县的ID(也就是联邦资料处理标准码,FIPS codes)和失业率即可。
现在来画地图。在上一章中,我们是用R生成的底层地图,这次我们可以试试用Python和SVG来做到这一点。前者用于处理数据,而后者用于绘制地图。不过,我们也不需要完全从头开始。从维基共享资源(Wikimedia Commons)可以获得一张空白的地图,地址是http://commons.wikimedia.org/wiki/File:USA_Counties_with_FIPS_and_names.svg,如图8-15所示。该页面链向4种尺寸的PNG格式地图和1个SVG格式地图,我们要的是SVG格式。下载SVG文件并存储为counties.svg,目录与你保存失业率数据的文件夹相同。
图8-15 来自维基共享资源的空白美国县地图
如果你不熟悉SVG,只需要知道它实际上就是一种XML文件。它是带有标签的文本,我们可以在文本编辑器里对其进行编辑,就像编辑HTML文件那样。网页浏览器或者图片浏览器会读取XML,而XML告诉浏览器显示什么内容,例如绘制什么形状、使用什么颜色。
我们可以验证这一点。用文本编辑器打开这个地图SVG文件,看看你将要面对的是什么。其中大部分都是SVG的声明以及一些套话,现在完全不需要关心。
往下滚动页面,可以看到一些<path>标签,如图8-16所示。在一个标签内的所有数字就指定了县的边界。我们现在不要动它们。我们感兴趣的是修改每个县的填充色,以便适配其对应的失业率。要做到这一点,必须修改这些路径的样式。
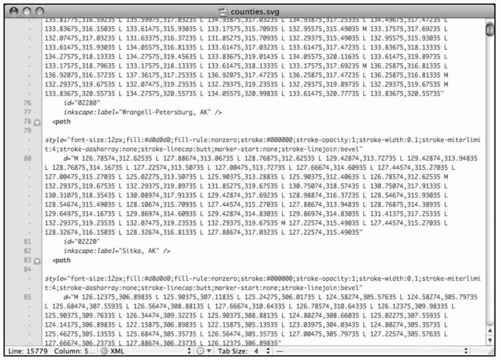
图8-16 SVG文件中指定的路径
提示 SVG文件就是XML文件,很容易在文本编辑器里面修改。这也意味着我们可以解析SVG代码,通过程序来修改。
注意到每个<path>都是以style开始的了吗?那些写过CSS的人可能立刻就认出来了。其中有一个fill参数,其后跟着十六进制的颜色值,所以如果我们在SVG文件里修改它们,就能在输出的图片中调整颜色了。你可以手工去一个个地修改,但全美国有3000多个县。这要花的时间可就长了。现在让我们找找老朋友Python工具包Beautiful Soup,它能让XML和HTML的解析变得相对容易一些。
在存储SVG地图和失业率数据的文件夹里新建一个空白文件,并改名为colorize_svg.py。我们需要导入CSV数据文件,然后用Beautiful Soup进行解析,所以第一步先载入需要的工具包。
- import csv
- from BeautifulSoup import BeautifulSoup
然后打开CSV文件并存储之,以便我们用csv.reader( )循环处理每一行。请注意,在open( )函数里面的"r"只是表示我们希望打开文件并读取(read)里面的内容,而不是往里面写入更多新的行。
- reader = csv.reader(open('unemployment-aug2010.txt', 'r'), delimiter=",")
现在再载入那个空白的SVG县地图。
- svg = open('counties.svg', 'r').read( )
太好了,我们已经载入了创建等值区域图所需要的所有东西。现在的挑战在于你得把数据和SVG连接起来。这两者之间的共性是什么?给你一个提示:它肯定和每个县的唯一ID有关,我在之前已经提过。如果你猜的是FIPS码,那么恭喜你答对了。
SVG文件中的每一条路径都有唯一的ID,正好是其所属州及所属县的FIPS码的混合。而在失业率数据的每一行里也有州和县的FIPS码,不过是分开的。比如说,阿拉巴马州奥拓加(Autauga)县的州FIPS码是01,县FIPS码是001。而SVG中该路径的ID则是二者的结合:01001。
我们需要存储失业率数据,以便通过FIPS码来检索每一个县的失业率,就和循环处理每一条路径一样。如果大家有点糊涂了,先跟着我的思路,到后面看到实际代码就会更加清楚了。这里主要是说FIPS码就是我们SVG和CSV之间的纽带,对这一点可以加以利用。
提示 SVG文件中的路径(尤其是地理路径)通常都会有唯一的ID。这种ID不一定是FIPS码,但规则是一样的。
要想存储失业率数据,便于后面通过FIPS码读取,我们要用到Python中的“字典”这一概念。它能让我们通过关键词来存储和检索数值。在本例中,我们的关键词就是相结合后的州和县的FIPS码,如以下代码所示。
- unemployment = { }
- min_value = 100; max_value = 0
- for row in reader:
- try:
- full_fips = row[1] + row[2]
- rate = float( row[8].strip( ) )
- unemployment[full_fips] = rate
- except:
- pass
下面用Beautiful Soup来解析SVG文件。绝大多数标签都有一个开始标签和一个结束标签,但也有一些自关闭标签,这些需要专门指定。之后用findAll( )函数来检索地图中的所有路径。
- soup = BeautifulSoup(svg, selfClosingTags=['defs', 'sodipodi:namedview'])
- paths = soup.findAll('path')
然后把颜色(我从ColorBrewer得到的)存储进一个Python列表。这是一个延续性的配色方案,带有多个色度,由紫色渐到红色。
- colors = ["#F1EEF6", "#D4B9DA", "#C994C7", "#DF65B0", "#DD1C77", "#980043"]
我们开始接近高潮了。正如我刚才所说,我们要修改SVG文件里每一条路径的style属性。现在我们只对填充色感兴趣,但为了让事情更容易点,我们可以替换整个style而不是仅仅只替换掉填充色。我将位于"stroke"后面的十六进制数值改成了#ffffff(也就是白色)。这样一来边界线就由当前的灰色变成了白色。
- path_style = 'font-size:12px;fill-rule:nonzero;stroke:#fffff;stroke-
- opacity:1;stroke-width:0.1;stroke-miterlimit:4;stroke-
- dasharray:none;stroke-linecap:butt;marker-start:none;stroke-
- linejoin:bevel;fill:'
与此同时,我还把fill挪到了代码末端,并且把它的值留为空。因为这一部分需要根据各个县的失业率来定。
终于,我们要开始修改颜色了。我们可以循环处理每一条路径(州边界线和夏威夷、阿拉斯加的分隔线之外)及其对应的颜色。如果失业率高于10%,就用较深的颜色;如果低于2,则用最浅的颜色。
- for p in paths:
- if p['id'] not in ["State_Lines", "separator"]:
- # pass
- try:
- rate = unemployment[p['id']]
- except:
- continue
- if rate > 10:
- color_class = 5
- elif rate > 8:
- color_class = 4
- elif rate > 6:
- color_class = 3
- elif rate > 4:
- color_class = 2
- elif rate > 2:
- color_class = 1
- else:
- color_class = 0
- color = colors[color_class]
- p['style'] = path_style + color
- if rate > 10:
- color_class = 5
- elif rate > 8:
- color_class = 4
- elif rate > 6:
- color_class = 3
- elif rate > 4:
- color_class = 2
- elif rate > 2:
- color_class = 1
- else:
- color_class = 0
- color = colors[color_class]
- p['style'] = path_style + color
最后一步是用prettify( )来输出SVG文件。该函数可以把我们的soup转化为一个浏览器能够理解的字符串。
- print soup.prettify( )
►大家可以在这里获得完整的脚本:http://book.flowingdata.com/ch08/regions/colorize_svg.py.txt。
现在还需要做的就是运行Python脚本,并将输出存储为一个新的SVG文件,名字可以叫做colored_map.svg(见图8-17)。
图8-17 运行Python脚本并将输出存储为一个新的SVG文件
在Illustrator或者Firefox、Safari、Chrome等现代浏览器中打开我们新鲜热辣的等值区域图,就能看到辛苦劳动的成果了,如图8-18所示。现在很容易看出来在2010年8月美国有哪些地方的失业率较高。很明显,西海岸大部分地区和东南部许多地区的失业率较高,阿拉斯加和密歇根的形势也很严峻。而美国中部大多数县的失业率相对较低。
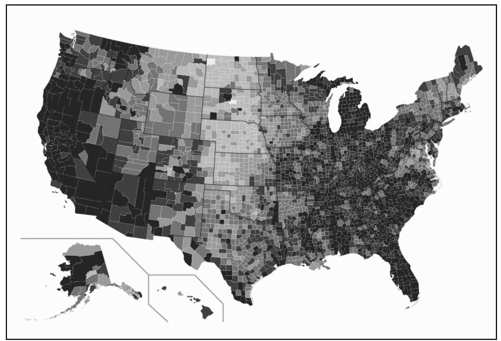
图8-18 显示失业率的等值区域图
困难的部分已经过去,我们现在可以尽情对地图进行视觉上的优化了。在Illustrator中打开SVG文件,修改边框颜色和宽度、添加注释,绘制出一幅完整的图表以便更多人能够理解。(提示:图例还是必不可少的。)
最棒的是,这段代码是可重用的,我们可以将其应用到其他使用FIPS码的数据集中去。或者对于同样的数据集,我们还可以自由改变配色方案,从而设计出适合自己数据风格的地图。
根据手中的数据,我们还可以修改临界值来调整每个地区的颜色。之前的例子中,我们使用了相等的临界值,各个地区按6种色值进行着色,每2个百分比一个等级。失业率超过10%的所有县都归为同一个等级,然后失业率在8%和10%之间的是一个等级,之后是6%~8%,依此类推。另一种定义临界值的常用方法就是利用四分位数,也就是只有四种颜色,每一种颜色代表地区总数的1/4。
比如说,对于这些失业率的下四分点、中四分点和上四分点分别是6.9%、8.7%和10.8%。这表示有1/4的县失业率低于6.9%、1/4的县失业率在6.9%和8.7%之间、1/4的县失业率在8.7%和10.8%之间,最后1/4的县失业率高于10.8%。要想做到这一点,可以按以下代码修改颜色列表。这是一个紫色的配色方案,每1/4对应一种颜色。
- colors = ["#f2f0f7", "#cbc9e2", "#9e9ac8", "#6a51a3"]
然后用刚才的几个四分点在for循环中修改着色条件。
- if rate > 10.8:
- color_class = 3
- elif rate > 8.7:
- color_class = 2
- elif rate > 6.9:
- color_class = 1
- else:
- color_class = 0
像之前那样运行脚本并存储,得到图8-19。请注意现在着色的县数量稍有增多。
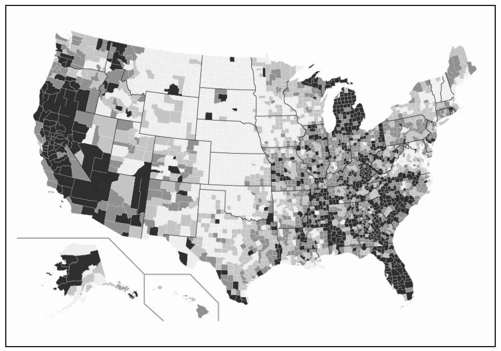
图8-19 按四分位数区分的失业率
为了提升代码的可用性,我们可以通过程序来计算四分位数,而不是依靠手写代码。这一过程在Python里面非常简单。把数值存储为一个列表,按由小到大排序,然后找到第1/4、1/2和3/4的几个数值。具体来说,在本例中我们可以修改colorize_svg.py中的第一个循环,使之只存储失业率。
- unemployment = { }
- rates_only = [ ] # To calculate quartiles
- min_value = 100; max_value = 0; past_header = False
- for row in reader:
- if not past_header:
- past_header = True
- continue
- try:
- full_fips = row[1] + row[2]
- rate = float( row[5].strip() )
- unemployment[full_fips] = rate
- rates_only.append(rate)
- except:
- pass
然后我们可以对数组进行排序,并找出那几个四分位数。
- # 四分位数
- rates_only.sort( )
- q1_index = int( 0.25 ☆ len(rates_only) )
- q1 = rates_only[q1_index] # 6.9
- q2_index = int( 0.5 ☆ len(rates_only) )
- q2 = rates_only[q2_index] # 8.7
- q3_index = int( 0.75 ☆ len(rates_only) )
- q3 = rates_only[q3_index] # 10.8
现在我们不必手动在代码里输入6.9、8.7和10.8这几个数值了,而可以用q1、q2和q3来代替它们。通过程序来计算这些值的好处在于,我们可以方便地将代码重用于不同的数据集,只需变动CSV文件即可。
选择何种色彩标尺取决于我们手中的数据,以及希望传达何种讯息。对本例中的数据集,我更喜欢线性标尺,因为它能更好地表现出分布,并且突出显示出整个国家中失业率相对较高的地区。以图8-18为基础,我们可以添加图例、标题和引文,从而得到一幅更加完善的图表,如图8-20所示。
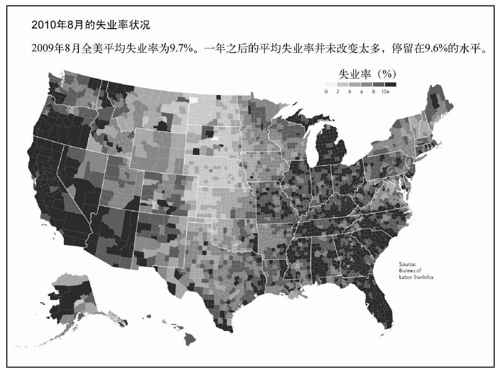
图8-20 带有标题、引文和图例的最终地图
2.绘制国家的地图
上例中为县着色的过程并不只针对于县这一级别,我们还可以重复同样的步骤为州或者国家着色。你需要的只是每个地区带有唯一ID的SVG文件(从维基百科上很容易获取),以及与ID适配的数据即可。现在让我们用来自世界银行的公开数据来试一试。
提示 世界银行是按国家划分的最完整的人口统计数据来源之一。它一般都是我的首选。
让我们看看2008年各国获得安全饮用水源的城市居民百分比数据。大家可以从世界银行数据网站下载到Excel文件:http://data.worldbank.org/indicator/SH.H2O.SAFE.UR.ZS/countries。为方便起见,也可以下载经过我精简后的CSV数据文件,地址是http://book.flowingdata.com/ch08/worldmap/water-source1.txt。其中有一些国家的数据丢失了,这在国家级别的数据中很常见。我已经在CSV文件中删除了这些行。
数据共有7列。第一列是国家名称,第二列是国家代码(这是否能变成我们的唯一ID?),而后五列则是1990—2008年的百分比。
要找底层地图,可以再次求助维基百科。在搜索SVG世界地图时,我们可以找到很多版本,统一用这一张:http://en.wikipedia.org/wiki/File:BlankMap-World6.svg。下载完整分辨率(Full resolution)的SVG文件,存储到与存放数据相同的文件夹。如图8-21所示,这是一个空白的世界地图,颜色是灰色,带有白色的边界线。
图8-21 空白的世界地图
在文本编辑器里面打开SVG文件。自然,它是一个XML格式的文本,但是内容的格式与我们上个例子稍有不同。路径没有ID,而且style属性也没有用上。不过,path标签里有一个类名,看上去好像是国家代码,但只有两个字母。而世界银行数据中的国家代码有三个字母。
世界银行的资料显示,他们使用的是ISO 3166-1三字母码。而来自维基百科的SVG文件用的则是ISO 3166-1二字母码。我知道这些名词看起来很吓人,但不用慌张,我们根本不需要记住这些。你只需要知道维基百科为此提供了一份转换表格,地址是http://en.wikipedia.org/wiki/ISO_3166-1。我将这份表格复制粘贴进了Excel,并将重要内容存成了一个文本文件,其中一列是二字母码,另一列是三字母码。下载地址是http://book.flowingdata.com/ch08/worldmap/country-codes.txt。我们将用这份表格在两种国家代码间切换。
至于修改各个国家的样式,我们也可以稍微换一种做法。这次不再直接修改path标签里的属性了,试试用路径外部的层叠样式表(CSS,Cascading Style Sheets)来为各个地区着色。
在SVG和CSV文件相同目录下创建一个名为generate_css.py的文件。再次导入CSV工具包来载入SCV文件中的数据,包括国家代码和获得水资源的人口百分比。
- import csv
- codereader = csv.reader(open('country-codes.txt', 'r'), delimiter="\t")
- waterreader = csv.reader(open('water-sourcel.txt', 'r'), delimiter="\t")
然后存储国家代码,以便将三字母码转变为二字母码。
- alphat3to2 = { }
- i = 0
- next(codereader)
- for row in codereader:
- alpha3to2[row[1]] = row[0]
这样能把代码存储进一个Python字典,其中三字母码是关键词,而二字母码是具体的值。
现在和上个例子一样,循环处理每一行水数据,并根据当前国家的具体值设置一个颜色。
- i = 0
- next(waterreader)
- for row in waterreader:
- if row[1] in alpha3to2 and row[6]:
- alpha2 = alpha3to2[row[1]].lower( )
- pct = int(row[6])
- if pct == 100:
- fill = "#08589E"
- elif pct > 90:
- fill = "#08589E"
- elif pct > 80:
- fill = "#4EB3D3"
- elif pct > 70:
- fill = "#7BCCC4"
- elif pct > 60:
- fill = "#A8DDB5"
- elif pct > 50:
- fill = "#CCEBC5"
- else:
- fill = "#EFF3FF"
- print '.' + alpha2 + ' { fill: ' + fill + ' }'
- i += 1
这段脚本执行了以下几个步骤:
(1)避开CSV文件的头部;
(2)开始循环读取水数据;
(3)如果有二字母码对应于CSV的三字母码,并且该国家有2008年的数据,那么就找到了对应的二字母码;
(4)根据百分比数据选择合适的填充色;
(5)为每行数据都输出一行CSS。
运行generate_css.py并将输出保存为style.css。该CSS的前几行应该类似这样:
- .af { fill: #7BCCC4 }
- .al { fill: #08589E }
- .dz { fill: #4EB3D3 }
- .ad { fill: #08589E }
- .ao { fill: #CCEBC5 }
- .ag { fill: #08589E }
- .ar { fill: #08589E }
- .am { fill: #08589E }
- .aw { fill: #08589E }
- .au { fill: #08589E }
- ...
这是标准的CSS。例如第一行会把所有类名为af的路径的填充色改为#7BCCC4。
在文本编辑器里面打开style.css,并复制所有内容。然后打开SVG地图,将复制的内容粘贴到oceanxx的花括号下面,大概在第135行。现在我们已经创建了一幅世界范围的等值区域图,并根据各国获得安全饮用水源的人口百分比着了色,效果如图8-22所示。深蓝色表示100%,而浅绿色代表百分比较低。依然呈灰色的国家表示其数据未知。
图8-22 显示了安全饮用水资源的世界范围等值区域图
最棒的是,现在你可以下载世界银行的任意数据集(有很多),而只需改动几行代码就能快速为它们创建等值区域图了。要想让图8-22的图形再漂亮点,我们可以继续用Illustrator打开SVG文件进行编辑。这幅地图主要还需要一个标题和用于说明各颜色意义的图例,最终效果如图8-23所示。
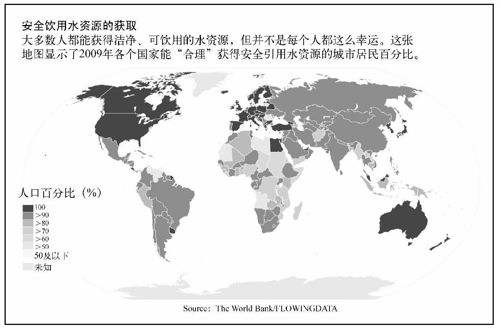
图8-23 完成的世界地图(另见彩插图8-23)

{kind=link}
{kind=link}