7.2 在多个变量间比较
在面对多个变量时,主要的挑战在于从哪里开始。如果我们不事先考虑好自己掌握的数据是什么,在面对如此众多的变化及子集时就会无所适从。有时候,最好的做法是先一次性观察所有的数据,那些让你感兴趣的内容自然会为你指引方向。
7.2.1 热身
要想对表格中的数据进行可视化,最直接的方法就是一次性把它们都显示出来。不过我们可以用颜色代替数字来表示数值,如图7-1所示。
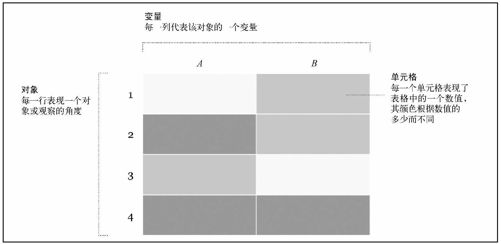
图7-1 热点图的基本框架
我们会得到一个与原始数据表格大小相同的网格,但根据单元格颜色的不同,很容易就能找出那些相对较高或较低的数值。一般来说,深色代表高数值,浅色代表低数值。不过根据应用场景不同,这一规则也有可能会发生变化。
在阅读热点图(heatmap,或者叫热点矩阵,heat matrix)时,使用的方法也与阅读表格时相同。我们可以从左到右地阅读,了解一个对象的所有变量的数值,也可以只选择一个变量,了解所有对象在该方面的表现如何。
这种布局可能依旧会让人困惑,尤其是当数据表格非常庞大时。但有了颜色的区分以及排序,得到的图表还是能为我们带来很大帮助。
创建热点图
在R里面创建热点图非常简单。有heatmap( )函数来包办所有的计算工作,我们只需选择合适的颜色,然后组织好标签,以便在有多行多列的情况下保持易读性。换句话说,R负责基础框架,而我们负责设计。这本书读到这里,这句话大家应该很耳熟了吧。
在本例中,我们来看一下2008赛季NBA球员的统计数据。大家可以在http://datasets.flowingdata.com/ppg2008.csv下载到CSV格式。数据共有22列,第一列是球员姓名(Name),其他列则是统计数据,例如PTS(场均得分)和FGP(投篮命中率)。你可以在R里用read.csv( )来载入数据。现在让我们看看数据的前五行,以便对数据的结构有个概念(见图7-2)。
- bball <-
- read.csv("http://datasets.flowingdata.com/ppg2008.csv",
- header=TRUE)
- bball[1:5,]

图7-2 前五行数据的结构
现在这些球员是按PTS由高到低排序的。但我们也可以通过order( )函数来按任一列排序,例如场均篮板数(TRB)或者FGP。
- bball_byfgp <- bball[order(bball$FGP, decreasing=TRUE),]
提示 order( )中的decreasing参数可以指定是按升序还是降序排列。
现在再看看bball_byfgp的前五行,我们会发现刚才排名前列的Dwyane Wade(德怀恩·韦德)、Lebron James(勒布朗·詹姆斯)和Kobe Bryant(科比·布莱恩特)被换成了Shaquille O'neal(沙奎尔·奥尼尔)、Dwight Howard(德怀特·霍华德)和Pau Gasol(保罗·加索尔)。在本例中,我们将根据PTS逆序排列。
- bball <- bball[order(bball$PTS, decreasing=FALSE),]
现在,每一列的名称与CSV文件的数据头是一致的,这和我们想要的相符。不过,我们还希望每一行的名称应该是球员的姓名,而不是现在的行号。所以需要把第1列设置为行名称。
- row.names(bball) <- bball$Name
- bball <- bball[,2:20]
第一行代码将行名称改成了数据块中的第1列。第二行代码选择了第2列到第20列,并将该子集设置为新的bball。
另外,数据必须是矩阵(matrix)格式,而不能是数据块(data frame)格式。如果我们在heatmap( )函数中使用数据块就会报错。总的来说,数据块有点像一系列向量的集合,其中每一列都代表一个不同的度量。每一列都可以有不同的格式,例如数字或者字符串。而矩阵则通常被用于表现二维空间,而且所有单元格中的数据类型必须保持统一。
- bball_matrix <- data.matrix(bball)
提示 很多可视化都涉及数据的收集和准备。我们获得的数据往往和需要的并不完全相符,因此大家要有心理准备,在进入视觉部分之前可能得做一些数据再加工。
现在数据已经按我们所希望的进行了排序及格式化,将其放入heatmap( )里面就能有所收获了。我们把scale参数指定为“column”,这是在告诉R用每一列的最大值和最小值来定义颜色的色阶,而非用整个矩阵的最大值和最小值。
- bball_heatmap <- heatman(bball_matrix, Rowv=NA,
- Colv=NA, col = cm.colors(256), scale="column", margins=c(5,10))
你的结果应该类似于图7-3。我们通过cm.colors( )指定了颜色范围由青色(cyan)变为洋红色(magenta)。这一函数创建了一个16进制的颜色向量,范围默认由青到洋红,其中有n个不同的色值(本例中是256个)。所以,请注意图中的第3列(也就是PTS)由洋红色开始,这表示Dwyane Wade和Lebron James在该方面的数值是最高的,然后逐渐变色,到底部已经变成了较暗的青色系,代表该方面数值置底的Allen Iverson和Nate Robinson。我们也可以很快找到其他洋红色的单元格,例如篮板数(TRB)最高的Dwight Howard或者助攻(AST)最突出的Chris Paul。
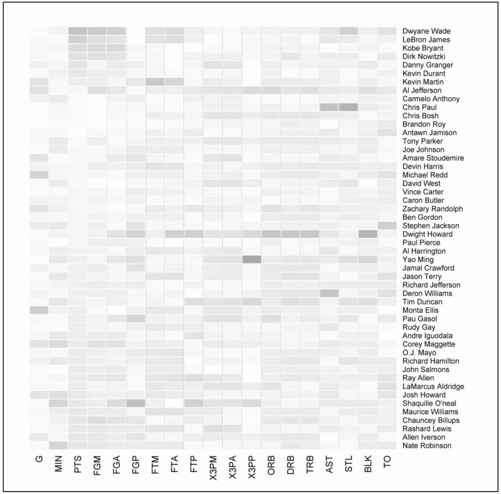
图7-3 按PTS排序的默认热点图(另见彩插图7-3)
你也许想要换一种颜色风格。只需要改动col参数即可,在我们刚才运行的那段代码中,它是cm.colors(256)。可以输入?cm.colors寻求帮助,看看R都提供哪些颜色。比如我们可以用看上去更有激情的颜色,如图7-4所示。
- bball=heatmap <- heatmap(bball_matrix,
- Rowv=NA, Colv=NA, col = heat.colors(256), scale="column",
- margins=c(5,10))

图7-4 红-黄色系的热点图(另见彩插图7-4)
如果你在R中输入cm.colors(10),就会得到一个由青到洋红的10个颜色的数组。之后heatmap( )会自动按线性运算,为各个数值选择相应的颜色。
- [1] "#80FFFFFF" "#99FFFFFF" "#B3FFFFFF" "#CCFFFFFF" "#E6FFFFFF"
- [6] "#FFE6FFFF" "#FFCCFFFF" "#FFB3FFFF" "#FF99FFFF" "#FF80FFFF"
这一点很棒,因为我们可以轻松地创建自己的颜色范围。比如说,我们可以去0to255.com先选择一种基本色,然后再详细选择。图7-5显示了基本色为红色的色阶。我们可以选出一些颜色,由浅到深,然后放到heatmap( )里面,如图7-6所示。这次我没有让R来创建颜色向量,而是定义了一个自己的red_colors变量。
图7-5 Oto255.com里面的红色系色阶(另见彩插图7-5)

7-6 使用了自定义红色系的热点图(另见彩插图7-6)
- red_colors <- c(#ffd3cd", "#ffc4bc", "#ffb5ab',
- "#ffa69a", "#ff9789", "#ff8978", "#ff7a67", "ff6b56",
- "#ff5c45", "#ff4d34")
- bball_heatmap <- heatmap(bball_matrix, Rowv=NA,
- Colv=NA, col = red_colors, scale="column", margins=c(5,10))
提示 明智地选择颜色,因为它们也会奠定你的故事的整体基调。比如说,如果你的主题较为严肃,可能中性、柔和的色调会更好,而激昂、休闲的主题则更适合采用明亮的色彩。
如果你不想自己设定颜色,也可以使用R的ColorBrewer工具包。这个工具包不是默认安装的,因此如果你没有的话,就需要下载并通过Package Installer来安装。ColorBrewer是由制图师Cynthia Brewer设计的,本来用于地图绘制,不过它也能帮助我们创建常用的数据图表。有很多选项可供选择,例如各种连续色或相反色的调色盘以及许多色阶等。本例中我们选择了简单的蓝色调色盘。在R中输入?brewer.pal可以得到更多选项,非常好玩。假设你安装了RColorBrewer,输入以下代码就能得到一个蓝色系、9色阶的热点图,效果如图7-7所示。
- library(RColorBrewer)
- bball_heatmap <- heatmap(bball_matrix, Rowv=NA,
- Colv=NA, col = brewer.pal(9, "Blues"),
- scale="column", margins=c(5,10)

图7-7 利用RColorBrewer作为调色盘的热点图(另见彩插图7-7)
►访问http://colorbrewer2.com以尝试ColorBrewer的可交互版本。你可以在下拉菜单里进行选项设置,在样本地图中看到各种颜色主题的效果。
图7-7还可以再导入到Illustrator里面继续优化。图形方面不需要太多修饰,但我们可以让标签更加易读一些、颜色更加柔和一些,让图表更加易于浏览。
对于标签来说,最好不要用缩写。作为篮球迷来说,我知道每一个缩写都代表什么意思,但那些对这项运动不太熟悉的人可能会摸不着头脑。对于颜色,我们可以打开Illustrator的“颜色”(Color)面板,通过调整透明度来缓和对比度。为单元格添加边框也能提升可辨识度,让图表更加易于从左到右、从上到下地浏览。图7-8显示了最终完成的效果。
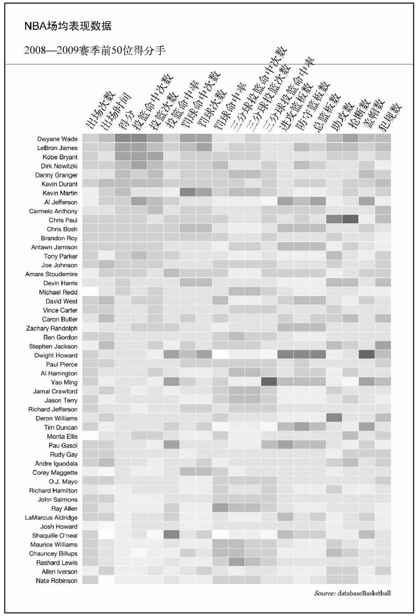
图7-8 显示2008—2009赛季NBA前50位得分手场均表现数据的热点图
►Mike Bostock在Protovis里也借用了我的这个例子,大家可以在Protovis的范例部分找到。视觉上两者完全一样,但他的范例的交互效果更加丰富:当鼠标移到单元格上时会出现提示信息。
7.2.2 相面术
热点图的好处在于它能让我们一次性看到所有的数据,但是这样一来,关注点总会落在单个的点上。我们可以很快找出场均得分或者篮板数的高低,但要想将某位球员和另一位球员进行综合比较,却存在着很大难度。
有些时候,我们不希望让每个对象都被各种指标切散,而是希望把它们当做一个个的整体来观察。切尔诺夫脸谱图(Chernoff Faces)就能满足这种需求。该方法并不是业界通用的标准方法,而且很可能会让那些普通读者一头雾水。但尽管如此,切尔诺夫脸谱图还是经常能体现出其价值的。另外,它对于数据迷来说非常有趣,我想这个理由就足够了。
切尔诺夫脸谱图的关键在于,它会根据数据集中的数字将多个变量一次性展现在人脸的各个部位上,例如耳朵、头发、眼睛、鼻子等(见图7-9)。我在此假设读者在现实生活中都能轻易辨识人的面部特征,这样当它们在表现数据时,大家才可能识别出那些微小的差别。这是个比较冒险的假设,但我相信大家都有这种能力。
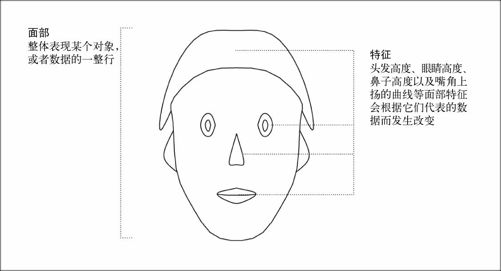
图7-9 切尔诺夫脸谱图的基本框架
大家在后面的例子中将会看到,较大的数值会以更多的头发或更大的眼睛的形式来出现,而较小的数值则会对面部特征进行收缩。除了尺寸大小以外,我们还可以调整诸如嘴唇曲线或脸型等其他面部特征。
创建切尔诺夫脸谱图
让我们回到之前的篮球数据,也就是2008—2009赛季NBA前50位得分手的统计成绩。每一位球员都会有一张脸谱。不用慌张——你不必手动去画这些脸。R中的aplpack提供了faces( )函数,它能帮助我们得到想要的结果。
如果你还没有这个工具包,可以通过install.packages( )来安装,或者利用Package Installer选项来完成。这个工具包的名称aplpack代表的意思是another plotting package(另一个绘图工具包),由Hans Peter Wolf设计。安装完成后,工具包应该会自动载入,但有可能也需要手动载入。
- library(aplack)
说明 最新版本的aplpack能让我们通过faces( )函数来添加颜色。在本例中,我们将ncolors设置为0,也就是只使用了黑色和白色。输入?faces可以查阅如何使用颜色向量,其方法和之前热点图例子中的用法是一样的。
在之前创建热点图时,你应该已经载入了篮球数据。如果没有的话,再次使用read.csv( )通过URL来直接载入数据。
- bball <- read. csv("http://datasets.flowingdata.com/ppg2008.csv",
- header=TRUE)
载入了工具包和数据之后,就可以直接用faces( )函数来生成切尔诺夫脸谱图了,结果如图7-10所示。
- faces(bball[,2:16], ncolors=0)
图7-10 默认生成的切尔诺夫脸谱图
算上球员的姓名,我们的数据集中总共有20个变量。但是aplpack提供的faces( )函数只支持最多15个变量,因为只有这么多脸部特征能够被改变。这就是为什么我们要将集合缩小到从第2列到第16列。
每张脸谱都代表什么意思呢?faces( )函数会配合数据集中各列的顺序,按照以下顺序来修改面部特征。
(1)脸庞的长度
(2)脸庞的宽度
(3)脸型
(4)嘴唇的高度
(5)嘴唇的宽度
(6)嘴角上扬的曲线
(7)眼睛的高度
(8)眼睛的宽度
(9)头发的高度
(10)头发的宽度
(11)发型
(12)鼻子的高度
(13)鼻子的宽度
(14)耳朵的宽度
(15)耳朵的高度
所以,脸庞的长度代表的是赛季出场的次数,而嘴唇的高度则代表场均投篮命中的次数。由于每张脸都没有对应的姓名,这张图表似乎没多大用处,不过我们还是能看出头几名球员各方面都表现比较全面,而第7名球员的头发相对很宽,这表示他每场投中的三分球较多。
提示 如果对应的个体很多,对其进行分类可能会便于对脸谱的浏览。比如说,我们可以根据球场上的位置来为这些脸谱进行分类:后卫、前锋和中锋。
在faces( )中使用labels参数来为脸谱添加姓名,结果如图7-11所示。
- faces(bball[,2:16], labels=bball$Name)
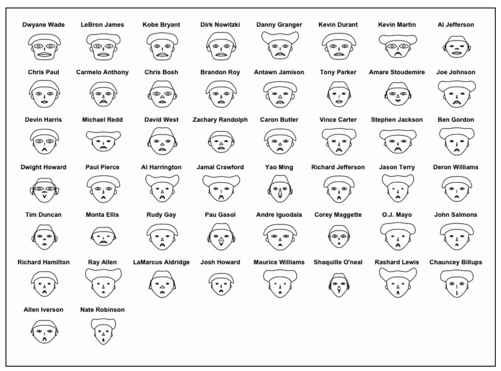
图7-11 带有球员姓名的切尔诺夫脸谱图
这样看上去好多了。现在我们可以看到哪张脸对应哪位球员。要想找出控球后卫,我们可以从Chris Paul(克里斯·保罗)开始,找寻和他脸谱相似的球员,例如Devin Harris(德文·哈里斯)或者Deron Willams(德隆·威廉姆斯)。不过,右下角的Chauncey Billups(昌西·比卢普斯)也是一位控球后卫,但他的脸看上去与其他控球后卫不太一样。他的头发更高,嘴唇更窄,这些表示他的罚球命中率较高,而场均投篮次数较少。
为了让图表更加易读,我们可以加大各行之间的距离,或者至少提供一段描述,说明哪些面部特征代表哪些数据,如图7-12所示。通常情况下,我会用一张实际图例来进行说明,但我们用到的面部特征实在太多,在一张脸上画那么多箭头实在是惨不忍睹。

图7-12 2008—2009赛季NBA前50位得分手的切尔诺夫脸谱图
提示 在画面中留出一些空白区域,会让图表更加易读,尤其是在要看和评估的内容很多的时候。
再次申明,切尔诺夫脸谱图的价值会根据数据集与受众群体的不同而不同,因此大家可以自行决定是否使用这一方法。还有一点是,那些不太熟悉切尔诺夫脸谱图的人总喜欢“以貌取人”,他们认为代表Shaquille O'Neal的脸谱似乎就应该与他本人类似。但我们绝大多数人都知道,O'Neal可是有史以来体型最大的篮球运动员之一。
用同样的方式,我又设计了美国犯罪情况的切尔诺夫脸谱图,如图7-13所示。居然有人因为那些高犯罪率州的脸型而评论说它有种族歧视倾向。我可从没想过这一点,因为对我来说,修改某个面部特征就和修改某个柱形的长度一样。不过这个问题倒的确值得考虑一下。

图7-13 美国犯罪率统计,每张脸谱代表一个州
提示 设计图表时,要站在普通读者的角度考虑问题。普通读者并不像我们那样熟悉各种可视化方式,对数据的理解也不如我们深刻,因此作为故事的讲述者,我们必须承担起解释说明的责任。
7.2.3 星光灿烂
除了用脸谱来表现多变量数据之外,我们还可以遵循同样的概念将图表抽象为另一种形状。我们不再修改面部特征,而是直接修改形状来表现不同的数据值。这就是星图(star chart)的制作原理,它也被称为雷达图(radar chart)或者蜘蛛图(spider chart)。
如图7-14所示,我们可以绘制多条轴,每一条轴代表一个变量,由正中心开始,等距平分圆周摆放。正中心表示各个变量的最小值,而轴末端的终点代表最大值。在绘制图表时,在每个变量的终点和下一条轴的终点之间还需要绘制一条连接线。最后得到的图表就好像一颗星星一样(或者说像雷达或蜘蛛网)。
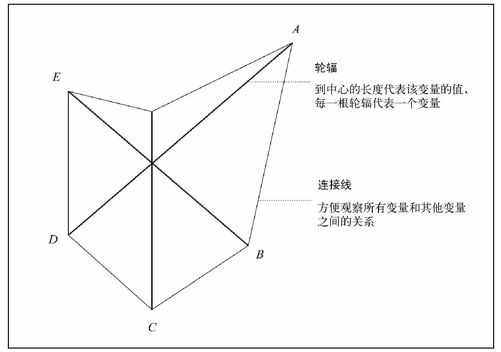
图7-14 星图的基本框架
我们也可以在一幅星图里表现多个对象,但如果数量稍多就会过于杂乱,导致故事没法讲清楚。所以最好还是坚持用一个星图表现一个对象,这样更便于比较。
创建星图
现在让我们继续使用图7-13用到的犯罪数据,来看看星图的表现手法会有哪些不同。首先还是在R中载入数据。
- crime <- read.csv("http://datasets.flowingdata.com/
- crimeRatesByState-formatted.csv")
然后就可以直接创建星图了,和创建切尔诺夫脸谱图非常类似。我们用到的是R中已封装好的stars( )函数。
- stars(crime)
默认的图表如图7-15所示。希望这幅图不会冒犯任何人。自然,每个州的标签尚待添加,此外还需要一个图解(key),以便了解每一条轴所代表的意义。和faces( )一样,这些轴肯定遵循着某种顺序,但我们无法知道第一个变量是从哪里开始的。所以让我们一次搞定这些内容。别忘了可以把第一列移动到行名称上去,就和热点图中我们所做的一样。此外,还可以把flip.labels设置为FALSE,因为我们不希望标签影响到高度。结果如图7-16所示。
- row.names(crime) <- crime$state
- crime <- crime[,2:7]
- stars(crime, flip.labels=FALSE, key.loc = c(15, 1.5))

图7-15 显示各州犯罪情况的默认星图
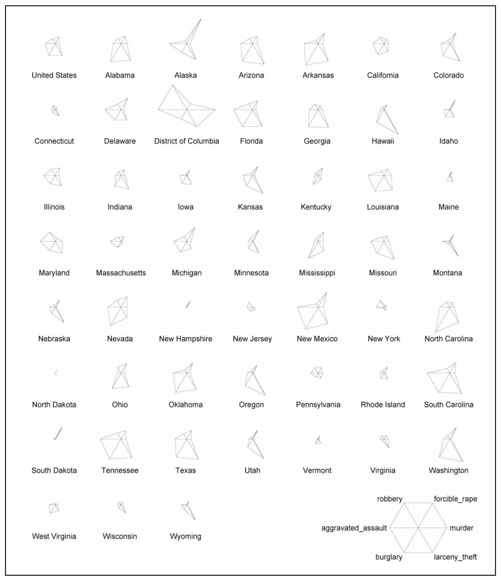
图7-16 添加了标签和说明的星图
现在更容易辨别各州的差别和相似之处了。在切尔诺夫脸谱图中,哥伦比亚特区(District of Columbia)看上去就像一个大眼睛小丑,而在星图中我们看到,尽管它某些类型的罪案发生率较高,但强奸和入室盗窃的发生率还是相对较低的。我们也很容易找到那些犯罪率相对较低的州,例如新罕布什尔州(New Hampshire)和罗德岛州(Rhode Island)。而还有一些州,例如北卡罗来纳(North Carolina),只有某单一类型的罪案发生率较高。
对于这套数据来说,我对这种格式已经比较满意了。不过它还有两种变体,也许大家会希望尝试。第一种将所有数据都限制在了圆形的上半部分,如图7-17所示。
- stars(crime, flip.labels=FALSE, key.loc = c(15, 1.5), full=FALSE)

图7-17 将各轴限制在上半圆的星图
第二种变体则体现了各个扇形的长度,而不只是各轴终点的位置,如图7-18所示。这种图表其实已经不是星图了,而是南丁格尔图(也叫极坐标区图,polar area diagram),不过大家明白意思就行。如果你选择这种表现形式,可能需要尝试使用不同的颜色主题,而不是默认的这种怪异颜色。
- stars(crime, flip.labels=FALSE, key.loc = c(15, 1.5), draw.segments=TRUE)

图7-18 南丁格尔图显示的犯罪率(另见彩插图7-18)
就像我刚才所说,我对图7-16所示的那种原始格式已经很满意了,所以可以把它导入到Illustrator里面做一些优化。这幅图表并不需要太多修改工作。在各行之间略微增加空白区域可以减少标签引起的歧义,另外可以把说明挪到顶端,让读者一开始就知道要阅读的内容(见图7-19)。其他的就没什么了。

图7-19 显示各州犯罪率的系列星图
7.2.4 平行前进
尽管星图和切尔诺夫脸谱图能方便地找出各个对象与同类之间的差异,但它们却很难描述群组或各变量之间的关系。1885年由Maurice d'Ocagne发明的平行坐标图能帮我们解决这个问题。
如图7-20所示,我们将多条轴平行放置。每条轴的顶端表示该变量的最大值,底端表示最小值。对于每个对象来说,会出现一条由左到右的线条,根据各个变量数值的不同而上下浮动。
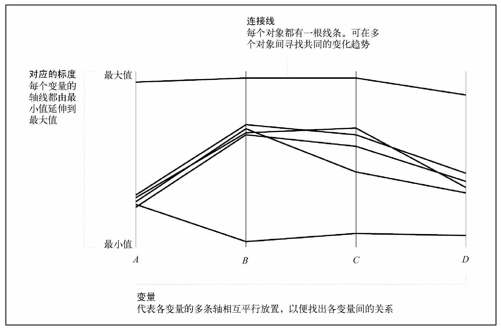
图7-20 平行坐标图的基本框架
假设我们用之前的篮球数据来绘制这种图表。为了简单起见,我们只按顺序绘制得分、篮板和犯规数量。如果有一位球员是顶级得分手,但抢篮板能力很弱,又喜欢犯规,那么在平行坐标图中,该球员的线条就会一开始很高,然后降低,然后再次升高。
当我们绘制更多对象时,这一方法就能帮助我们找出群组和趋势的变化。在下面的例子中,我们将用平行坐标图表现来自美国国家教育统计中心的数据。
创建平行坐标图
从可交互方面来看,绘制平行坐标图有多种选择。如果想创建自定义图形,我们可以在Protovis里面构建,或者把数据载入到诸如GGobi这样的实验性工具中。这些方法可以让我们过滤出并高亮显示自己感兴趣的数据点。不过,我还是倾向于绘制静态的平行坐标图,因为这样可以一次性比较各种不同的过滤结果。如果是可交互版本,我们就只能得到一张图,而且如果在一个地方显示一大堆高亮的结果,会很难看清内容。
第一步想必大家都知道了。在开始进行可视化之前,我们需要数据。在R中用read.csv( )来载入我们的教育数据。
- education <- read.csv("http://datasets.flowingdata.com/education.csv",
- header=TRUE)
- education[1:10,]
数据共有7列。第一列是各州的名称,其中“United States”是全国平均数据。其后3列依次是各州高中生在阅读、数学和写作各科目的SAT(1)平均得分。第5列是各州高中毕业生参加SAT考试的百分比,最后2列则是各州的高中毕业生就业率和高中生辍学率。我们感兴趣的是这些变量是否相互关联,以及是否存在任何明确的分组。比如说,那些高辍学率的州是否SAT的平均得分也会较低?
R本身并不支持直接生成平行坐标图,但lattice工具包可以。我们先载入该工具包(如果没有该工具包,请先安装)。
- library(lattice)
很好,现在就简单了。lattice工具包提供了一个parallel( )函数,可以直接使用。
- parallel(education)
这将生成如图7-21所示的图表。很好,但这实际上没什么用。在图上有太多的线条,而且变量是从上到下放置的,不是从左到右。现在这张图看上去就像是彩虹色的意大利面。

图7-21 用lattice工具包生成的默认平行坐标图
要怎样来修改这幅平行坐标图才能从中获得信息呢?首先,我们应该将它横过来放置。当然这并不是一条硬性规则,只是个人喜好问题,但从左到右的平行坐标看上去明显更符合习惯,如图7-22所示。
- parallel(education, horizontal.axis=FALSE)
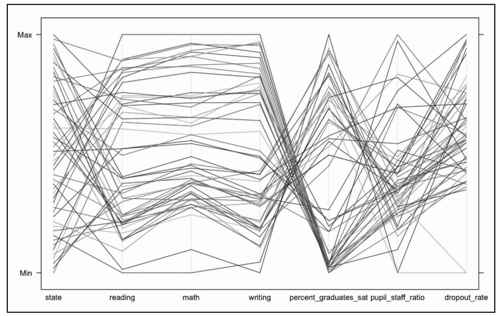
图7-22 水平放置的平行坐标
我们也不需要州名那一列,这是因为:第一、州名并不是数值;第二、每个州的名字都不相同。现在把线条的颜色都改为黑色——我很喜欢颜色,但现在也太多了点。执行以下代码,我们就会得到图7-23。
- parallel(education[,2:7], horizontal.axis=FALSE, col="#000000")
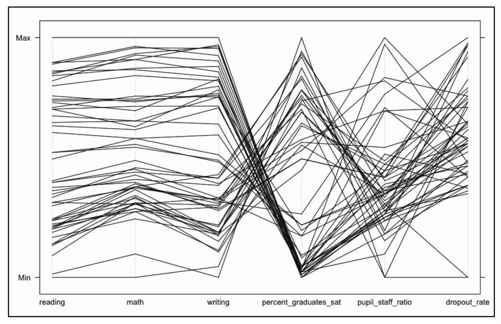
图7-23 简化后的平行坐标
现在看上去好些了。从阅读、数学到写作科目的线条很少相互交错,几乎是平行前进的。这表示那些阅读成绩好的州,同样数学和写作的成绩也会较好。与之类似,阅读成绩较差的州在数学和写作方面也不尽如人意。
从SAT成绩继续往右,在各州的SAT考试参加率这里,有趣的事情发生了。看上去似乎在那些SAT平均得分较高的州,参加SAT考试的学生却并不占多数。而SAT平均得分较低的州情况却正相反。我对教育领域并不算太熟悉,但我猜这是因为有些州里每个高中毕业生都参加了SAT考试,而在其他州里,如果学生不想上大学,他们就不会参加SAT考试。所以,如果要求那些对考试结果并不关心的学生去参加考试,平均分自然就会被拉低了。
我们可以加入一些对比色,让这一点体现得更加明显。在parallel( )函数中,可以通过col参数来完全控制颜色。在之前,我们只用了一种颜色(#000000),但也可以向它传递一个颜色数组,给每一行数据设定一个颜色值。现在让我们将阅读得分排名前50%的州设置为黑色,将它们下面的那些州设置为灰色。首先用summary( )来找到教育数据中阅读科目得分的中位数。在R中输入summary(education),它会返回所有列的状态摘要,我们很容易就能发现,阅读(reading)科目得分的中位数是523。
- state reading math writing
- Alabama :1 Min. :466.0 Min. :451.0 Min. :455.0
- Alaska :1 1st Qu.:497.8 1st Qu.:505.8 1st Qu.:490.0
- Arizona :1 Median :523.0 Median :525.5 Median :510.0
- Arkansas :1 Mean :533.8 Mean :538.4 Mean :520.8
- California:1 3rd Qu.:571.2 3rd Qu.:571.2 3rd Qu.:557.5
- Colorado :1 Max. :610.0 Max. :615.0 Max. :588.0
- (Other) :46
- percent_graduates-sat pupil_staff_ratio dropout_rate
- Min. :3.00 Min. :4.900 Min. :-1.000
- 1st Qu.:6.75 1st Qu.:6.800 1st Qu.:2.950
- Median :34.00 Median :7.400 Median :3.950
- Mean :37.35 Mean :7.729 Mean :4.079
- 3rd Qu.:66.25 3rd Qu.:8.150 3rd Qu.:5.300
- Max. :90.00 Max. :12.00 Max. :7.600
现在遍历数据的每一行,检查它是大于还是小于该中位数,并指定相对应的颜色。C( )指令创建了一个空的向量,每次循环都会往其中添加一个值。
- reading_colors <- c( )
- for (i in 1:length(education$state)) {
- if (education$reading[i] > 523) {
- col <- "#000000"
- } else {
- col <- "#cccccc"
- }
- reading_colors <- c(reading_colors, col)
- }
然后将reading_colors数组传递到parallel( )里面,而不是一个单独的“#000000”。这会让我们得到图7-24,从中可以很容易地看出由高到低的大转移。
- parallel(education[,2:7], horizontal.axis=FALSE, col=reading_colors)
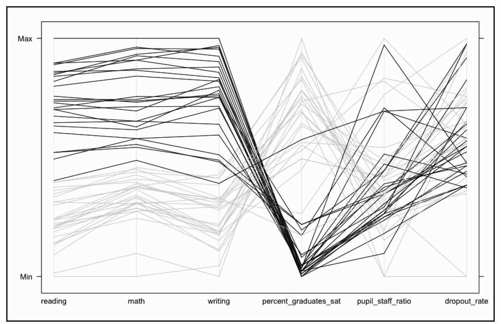
图7-24 阅读成绩较好的州被高亮显示
那么在辍学率方面,情况又是如何呢?我们可以对辍学率进行与阅读得分相同的处理,只不过这次用第三个四分位数,而非中位数。这个四分位数是5.3%。再次,我们遍历每一行数据,只不过这次检查的是辍学率,而非阅读科目的平均得分。
- dropout_colors <- c( )
- for (i in 1:length(education$state)) {
- if (education$dropout_ratel[i] > 5.3) {
- col <- "#000000"
- } else {
- col <- "#cccccc"
- }
- dropout_colors <- c(dropout_colors, col)
- }
- parallel(education[,2:7], horizontal.axis=FALSE, col=dropout_colors)
图7-25 显示了得到的结果,这次的效果不如前一个图表那样引人注目。从视觉上来看,在所有变量中并没有明显的分组趋向。
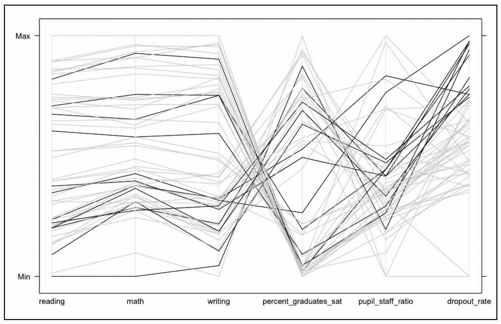
图7-25 辍学率较高的州被高亮显示
大家也可以在自己感兴趣的方面进行更多的探索。现在让我们回到图7-24并进行优化。美化标签可以让它们更加明显。或者加入一些颜色来代替单纯的灰度?或者加入一段简短的说明,以解释为什么50%的州都被高亮显示?最终得到的结果将如图7-26所示。
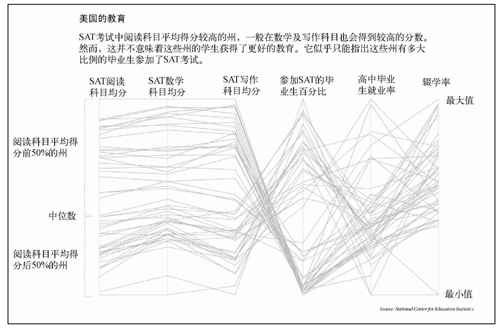
图7-26 关于SAT得分的平行坐标图表(另见彩插图7-26)
