2.2 设置数据的格式
不同的可视化工具支持不同的数据格式,而且所用到的结构也会根据你打算讲的故事而有所差异。所以,你的数据结构越灵活,带来的可能性也会越多。运用数据格式化工具,再加上一点编程技巧,你就能为数据安排各种不同的格式、满足各种需求。
最简单的办法当然是找一个程序员来帮你做数据的分析和格式化工作,但你总是得看人脸色。这一点在任何项目的早期阶段尤为明显,在此阶段,循环处理和数据探索对于可视化设计来说都是非常关键的。说句实话,如果我是用人部门,我也喜欢招收那些了解如何处理数据的人,而不是在每个项目初期都需要别人帮助的人。
我对格式化的理解
当我在高中接触统计学时,需要的数据都有着清楚的、矩阵式的格式。我要做的就是把其中一些数字导入到Excel表格或者当时最时髦的图形计算器中去(上课时用这玩意看似在认真计算什么,其实大多时候都在玩俄罗斯方块)。到大学后也是如此,因为我学习的是数据分析理论与技巧,老师们不会在原始的、未处理过的数据上浪费时间。数据一直都以合适的格式呈现。
考虑到当时的学习重点和课业进度限制,这很容易理解。但开始研究生课程之后,我意识到真实世界里的数据从来都不会按自己需要的格式呈现。你会遇到各种情况,例如某个数值莫名其妙的丢失、标记前后矛盾、没有任何上下文背景,或者千奇百怪的笔误。数据通常都散落在多个表格中,但我们需要的是一个包含所有数据的表格,而且带有各自的名称或独立的ID号。
在我开始可视化工作之后也是如此。而且格式化变得越来越重要,因为我希望用手中的数据做更多的事情。如今,我在数据格式化上花的精力和可视化一样多,有时候甚至超过了可视化的时间。乍一听这似乎有点奇怪,但你会发现当所有的数据都经过精心组织后,对图形的设计会变得更加简单,就像回到了高中的入门课程一样。
下面将介绍各种数据格式、处理格式的工具以及一些编程知识。编程中涉及的逻辑思路和之前搜集数据时所用的几乎相同。
2.2.1 数据格式
大多数人都习惯用Excel来处理数据。如果你打算从分析到可视化一直都用这款软件,那么没问题。但如果你想跨出这个圈子,就需要熟悉一下其他数据格式。这些格式之所以存在,是为了让你的数据机器可读,也就是设置成计算机能够理解的格式。使用何种格式取决于你的意图和所用的可视化工具,不过以下3种格式基本上可以满足所有需求:带分隔符的文本、JavaScript对象表示法(JavaScript Object Notation)和可扩展标记语言(eXtensible Markup Language)。
1.带分隔符的文本
很多人都很熟悉带分隔符的文本。我们在前面一节的例子中就创建过以逗号分隔的文本文件。如果把数据集看成是按行和列来分布,那么分隔符文本就是用分隔符来分开每一列。分隔符一般用的是英文逗号(半角字符),也可以是制表符tab,或者是空格、英文分号、冒号、斜杠等任何你喜欢的字符。不过逗号和tab是最常见的。
分隔符文本应用广泛,可以被大多数电子表格程序阅读,例如Excel或者Google Documents。我们也可以把电子表格输出成分隔符文本。如果你要使用多个工作表格,通常就会有多个分隔符文件,除非特殊指定。
这种格式也便于与其他人共享,因为它无需依赖于任何特定程序。
2.JavaScript对象表示法(JSON)
很多网页API都适用于这种格式。它既能够让计算机理解,又便于人类阅读。不过如果你眼前的数据过多,盯太久可能会头晕目眩。该格式基于JavaScript表示法,但并不依赖于这种语言。JSON中有许多规格说明,但只用掌握一些基础就能满足大部分需要。
JSON利用关键字和值,并且把数据条目作为对象来处理。如果我们把JSON数据转化成逗号分隔数据(Comma-Separated Value,CSV),那么每个对象都会占一行。
大家将会在后文中看到,有很多应用、语言和函数库都支持JSON输入。如果你打算设计便于互联网传播的数据图形,就得了解一下这种格式。
►访问http://json.org阅读JSON的完整说明。你不必了解这一格式的所有细节,但当你需要使用某个JSON数据源时,它还是很管用的。
3.XML
XML(可扩展标记语言)是另一种互联网上的流行格式,常被用于在API间传递数据。XML分为很多类型,规格说明也不少,但从最基本的层面来看,它就是一个文本文件,其中的值都封闭在各种标签之内。比如说,人们用于订阅各种博客RSS(如FlowingData)的feed就是一个XML文件,如图2-7所示。
图2-7 FlowingData网站RSS的feed片段
目前的RSS列表中,数据条目都被封闭在<item></item>标签中,每一条都带有各自的标题、描述、作者、发布日期以及其他属性。
XML相对比较容易用函数库来分析,例如Python里面的Beautiful Soup。在本书后面的内容中,大家会更加熟悉XML、CSV以及JSON。
2.2.2 格式化工具
在几年前,人们需要写一些小脚本才能对数据进行处理和格式化。在写了几次脚本后,你就会注意到其中的逻辑规律,所以即使每逢新的数据集都需要写新的代码,也并不是什么难事。不过每次都这样做也确实挺花时间。幸而随着数据处理量的逐渐增大,有人开发了一些工具来代替我们进行这种千篇一律的手工劳动。
1.Google Refine
Google Refine是Freebase Gridworks的进化版本。Gridworks最初是Freebase这个开放数据平台的内部工具,但是后来Freebase被Google收购,所以Gridworks也就换了名字。从本质上来说,Google Refine就是易用性更强、功能更多的Gridworks 2.0版本(参见图2-8)。
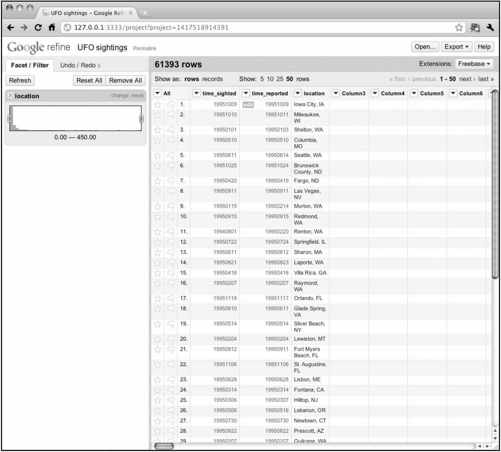
图2-8 Google Refine的用户界面
它会在你的桌面运行(但依然会通过浏览器),这一点很棒,因为我们无需担心私密数据会上传到Google服务器去,所有的处理都在自己的计算机上进行。Refine也是开源的,如果你有需求,也可以将它扩展到你自己的应用中去。
在运行Refine时,我们会看到一个熟悉的电子表格界面。数据都按照行和列的形式呈现,便于排序或者搜索某个值,同时也能很轻松地找出数据中的矛盾之处从而加以改进。
比如说,你需要建立一个自己家厨房的财产清单。在Refine中载入数据后很快就能发现笔误、分类不一致等前后矛盾的地方。也许fork(叉子)无意中被拼成了“frk”,或者你突然想到应该把所有的叉子、勺子和餐刀全部归为“餐具”类中。在Refine里面这些都很容易办到。如果你不喜欢刚刚作出的改动,用undo(撤销)命令就能让数据集恢复原状。
要想再深入一步,你还可以导入其他数据来源(比如Freebase里的数据集),从而创建一个更大的数据集。
Google Refine是一款很好的工具,它功能强大,而且提供免费下载。强烈建议大家至少一试。
►访问http://code.google.com/p/google-refine/,下载开源的Google Refine并浏览教程,学习如何最大限度地利用这款工具。
2.Mr. Data Converter
我们常常会发现,所有的数据都在Excel里面,但却需要把它们转换成其他格式。在为互联网创建数据图时这种情况尤其常见。你可能已经把Excel电子表格输出为CSV了,但如果需要其他格式该怎么办?Mr. Data Converter可以帮助你。
Mr. Data Converter是一款简单、免费的工具,创造者是Shan Carter,《纽约时报》的一名图形编辑。Carter的主要工作是为报纸的在线版本创建交互式数据图,所以他经常得把数据转换成他的软件所支持的格式。难怪他制作了这样一款工具。
图2-9显示了这款工具的界面,非常简单易用。你所要做的只是把Excel里面的数据复制粘贴到页面上方的文本框里面,然后选择想要的输入格式即可。有XML、JSON以及其他多种格式可选。
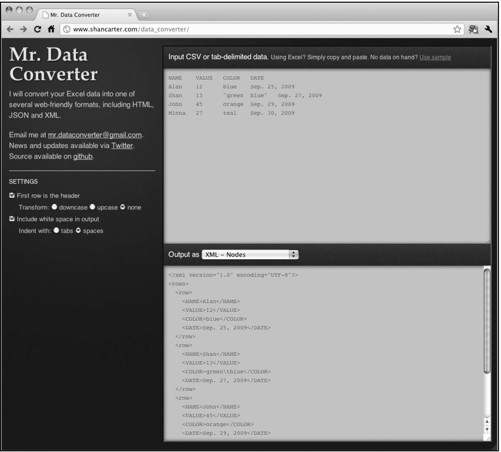
图2-9 Mr. Data Converter让数据格式之间的转换变得更加容易
如果你想对Mr. Data Converter加以扩展,它的源代码同样也是开放的。
►访问http://www.shancarter.com/data_converter/试用Mr. Data Converter,将你的Excel电子表格转换为Web友好的格式。或者到github下载源代码,地址是https://github.com/shancarter/Mr-Data-Converter。
3.Mr. People
受到Mr. Data Converter的启发,《纽约时报》的图形副主编Matthew Ericson创建了Mr. People。和Mr. Data Converter一样,Mr. People也允许在文本框中复制、粘贴数据,然后进行分析和提取工作。不过正如Mr. People这个名字所暗示的那样,它主要用于分析姓名。
也许你手里有一长列姓名数据,你想识别出其中的每一个姓氏和名字(包括中间名缩写、前缀和后缀),但是它们的格式却很混乱,很多姓名都被列在同一行中。这就是Mr. People能一显身手的地方。把所有的名字都复制粘贴到Mr. People里(参见图2-10),你就会得到一个非常干净的表格,可以复制到其他电子表格软件中去,如图2-11所示。
图2-10 Mr. People的姓名输入界面

图2-11 经过Mr. People分析后得到的姓名表格
和Mr. Data Converter一样,Mr. People也是一款开源软件,可在github上下载。
►访问http://people.ericson.net/使用Mr. People来对姓名进行分析,或者到http://github.com/mericson/people下载Ruby源文件,用在你自己的脚本里。
4.电子表格软件
当然了,如果你只是想排序,或者只是对某个数据点进行一些小改动,那么你还是可以用自己喜欢的那些电子表格软件。如果你不排斥手工编辑数据,这样做完全没问题。其他情况下,还是用之前提到的那些工具为好(尤其是当数据集非常庞大时),或者自己编程来解决。
2.2.3 用代码来格式化
虽然那些操作方便的软件确实能够带来帮助,但有时它们用起来还是谈不上得心应手。而且有些软件不善于应付大型数据,它们会变慢或者崩溃。
这种情况下你该怎么办呢?你可以放弃,但恐怕也于事无补。不过,你可以写一点代码来搞定这件事。有了代码的帮助,处理起来就会更加游刃有余,而且还能随时因地制宜地修改脚本。
现在让我们用一个实例来说明如何用几行代码实现数据格式之间的切换。
1. 实例:数据格式的切换
本例中使用的是Python,不过你也可以用其他任何喜欢的语言。所用的思路是一样的,但语法上可能会有所不同。(我喜欢用Python来开发应用,因此自然会选择用Python来处理原始数据。)
让我们接着用之前数据搜集时得到的wunder-data.txt文件,其中有纽约州布法罗市2009年的温度数据。最初的几行应该是这样:
- 20090101,26
- 20090102,34
- 20090103,27
- 20090104,34
- 20090105,34
- 20090106,31
- 20090107,35
- 20090108,30
- 20090109,25
- ...
这是个CSV文件,如果你希望数据是以下的XML格式:
- <weather_data>
- <observation>
- <date>2009010</date>
- <max_temperature>26</max_temperature>
- </observation>
- <observation>
- <date>20090102</date>
- <max_temperature>34</max_temperature>
- </observation>
- <observation>
- <date>20090103</date>
- <max_temperature>27</max_temperature>
- </observation>
- <observation>
- <date>20090104</date>
- <max_temperature>34</max_temperature>
- </observation>
- ...
- </weather_data>
其中每一天的温度数据都位于<observation>标签内,包括日期<date>和最高温<max_temperature>。
要想把CSV文件转换为这种XML格式,可以使用以下代码片段:
- import csv
- reader = csv.reader(open('wunder-data.txt', 'r'), delimiter=",")
- print '<weather_data>'
- for row in reader:
- print '<observation>'
- print '<date>' + row[0] + '</date>'
- print '<max_temperature>' + row[1] + '</max_temperature>'
- print '</observation>'
- print '</weather_data>'
和之前一样,首先你需要导入必要的模块。因为本例中读取的是CSV文件wunder-data.txt,所以我们只需要导入csv模块即可。
- import csv
第2行代码先通过open( )函数打开wunder-data.txt,然后通过csv.reader( )函数对其进行读取。
- reader = csv.reader(open('wunder-data.txt', 'r'), delimiter=",")
请注意分隔符被指定为一个逗号。如果文件是以制表符tab分隔,就需要指定分隔符为'\t'。
第3行代码的作用是输出XML文件的开篇第一行。
- print '<weather_data>'
在代码的主干部分,你可以在CSV文件中循环读取每一行数据,并输出所需要的XML。在本例中,CSV文件的每一行都对应XML中的一个<observation>标签。
- for row in reader:
- print '<observation>'
- print '<date>' + row[0] + '</date>'
- print '<max_temperature>' + row[1] + '</max_temperature>'
- print '</observation>'
每一行都有两个值:日期和最高温度。
最后将标签封闭,结束XML转换。
- print '</weather_data>'
这段代码主要完成两项任务。首先是读取数据,其次是循环处理,修改每一行数据的格式。如果想把生成的XML转换回CSV,整个思路也是一样的。正如以下代码片段所示,唯一的区别是需要另一个模块来分析XML文件。
- from BeautifulSoup import BeautifulStoneSoup
- f = open('wunder-data.xml', 'r')
- xml = f.read( )
- soup = BeautifulStoneSoup(xml)
- observations = soup.findAll('observation')
- for o in observations:
- print o.date.string + "," + o.max_temperature.string
这段代码看上去跟前面很不一样,但本质上做的是同一件事。我们没有再用csv模块,而是从BeautifulSoup库中输入了BeautifulStoneSoup模块。还记得我们曾用过BeautifulSoup模块来解析Weather Underground 网站的HTML吧?BeautifulStoneSoup则用于解析更为广泛的XML。
通过open( )函数打开XML文件,然后载入xml变量中的内容。此时xml内容会被存储为字符串的形式并传递到BeautifulStoneSoup。通过findAll( )函数获取所有的<observation>标签并进行循环分析。最后,和我们将CSV转换为XML的过程一样,循环所有的<observation>,将其中的值输出成我们需要的格式。
这样我们就得到了最开始的CSV文件:
- 20090101,26
- 20090102,34
- 20090103,27
- 20090104,34
- ...
为了加深大家的认识,下面提供了将CSV转换为JSON格式的代码。
- import csv
- reader = csv.reader(open('wunder-data.txt', 'r'), delimiter=",")
- print "{ observations: ["
- rows_so_far = 0
- for row in reader:
- rows_so_far += 1
- print '{'
- print '"date": ' + '"' + row[0] + '", '
- print '"temperature": ' + row[1]
- if rows_so_far < 365:
- print " },"
- else:
- print " }"
- print "] }"
你可以逐行阅读上面的代码,试着理解它们的意思。其实和之前一样,虽然输出的结果不同,但整个思路是一致的。以下是运行上面代码得到的JSON文件片段。
- {
- "observations": [
- {
- "date": "20090101",
- "temperature": 26
- },
- {
- "date": "20090102",
- "temperature": 34
- },
- ...
- ]
- }
数据还是那些数据,但是日期和温度却变成了另一种格式。计算机就是喜欢多样性。
2.在循环中加入新的逻辑
回顾一下将CSV文件转换为JSON时所用的代码,你应该会注意到在for循环中的三行print代码之后使用了if-else语句。它的作用是检查当前迭代是否已经到达最后一行数据。如果没有到达,该条记录的末尾就加上一个逗号;如果已经到达,则不加逗号。这是JSON规范中的一部分。实际上,在这里我们可以做更多事情。
我们可以检查最高温度是否大于某个临界值,比如创建一个新的值:1代表超过该临界值,0代表未超过。此举可以让我们对温度数据进行分类,或者标记出某些特殊的日子。
当然,我们能做的并不仅限于检查临界值。比如说可以计算某段时间内的流动平均温度,或者每天与前一天的温度差。要想拓展原始数据的用途,利用循环几乎可以随心所欲,不过先让我们看一个简单的例子。
让我们回到最初的CSV文件wunder-data.txt,通过代码创建第三列,指出当天的最高温度是高于还是低于冰点。0表示温度高于冰点(32°F以上),而1表示温度等于或低于冰点。
- import csv
- reader = csv.reader(open('wunder-data.txt', 'r'), delimiter=",")
- for row in reader:
- if int(row[1]) <= 32:
- is_freezing = '1'
- else:
- is_freezing = '0'
- print row[0] + "," + row[1] + "," + is_freezing
运行代码后,结果会直接显示在终端里。和之前一样,程序将CSV文件里的数据读取到Python中,然后循环处理每一行,检查对应的每一天并作标记。
这当然是一个很简单的例子,但从中不难发现,我们可以对这一逻辑进行扩展,从而随心所欲地拓展或格式化数据。只需记住载入、循环和处理这三个步骤即可。
