1.5.1 Spark在Amazon中的应用
亚马逊云计算服务AWS(Amazon Web Services)提供IaaS和PaaS服务。Heroku、Netflix等众多知名公司都将自己的服务托管其上。AWS以Web服务的形式向企业提供IT基础设施服务,现在通常称为云计算。云计算的主要优势是能够根据业务发展扩展的较低可变成本替代前期资本基础设施费用。利用云,企业无须提前数周或数月来计划和采购服务器及其他IT基础设施,即可在几分钟内即时运行成百上千台服务器,并更快达成结果。
1.亚马逊AWS云服务的内容
目前亚马逊在EMR中提供了弹性Spark服务,用户可以按需动态分配Spark集群计算节点,随着数据规模的增长,扩展自己的Spark数据分析集群,同时在云端的Spark集群可以无缝集成亚马逊云端的其他组件,一起构建数据分析流水线。
亚马逊云计算服务AWS提供的服务包括:亚马逊弹性计算云(Amazon EC2)、亚马逊简单存储服务(Amazon S3)、亚马逊弹性MapReduce(Amazon EMR)、亚马逊简单数据库(Amazon SimpleDB)、亚马逊简单队列服务(Amazon Simple Queue Service)、Amazon DynamoDB以及Amazon CloudFront等。基于以上的组件,亚马逊开始提供EMR上的弹性Spark服务。用户可以像之前使用EMR一样在亚马逊动态申请计算节点,可随着数据量和计算需求来动态扩展计算资源,将计算能力水平扩展,按需进行大数据分析。亚马逊提供的云服务中已经支持使用Spark集群进行大数据分析。数据可以存储在S3或者Hadoop存储层,通过Spark将数据加载进计算集群进行复杂的数据分析。
亚马逊AWS架构如图1-7所示。
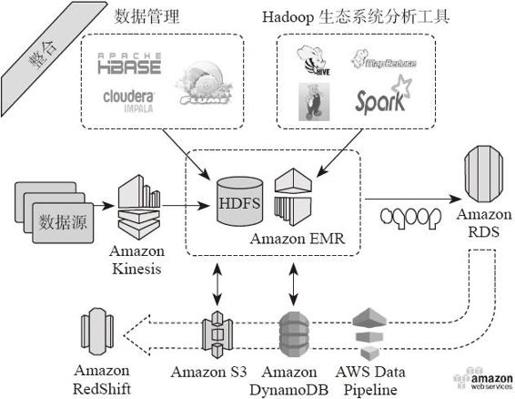
图1-7 亚马逊AWS架构
2.亚马逊的EMR中提供的3种主要组件
·Master Node:主节点,负责整体的集群调度与元数据存储。
·Core Node:Hadoop节点,负责数据的持久化存储,可以动态扩展资源,如更多的CPU Core、更大的内存、更大的HDFS存储空间。为了防止HDFS损坏,不能移除Core Node。
·Task Node:Spark计算节点,负责执行数据分析任务,不提供HDFS,只负责提供计算资源(CPU和内存),可以动态扩展资源,可以增加和移除Task Node。
3.使用Spark on Amazon EMR的优势
·构建速度快:可以在几分钟内构建小规模或者大规模Spark集群,以进行数据分析。
·运维成本低:EMR负责整个集群的管理与控制,EMR也会负责失效节点的恢复。
·云生态系统数据处理组件丰富:Spark集群可以很好地与Amazon云服务上的其他组件无缝集成,利用其他组件构建数据分析管道。例如,Spark可以和EC2 Spot Market、Amazon Redshift、Amazon Data pipeline、Amazon CloudWatch等组合使用。
·方便调试:Spark集群的日志可以直接存储到Amazon S3中,方便用户进行日志分析。
综合以上优势,用户可以真正按需弹性使用与分配计算资源,实现节省计算成本、减轻运维压力,在几分钟内构建自己的大数据分析平台。
4.Spark on Amazon EMR架构解析
通过图1-8可以看到整个Spark on Amazon EMR的集群架构。下面以图1-8为例,分析用户如何在应用场景使用服务。
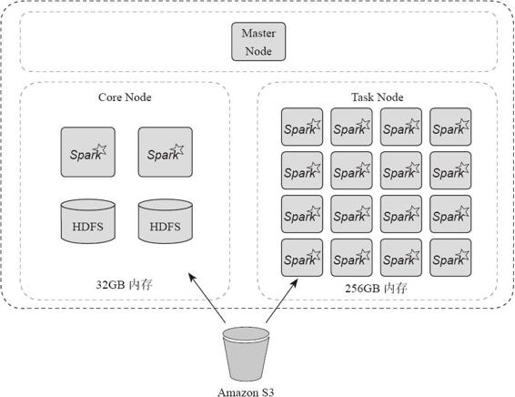
图1-8 Amazon Spark on EMR
构建集群,首先创建一个Master Node作为集群的主节点。之后创建两个Core Node存储数据,两个Core Node总共有32GB的内存。但是这些内存是不够Spark进行内存计算的。接下来动态申请16个Task Node,总共256GB内存作为计算节点,进行Spark的数据分析。
当用户开始分析数据时,Spark RDD的输入既可以来自Core Node中的HDFS,也可以来自Amazon S3,还可以通过输入数据创建RDD。用户在RDD上进行各种计算范式的数据分析,最终可以将分析结果输出到Core Node的HDFS中,也可以输出到Amazon S3中。
5.应用案例:构建1000个节点的Spark集群
读者可以通过下面的步骤,在Amazon EMR上构建自己的1000个节点的Spark数据分析平台。
1)启动1000个节点的集群,这个过程将会花费10~20分钟。
- ./elas2c-mapreduce --create –alive
- --name "Spark/Shark Cluster" \
- --bootstrap-ac2on
- s3://elasBcmapreduce/samples/spark/0.8.1/install-spark-shark.sh
- --bootstrap-name "Spark/Shark"
- --instance-type m1.xlarge
- --instance-count 1000
2)如果希望继续动态增加计算资源,可以输入下面命令增加Task Node。
- --add-instance-group TASK
- --instance-count INSTANCE_COUNT
- --instance-type INSTANCE_TYPE
执行完步骤1)或者1)、2)后,集群将会处于图1-9所示的等待状态。
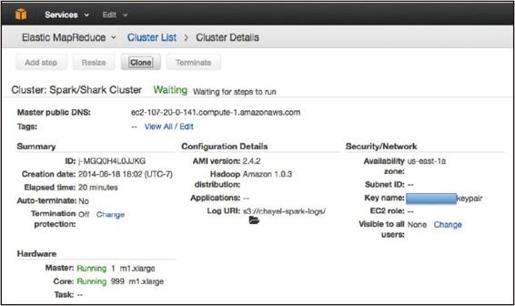
图1-9 集群细节监控界面
进入管理界面http://localhost:9091可以查看集群资源使用状况;进入http://localhost:8080可以观察Spark集群的状况。Lynx界面如图1-10所示。
3)加载数据集。
示例数据集使用Wiki文章数据,总量为4.5TB,有1万亿左右记录。Wiki文章数据存储在S3中,下载地址为s3://bigdata-spark-demo/wikistats/。
下面创建wikistats表,将数据加载进表:
- create external table wikistats
- (
- projectcode string,
- pagename string,
- pageviews int,
- pagesize int
- )
- ROW FORMAT
- DELIMITED FIELDS
- TERMINTED BY"
- LOCATION 's3n://bigdata-spark-demo/wikistats/';
- ALTER TABLE wikistats add partition(dt='2007-12')location 's3n://bigdata-spark-demo//wikistats/2007/2007-12';
- ......
图1-10 Lynx界面
4)分析数据。
使用Shark获取2014年2月的Top 10页面。用户可以在Shark输入下面的SQL语句进行分析。
- Select pagename,sum(pageviews) c from wikistats_cached where dt='2014-01'
- group by pagename order by c desc limit 10;
这个语句大致花费26s,扫描了250GB的数据。
云计算带来资源的按需分配,用户可以采用云端的虚机作为大数据分析平台的底层基础设施,在上端构建Spark集群,进行大数据分析。随着处理数据量的增加,按需扩展分析节点,增加集群的数据分析能力。
