9.2.2 内存存储优化
下面将从以下几个方面讲解内存存储的优化。[1]
1.JVM调优
内存调优过程的大方向上有三个方向是值得考虑的。
1)应用程序中对象所占用的内存空间。
2)访问这些内存对象的代价。
3)垃圾回收的开销。
通常状况下,Java的对象访问速度是很快的,但是相对于对象中存储的原始数据,Java对象整体会耗费2~5倍的内存空间。
(1)内存耗损原因
内存耗损是由以下几个原因造成的,熟悉JVM的用户可能会比较熟悉其中的原因。
1)不同的Java对象都会有一个对象头(object header),这个对象头大约为16byte,包含指向这个对象的类的指针等信息,对一些只有少量数据的对象,这是极为不经济的。例如,只有一个Int属性的对象,这个头的信息所占空间会大于对象的数据空间。
2)Java中的字符串(String)占用40byte空间。String的内存是将真正字符串的信息存储在一个char数组中,并且还会存储其他的信息,如字符串长度,同时如果采用UTF-16编码,一个字符就占用2byte的空间。综合以上,一个10字符的字符串会占用超过60byte的内存空间。
3)常用的一些集合类,如LinkedList等是采用链式数据结构存储的,对底层的每个数据项进行了包装,这个对象不只存储数据,还会存储指向其他数据项的指针,这些指针也会产生数据空间的占用和开销。
4)集合类中的基本数据类型常常采用一些装箱的对象存储,如java.lang.Ingeger。装箱与拆箱的机制在很多程序设计语言中都有,Java中装箱意味着将这些基本数据类型包装为对象存储在内存的Java堆中,而拆箱意味着将堆中对象转换为栈中存储的数据。
(2)计算内存的消耗
计算数据在集群内存占用的空间的大小的最好方法是创建一个RDD,读取这些数据,将数据加载到cache,在驱动程序的控制台查看SparkContext的日志。这些日志信息会显示每个分区占用多少空间(当内存空间不够时,将数据写到磁盘上),然后用户可以根据分区的总数大致估计出整个RDD占用的空间。例如,下面的日志信息。
- INFO BlockManagerMasterActor: Added rdd_0_1 in memory on mbk.local:50311 (size: 717.5 KB, free: 332.3 MB)
这表示RDD0的partition1消耗了717.5KB内存空间。
(3)调整数据结构
减少内存消耗的第一步就是减少一些除原始数据以外的Java特有信息的消耗,如链式结构中的指针消耗、包装数据产生的元数据消耗等。
1)在设计和选用数据结构时能用数组类型和基本数据类型最好,尽量减少一些链式的Java集合或者Scala集合类型的使用。可以采用fastutil这个第三方库,其中有很多对基本数据类型的集合,能够基本覆盖大部分的Java标准库集合和数据类型。官网地址为http://fastutil.di.unimi.it/。
2)减少对象嵌套。例如,使用大量数据量小、个数多的对象和内含指针的集合数据结构,这样会产生大量的指针和对象头元数据的开销。《编程之美》中提出的“程序简单就是美”的思想在这里也能够体现,不是数据结构设计多复杂,这个程序就多好,而是能解决问题,采用的数据结构又很简单,代码量小,开销小,这样才是最见功力的。
3)考虑使用数字的ID或者枚举对象,而不是使用字符串作为key键的数据类型。从前面也看到,字符串的元数据和本身的字符编码问题产生的空间占用过大。
4)当内存小于32GB时,官方推荐配置JVM参数-XX:+UseCompressedOops,进而将指针由8byte压缩为4byte。OOP的全称是ordinary object pointer,即普通对象指针。在64位HotSpot中,OOP使用32位指针,默认64位指针会比32位指针使用的内存多1.5倍,启用CompressOops后,会压缩的对象如下。
①每个Class的属性指针(静态成员变量)。
②每个对象的属性指针。
③普通对象数组每个元素的指针。
但是,指向PermGen的Class对象指针、本地变量、堆栈元素、入参、返回值、NULL指针不会被压缩。可以通过配置文件spark-env.sh配置这个参数,从而在Spark中启用JVM指针压缩。
(4)序列化存储RDD
如果通过上面的优化方式进行优化,对象存储空间仍然很大,一个更加简便的减少内存消耗的方法是以序列化的格式来存储这些对象。在程序中可以通过设置StorageLevels这个枚举类型来配置RDD的数据存储方式,官网的API文档中提供了更为丰富的RDD存储方式,有兴趣的读者可以自行学习参考。例如,当配置RDD为MEMORY_ONLY_SER存储方式时,Spark将这个RDD的每个分区存储为一个大的byte数组。当然这也是一个权衡的过程,这样的存储会带来数据访问变慢的问题,这是由于每次访问数据还需要经过反序列化的过程。用户如果希望在内存中缓存数据,则官方推荐使用Kyro的序列化库进行序列化,因为Kyro相比于Java的标准序列化库序列化后的对象占用空间更小,性能更好。
(5)JVM垃圾回收(GC)调优
当Spark程序产生大数据量的RDD时,JVM的垃圾回收就会成为一个问题。当JVM需要替换和回收旧对象所占空间来为新对象提供存储空间时,根据JVM垃圾回收算法,JVM将遍历所有Java对象,然后找到不再使用的对象进而回收。这里其实开销最大的因素是程序中使用了大量的对象,所以设计数据结构时应该尽量使用创建更少的对象的数据结构,如尽量采用数组Array,而少用链表的LinkedList,从而减少垃圾回收开销。更好的一个方式是将数据缓存为序列化的形式,这些将在序列化的优化方法中详细介绍,这样只有一个对象,即一个byte数组作为一个RDD的分区存储。当遇到GC(垃圾回收)问题时,首先考虑用序列化的方式尝试解决。
当Spark任务的工作内存空间和RDD的缓存数据空间产生干扰时,垃圾回收同样会成为一个问题,可以通过控制分给RDD的缓存来缓解这个问题。
1)度量GC的影响。
GC调优的第一步是统计GC的频率和GC的时间开销。可以设置spark-env.sh中的SPARK_JAVA_OPTS参数,添加选项-verbose:gc-XX:+PrintGCDetails-XX:+PrintGCTime-Stamps。当用户下一次的Spark任务运行时,将会看到worker的日志信息中出现打印GC的时间等信息,需要注意的是,这些信息都Worker节点显示,而不在驱动程序的控制台显示。
2)缓存大小调优。
对GC来说,一个重要的配置参数就是内存给RDD用于缓存的空间大小。默认情况下,Spark用配置好的Executor 60%的内存(spark.executor.memory)缓存RDD。这就意味着40%的剩余内存空间可以让Task在执行过程中缓存新创建的对象。在有些情况下,用户的任务变慢,而且JVM频繁地进行垃圾回收或者出现内存溢出(out of memory异常),这时可以调整这个百分比参数为50%。这个百分比参数可以通过配置spark-env.sh中的变量spark.storage.memoryFraction=0.5进行配置。同时结合序列化的缓存存储对象减少内存空间占用,将会更加有效地缓解垃圾回收问题。下面介绍一些高级GC调优技术。图9-1为Java堆中的各代内存分布。
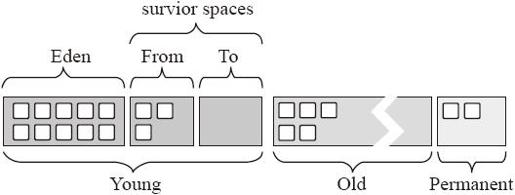
图9-1 JVM内存分布
①Young(年轻代)。
年轻代分为3个区:一个Eden区和两个Survivor区(Survivor Space)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当一个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满时,从第一个Survivor区复制过来的且还存活的对象,将被复制Tenured(老年)区。需要注意的是,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden区复制过来的对象和从前一个Survivor区复制过来的对象,而复制到年老区的只有从第一个Survivor区过来的对象。而且,Survivor区总有一个是空的。大多数情况下Java程序新建的对象都是从新生代分配内存。
不同的GC方式会以不同的方式按此值来划分Eden区和Survivor区的大小,有的GC还会根据运行情况动态调整这3个区的大小。
②Tenured(年老代)。
年老代存放从年轻代存活的对象。一般来说,年老代存放的都是生命期较长的对象。
③Perm(持久代)。
持久代用于存放静态文件、Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,这时需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小可通过-XX:MaxPermSize=设置。
持久代对应内存模型中的方法区,存放了加载类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的field信息、类中的方法信息,开发人员通过反射机制访问该区域。在sun jdk中,该区默认的最小值为16MB,最大值为64MB,可以通过-XX:PermSize和-XX:MaxPermSize来指定最小值和最大值。
3)全局GC调优。
Spark中全局的GC调优要确保只有存活时间长的RDD存储在老年代(Old generation)区域,这样保证年轻代(Young)有足够的空间存储存活时间短的对象。这有助于减少Spark任务执行时需要给数据分配的空间,用户可以通过下面的方法观察和解决full GC问题。
可以通过观察日志信息查看是否存在过多过频繁的GC。如果full GC在任务执行完成之前被触发多次,就表示对正在执行的任务没有足够的内存空间分配。
如果从打印的GC日志来看,老年代将要满了,就应该减少缓存数据的内存使用量,可以通过配置spark.storage.memoryFraction属性进行配置,缓存更少的对象还是比减慢内存执行时间更加经济。下面具体讲解spark.storage.memoryFraction属性。
spark.storage.memoryFraction控制用于Spark缓存的Java堆空间,默认值为0.67,即2/3的Java堆空间用于Spark的缓存。如果任务的计算过程中需要用到较多的内存,而RDD所需内存较少,就可以调低这个值,以减少计算过程中因为内存不足而产生的GC过程。在调优过程中发现,GC过多是导致任务运行时间较长的一个常见原因。如果任务运行较慢,想确定是否是GC太多导致的,可以在spark-env.sh中设置JAVA_OPTS参数,以打印GC的相关信息,设置如下。
- JAVA_OPTS=" -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
这样如果有GC发生,就可以在master和work的日志上看到。
下面通过源码看看这个参数是怎样发挥作用的。
在BlockManager中对memoryFraction
- private def getMaxMemory(conf: SparkConf): Long = {
- val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
- (Runtime.getRuntime.maxMemory * memoryFraction).toLong
- }
如果看到GC日志中有很多minor GC信息,而非major GC信息,分配更多的内存给Eden区将会很有帮助。可以设定估计出的每个任务执行需要的内存为Eden区内存大小。如果已经设置Eden区内存大小为E,就可以通过JVM配置参数-Xmn=4/3*E设置年轻代大小,多出的空间分配给Survivor区域使用。
例如,如果任务是从HDFS读取数据,内存空间的占用可以通过从HDFS读取的数据块大小和数量估计。需要注意的是,一般情况下,压缩的数据压缩之后通常为原来数据块大小的2~3倍。因此如果一个JVM中要执行3~4个任务,同时HDFS的数据块大小是64MB,就可以估计需要的Eden代大小是4×3×64MB大小的空间。
最后监控修改了配置参数之后,Spark应用的GC频率和时间开销,进一步调优。
官方给出的GC调优建议是,GC调优依赖于两个关键因素:应用程序和集群能够提供的可用内存大小。在Oracle的官网(http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html)上有更多高级的GC调优方法。不论怎样减少GC的频度,都可以明显减少开销。
2.OOM问题优化
相信有一定Spark或者Hadoop开发经验的用户或多或少都遇到过OutOfMemoryError内存溢出问题。
通过之前的介绍,读者已经对JVM的内存管理有了大致的了解,JVM管理大致分为这几个区域:permanent generation space(持久代区域)、heap space(堆区域)、Java stacks(Java栈)。
持久代区域主要存放类和元数据信息,Class第一次加载时被放入PermGen space区域,Class需要存储的内容主要包括方法和静态属性。
堆区域用来存放对象,对象需要存储的内容主要是非静态属性,包括年轻代和年老代。每次用new创建一个对象实例后,对象实例存储在堆区域中,这部分空间也由JVM的垃圾回收机制管理。
Java栈与大多数编程语言,包括汇编语言的栈功能相似,主要存储基本类型变量以及方法的输入输出参数。Java程序的每个线程中都有一个独立的堆栈,然后值类型会存储在栈上。
容易发生内存溢出问题的内存空间包括permanent generation space(持久代空间)和heap space(堆空间),笔者常遇到的情景就是heap space的问题。
发生内存溢出问题的原因是Java虚拟机创建的对象太多,在进行垃圾回收时,虚拟机分配到的堆内存空间已经用满了,与heap space有关。解决这类问题有两种思路,一种是减少App的内存占用消耗,另一种是增大内存资源的供给,具体的做法如下。
1)检查程序,看是否有死循环或不必要重复创建大量对象的地方。找到原因后,修改程序和算法。有很多Java profile工具可以使用,官方推荐的是YourKit其他还有JvisualVM、Jcohsole等工具可以使用。
2)按照之前内存调优中总结的能够减少对象在内存数据存储空间的方法开发程序开发和配置参数。
3)增加Java虚拟机中Xms(初始堆大小)和Xmx(最大堆大小)参数的大小,如set JAVA_OPTS=-Xms256m-Xmx1024m。
引起这个问题的原因还很可能是Shuffle类操作符在任务执行过程中在内存建立的Hash表过大。在这种情况下,可以通过增加任务数,即分区数来提升并行性度,减小每个任务的输入数据,减少内存占用来解决。
3.磁盘临时目录空间优化
配置参数spark.local.dir能够配置Spark在磁盘的临时目录,默认是/tmp目录。在Spark进行Shuffle的过程中,中间结果会写入Spark在磁盘的临时目录中,或者当内存不能够完全存储RDD时,内存放不下的数据会写到配置的磁盘临时目录中。
这个临时目录设置过小会造成No space left on device异常。也可以配置多个盘块spark.local.dir=/mn1/spark,/mnt2/spar,/mnt3/spark来扩展Spark的磁盘临时目录,让更多的数据可以写到磁盘,加快I/O速度。
[1] 参考自http://spark.apache.org/docs/latest/tuning.html#memory-tuning ,Spark官网。
