7.1.2 Hadoop GridMix
作为Hadoop自带的Benchmark,Gridmix同样不支持Spark,用户要使用Spark,仍需自己实现Workload算法。作为Hadoop自带的测试工具,使用方便、负载经典,所以应用广泛。
Gridmix的使用用例不能代表所有的Hadoop使用场景。Gridmix的用例中,没有包括较为复杂的计算,也没有明显的CPU密集型的用例。而现实应用中,存在很多I/O密集型的应用,同时CPU密集型的应用也大量存在,如机器学习算法、构建倒排索引等。因此,Gridmix的WorkLoad负载并不能完全展现大数据工作负载的全貌。[1]表7-3为Gridmix负载的介绍。
表7-3 Gridmix所包含的负载
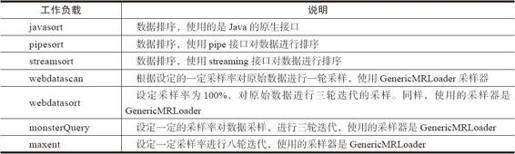
[1] 参见:http://baidutech.blog.51cto.com/4114344/743496,HCE Benchmark.51CTO博客,2011-02-11。
