5.2 远程调试Spark程序
本地调试Spark程序和传统的调试单机的Java程序基本一致,读者可以参照原来的方式调试,关于单机调试本书暂不介绍。对于远程调试服务器上的Spark代码,首先确保在服务器和本地的Spark版本一致。需按前文介绍的方法预先安装好JDK和git。
1.编译Spark
在服务器端和本地计算机下载Spark项目。
通过下面命令克隆一份Spark源码。
- git clone https://github.com/apache/spark
然后针对指定的Hadoop版本进行编译。配置代码如下:
- SPARK_HADOOP_VERSION=2.3.0 sbt/sbt assembly
2.在服务器端的配置
1)根据相应的Spark配置指定版本的Hadoop并启动Hadoop。
2)对编译好的Spark进行配置,在conf/spark-env.sh文件中进行如下配置。下面代码配置了Spark调试所需的Java参数。
- export SPARK_JAVA_OPTS=" -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=9999"
其中suspend=y表示设置为需要挂起的模式。这样,当启动Spark的作业时,程序会自动挂起,等待本地的IDE附加(attach)到被调试的应用程序上。address后接的是开放等待连接的端口号。
3.启动Spark集群和应用程序
1)启动Spark集群。
- ./sbin/start-all.sh
2)启动需要调试的程序,以Spark中自带的HdfsWordCount为例。
- MASTER=spark://10.10.1.168:7077 ./bin/run-example org.apache.spark.examples.streaming.HdfsWordCount hdfs://localhost:9000/test/test.txt
执行后程序挂起,并等待本地的Intellij进行连接,如图5-12所示。

图5-12 远程调试
4.配置本地IDE
配置并连接服务器端挂起的程序。
在Intellij中点击run→edit configuration,在弹出的Run/Debug Configuration界面中选择remote,在默认配置中将端口号Port设置为9999,将主机IP地址的Host改为服务器的地址10.10.1.168,同时用选择Debugger mode为Attach(附加)方式,如图5-13所示。
选择附加方式后,在程序中设置断点即可进行调试。
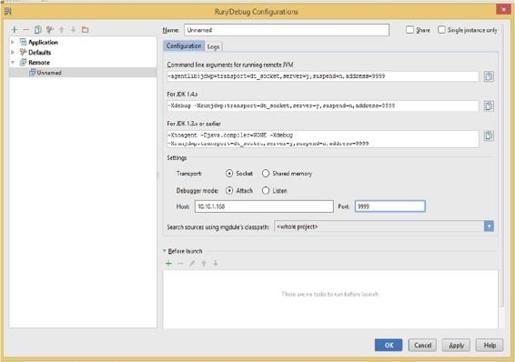
图5-13 远程调试设置
