7.1.1 Intel Hibench与Berkeley BigDataBench
首先来介绍Hibench。
1.Hibench
Hibench[1]是由Intel开发的一个针对Hadoop的基准测试工具。它包含有一组Hadoop工作负载的集合,有人工模拟实验环境的工作负载,也有一部分是生产环境的Hadoop应用程序。Hibench是广泛应用的Hadoop Benchmark。因为Hibench针对Hadoop,如果想使用其作为Spark的Benchmark,则需要自己针对数据集开发一些Workload算法。Hibench是开源的,用户可以到Github库中下载:https://github.com/intel-hadoop/HiBench。
Hibench包含的负载如表7-1所示。
表7-1 Hibench所包含的负载

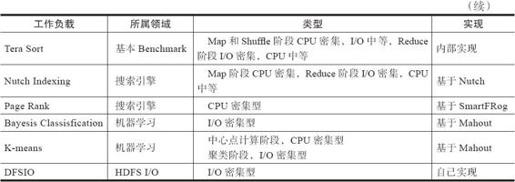
下面介绍在Hibench的基础上衍生出的一款新的Big Data Benchmark。
2.Berkeley BigDataBench
Berkeley BigDataBench[2]是随着Spark、Shark的推出,由AMPLab开发的一套大数据基准测试工具。由于其一部分是基于Hibench的数据集和数据生成器,所以将二者放在一起介绍,同时它有一部分数据集是Common Crawl上采样的文档数据集,这点和Hibench不同。其目前主要针对SQL on Hadoop产品进行基准测试。现在还很简陋,不排除以后还会增加对Spark和其他Spark生态系统组件的支持。感兴趣的读者可以到官方主页(https://amplab.cs.berkeley.edu/benchmark/)了解更多内容。
现在支持Documents、Ranking和UserVisits 3个数据集,这3个数据集的模式,如表7-2所示。
表7-2 3个数据集的模式
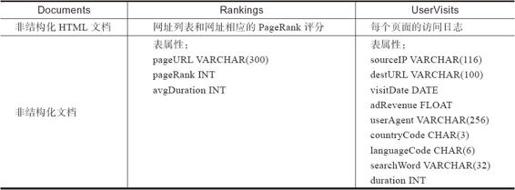
为了便于广大用户理解工作负载,BigDataBench选用了SQL作为测试的工作负载,而没有选择机器学习、流计算和图计算等工作负载。
下面简要介绍Berkely BigData Benchmark工作负载。
(1)Scan Query
- SELECT pageURL, pageRank FROM rankings WHERE pageRank > X
这个查询的目的是对关系表进行选择和投影操作。
(2)Aggregation Query
- SELECT SUBSTR(sourceIP, 1, X), SUM(adRevenue) FROM uservisits GROUP BY SUBSTR(sourceIP, 1, X)
这个查询的目的是先对关系表分组,然后使用字符串解析的函数对每个元组进行解析,最后进行一个高基数的聚集函数操作。
(3)Join Query
- SELECT sourceIP, totalRevenue, avgPageRank
- FROM
- (SELECT sourceIP,
- AVG(pageRank) as avgPageRank,
- SUM(adRevenue) as totalRevenue
- FROM Rankings AS R, UserVisits AS UV
- WHERE R.pageURL = UV.destURL
- AND UV.visitDate BETWEEN Date(`1980-01-01') AND Date(`X')
- GROUP BY UV.sourceIP)
- ORDER BY totalRevenue DESC LIMIT 1
这个查询使用大小表连接,然后对结果进行排序。因为很多SQL on Hadoop产品都是基于Map Reduce计算模型,所以这里涉及一个经典的优化方式是Map Side Join,可以避免Shuffle阶段的网络开销。
(4)External Script Query
- CREATE TABLE url_counts_partial AS
- SELECT TRANSFORM (line)
- USING "python /root/url_count.py" as (sourcePage, destPage, cnt)
- FROM documents;
- CREATE TABLE url_counts_total AS
- SELECT SUM(cnt) AS totalCount, destPage
- FROM url_counts_partial
- GROUP BY destPage;
在这个查询中,调用一个会抽取和聚集URL信息的Python外部函数,然后分组聚集整个URL的数量。
[1] 感兴趣的读者可参见:http://baidutech.blog.51cto.com/4114344/743496,HCE Benchmark.51CTO博客,2011-02-11。还可参见论文:Shengsheng Huang, Jie Huang, Yan Liu and Jinquan Dai,HiBench: A Representative and Comprehensive Hadoop Benchmark Suite。
[2] 参见:https://amplab.cs.berkeley.edu/benchmark/,参考自amplab对Benchmark的相关论述。
