8.3.3 GraphX架构
1.整体架构
GraphX的整体架构可以分为以下3部分,如图8-21所示。
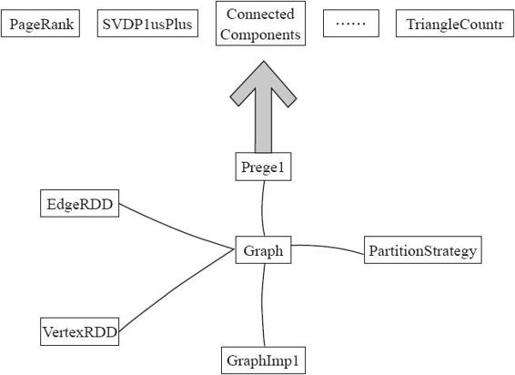
图8-21 GraphX架构
1)存储和原语层:Graph类是图计算的核心类,内部含有VertexRDD、EdgeRDD和RDD[EdgeTriplet]引用。GraphImpl是Graph类的子类,实现了图操作。
2)接口层:在底层RDD的基础之上实现了Pregel模型、BSP模式的计算接口。
3)算法层:基于Pregel接口实现了常用的图算法。包括:PageRank、SVDPlusPlus、TriangleCount、ConnectedComponents、StronglyConnectedConponents等算法。
2.存储结构
在正式的工业级应用中,图的规模极大,上百万个节点经常出现。为了提高处理速度和数据量,希望能够将图以分布式的方式来存储、处理图数据。图的分布式存储大致有两种方式:边分割(edge cut)和点分割(vertex cut),如图8-22所示。最早期的图计算的框架中,使用的是边分割存储方式,而GraphX的设计者考虑到真实世界中的大规模图典型地是边多于点的图,所以采用点分割方式存储。点分割能够减少网络传输和存储开销。底层实现是将边放到各个节点存储,而在数据交换时,将点在各个机器之间广播进行传输。对边进行分区和存储的算法主要基于PartitionStrategy中封装的分区方法。其中的几种分区方法分别是对不同应用情景的权衡,用户可以根据具体的需求,在程序中指定边的分区方式。例如:
- val g = Graph(vertices, partitionBy(
- edges, PartitionStrategy.EdgePartition2D))
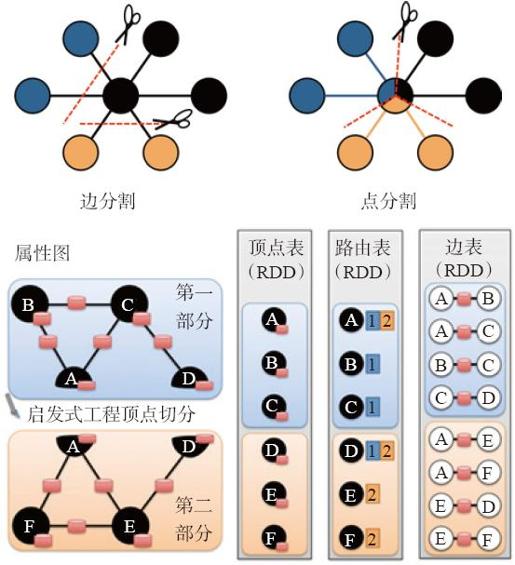
图8-22 GraphX存储模型
一旦边已经在集群上分区和存储,大规模并行图计算的关键挑战就变成了如何将点的属性连接到边。GraphX的处理方式是在集群上移动传播点的属性数据。由于不是每个分区都需要所有点的属性(因为每个分区只是一部分边),GraphX内部维持一个路由表(routing table),这样当需要广播点到需要这个点的边的所在分区时,就可以通过路由表映射,将需要的点属性传输到指定的边分区。
点分割的好处是在边的存储上没有冗余数据,而且对于某个点与其邻居的交互操作,只要满足交换律和结合律即可。例如,求顶点的邻接顶点权重的和,可以在不同的节点进行并行运算,最后汇总每个节点的运行结果,网络开销较小。代价是每个顶点属性可能要冗余存储多份,需要更新点数据时,要有数据同步开销。
3.使用技巧
采样观察可以通过不同的采样比例,先从小数据量进行计算,观察效果,调整参数,再逐步增加数据量进行大规模的运算。可以通过RDD的sample方法采样,通过Web UI观察集群的资源消耗。
1)内存释放:保留旧图对象的引用,并尽快释放不使用的图的顶点属性,节省空间占用。通过方法unPersistVertices释放顶点。
2)GC调优,请参考性能调优章节的内容。
3)调试:在各个时间点可以通过graph.vertices.count()进行调试,观测图现有状态,进行问题诊断和调优。
