3.3.2 Key-Value型Transformation算子
Transformation处理的数据为Key-Value形式的算子,大致可以分为3种类型:输入分区与输出分区一对一、聚集、连接操作。
1.输入分区与输出分区一对一
mapValues:针对(Key,Value)型数据中的Value进行Map操作,而不对Key进行处理。
图3-19中的方框代表RDD分区。a=>a+2代表只对(V1,1)数据中的1进行加2操作,返回结果为3。
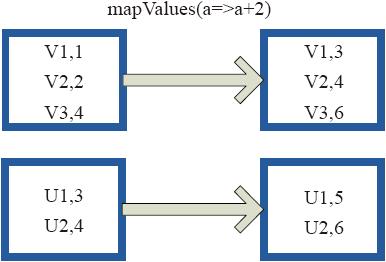
图3-19 mapValues算子RDD对转换
2.对单个RDD或两个RDD聚集
(1)单个RDD聚集
1)combineByKey。
定义combineByKey算子的代码如下。
- combineByKey[C](createCombiner:(V)=> C,
- mergeValue:(C, V)=> C,
- mergeCombiners:(C, C)=> C,
- partitioner: Partitioner
- mapSideCombine: Boolean = true,
- serializer: Serializer =null): RDD[(K, C)]
说明:
·createCombiner:V=>C,在C不存在的情况下,如通过V创建seq C。
·mergeValue:(C,V)=>C,当C已经存在的情况下,需要merge,如把item V加到seq C中,或者叠加。
·mergeCombiners:(C,C)=>C,合并两个C。
·partitioner:Partitioner(分区器),Shuffle时需要通过Partitioner的分区策略进行分区。
·mapSideCombine:Boolean=true,为了减小传输量,很多combine可以在map端先做。例如,叠加可以先在一个partition中把所有相同的Key的Value叠加,再shuffle。
·serializerClass:String=null,传输需要序列化,用户可以自定义序列化类。
例如,相当于将元素为(Int,Int)的RDD转变为了(Int,Seq[Int])类型元素的RDD。
图3-20中的方框代表RDD分区。通过combineByKey,将(V1,2)、(V1,1)数据合并为(V1,Seq(2,1))。
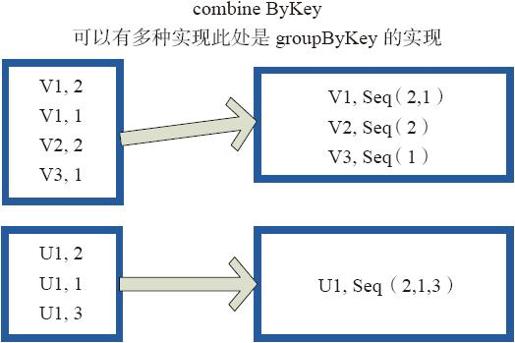
图3-20 comBineByKey算子对RDD转换
2)reduceByKey。
reduceByKey是更简单的一种情况,只是两个值合并成一个值,所以createCombiner很简单,就是直接返回v,而mergeValue和mergeCombiners的逻辑相同,没有区别。
函数实现代码如下。
- def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = {
- combineByKey[V]((v: V) => v, func, func, partitioner)
- }
图3-21中的方框代表RDD分区。通过用户自定义函数(A,B)=>(A+B),将相同Key的数据(V1,2)、(V1,1)的value相加,结果为(V1,3)。
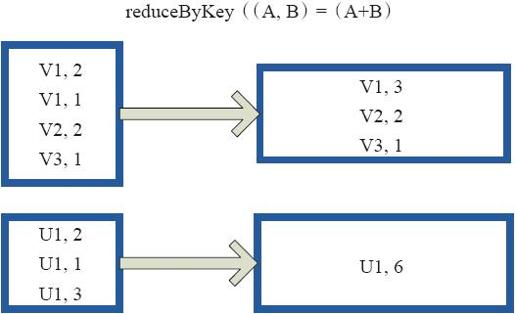
图3-21 reduceByKey算子对RDD转换
3)partitionBy。
partitionBy函数对RDD进行分区操作。
函数定义如下。
- partitionBy(partitioner:Partitioner)
如果原有RDD的分区器和现有分区器(partitioner)一致,则不重分区,如果不一致,则相当于根据分区器生成一个新的ShuffledRDD。
图3-22中的方框代表RDD分区。通过新的分区策略将原来在不同分区的V1、V2数据都合并到了一个分区。
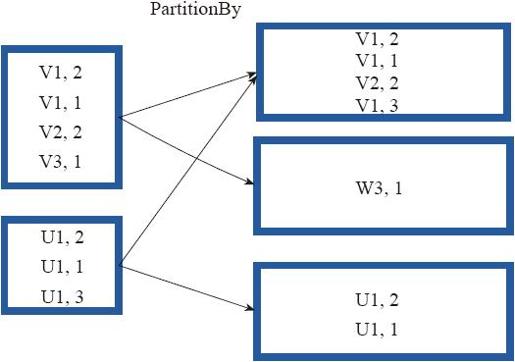
图3-22 partitionBy算子对RDD转换
(2)对两个RDD进行聚集
cogroup函数将两个RDD进行协同划分,cogroup函数的定义如下。
- cogroup[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))]
对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。
- (K, (Iterable[V], Iterable[W]))
其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。
图3-23中的大方框代表RDD,大方框内的小方框代表RDD中的分区。将RDD1中的数据(U1,1)、(U1,2)和RDD2中的数据(U1,2)合并为(U1,((1,2),(2)))。
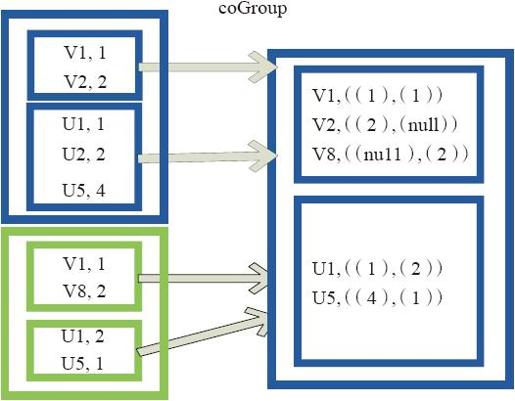
图3-23 Cogroup算子对RDD转换
3.连接
(1)join
join对两个需要连接的RDD进行cogroup函数操作,cogroup原理请见上文。cogroup操作之后形成的新RDD,对每个key下的元素进行笛卡尔积操作,返回的结果再展平,对应Key下的所有元组形成一个集合,最后返回RDD[(K,(V,W))]
下面代码为join的函数实现,本质是通过cogroup算子先进行协同划分,再通过flatMapValues将合并的数据打散。
- this.cogroup(other, partitioner).flatMapValues { case (vs, ws) =>
- for (v <- vs; w <- ws) yield (v, w) }
图3-24是对两个RDD的join操作示意图。大方框代表RDD,小方框代表RDD中的分区。函数对拥有相同Key的元素(例如V1)为Key,以做连接后的数据结果为(V1,(1,1))和(V1,(1,2))。
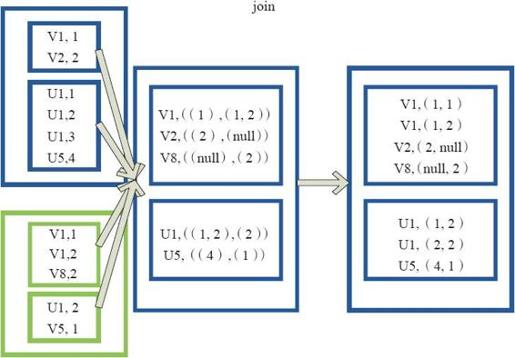
图3-24 join算子对RDD转换
(2)leftOutJoin和rightOutJoin
LeftOutJoin(左外连接)和RightOutJoin(右外连接)相当于在join的基础上先判断一侧的RDD元素是否为空,如果为空,则填充为空。如果不为空,则将数据进行连接运算,并返回结果。
下面代码是leftOutJoin的实现。
- if (ws.isEmpty) {
- vs.map(v => (v, None))
- } else {
- for (v <- vs; w <- ws) yield (v, Some(w))
- }
