8.1.3 Shark简介
下面介绍Shark的架构,如图8-5所示。在整体架构中,Shark复用了Hive Metastore、Hive SerDe,以及查询解析器和优化器,但是用Spark重写了Hive的执行Operator,并实现了基于内存的优化策略。最初Shark为了学术使命,复用Hive的查询优化器,虽然缩短了开发周期,但是这样不得不维护一个单独的Hive分支用来支持Shark,随着系统复杂性的提升,优化策略的不断扩充,维持Hive的查询优化器已经代价太大,最终Databricks宣布终止Shark开发。

图8-5 Shark架构
1.执行流程
Shark读取用户的查询表达式,运用Hive的解析器和查询优化器形成查询树进行语法解析和逻辑物理优化,最终形成等待执行的执行计划。执行器遍历执行计划树到叶子节点的Operator执行,执行后再回溯到父母节点继续执行,直到完全执行完整个查询计划。Operator中不再用Hadoop的MapReduce进行分布式计算,而是用Spark重写Operator进行分布式计算。
2.容错性
Spark记录了RDD的Lineage,即RDD的依赖关系,功能类似于传统数据库中的redo日志的功能。当有分区丢失或者出错时,Spark可以从源头的基础数据重做运算恢复分区数据。这也是和Impala进行对比的一个优势,Impala如果任务失败,则需要整体重做全部任务。
3.多数据计算范式混合
Shark和其他SQL on Hadoop产品对比的一大优势还源于其可以和其他多种计算范式混合计算。使用Shark通过SQL建立内存表,既可以通过MLlib进行Machine Learning的运算,又可以用GraphX进行大规模图计算,等等,使用户方便地进行一站式数据流水线计算,而不需要有一个持久化层,如HDFS暂存中间数据。无疑会大幅度减少性能开销,同时提升开发效率和复杂度,更减少了不同系统间兼容的代价。
下面看一个SQL和机器学习结合的例子。
进入Spark Shell进行交互式查询,方便用户迅速实现想法。
- $./bin/shark-shell
- /* 通过SparkContext的SQL2rdd方法运行SQL查询,从Shark中读出表并在内存建立RDD */
- scala> val youngUsers = sc.SQL2rdd("SELECT * FROM users WHERE age < 20")
- /* 对内存youngUsers的RDD进行map,将数据提取要进行Machine Learning的feature*/
- scala> val featureMatrix = youngUsers.map(extractFeatures(_))
- /* 调用MLlib中的kmeans进行用户数据聚类*/
- scala> kmeans(featureMatrix)
我们看到通过短短几行代码就实现了SQL和机器学习的运算需求。
4.性能对比
如图8-6所示,从最新的伯克利Big Data Benchmark上的一个例子可以看到:这个查询的执行首先解析每个元组的应用字符串,然后进行一次高基数的聚集函数运算。由于UserVistits表有些列没有用到,Redshift的列存储只读需要的数据体现了优势。同时Shark在内存也是基于列存储,从两者的对比看来,Shark的性能瓶颈在于字符串解析。再看Impala,由于Impala是从操作系统的cache读数据,它就需要读和解压缩整个行,造成和Shark相比有一定的劣势,但是Impala相比Shark应用了更加高效的编译后的执行代码,比Shark有一定的优势,这两个因素造成Impala和Shark达到差不多的处理内存表的吞吐量。对大的结果集来说,Impala会由于物化输出表造成更高的延迟。
- Aggregation Query
- SELECT SUBSTR (sourceIP, 1, X), SUM (adRevenue) FROM uservisits GROUP BY SUBSTR (sourceIP, 1, X)
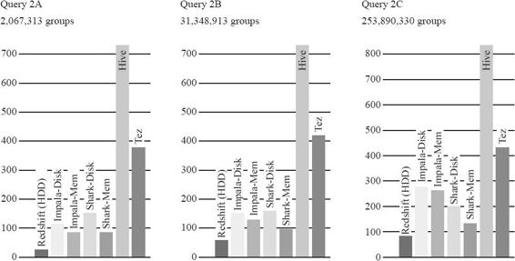
图8-6 Shark等SQL on Hadoop测试对比
综合看来,Spark SQL和Shark相比其他SQL on Hadoop产品存在以下几点优势。
1)依托内存计算框架Spark,利用内存计算大幅度提升性能。
2)支持Spark Shell进行交互式查询,使用户想法可以快速实现。
3)依托Spark生态系统,可以方便地构建全栈数据解决方案。
