3.3.3 Actions算子
本质上在Actions算子中通过SparkContext执行提交作业的runJob操作,触发了RDD DAG的执行。
例如,Actions算子collect函数的代码如下,感兴趣的读者可以顺着这个入口进行源码剖析。
- /*返回这个RDD的所有数据,结果以数组形式存储*/
- def collect(): Array[T] = {
- /*提交Job*/
- val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
- Array.concat(results: _*)
- }
下面根据Action算子的输出空间将Action算子进行分类:无输出、HDFS、Scala集合和数据类型。
1.无输出
(1)foreach
对RDD中的每个元素都应用f函数操作,不返回RDD和Array,而是返回Uint。
图3-25表示foreach算子通过用户自定义函数对每个数据项进行操作。本例中自定义函数为println(),控制台打印所有数据项。
2.HDFS
(1)saveAsTextFile
函数将数据输出,存储到HDFS的指定目录。
下面为函数的内部实现。
- this.map(x => (NullWritable.get(), new Text(x.toString)))
- .saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
将RDD中的每个元素映射转变为(Null,x.toString),然后再将其写入HDFS。
图3-26中左侧的方框代表RDD分区,右侧方框代表HDFS的Block。通过函数将RDD的每个分区存储为HDFS中的一个Block。
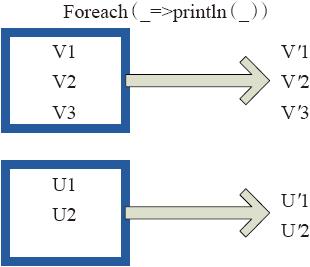
图3-25 foreach算子对RDD转换
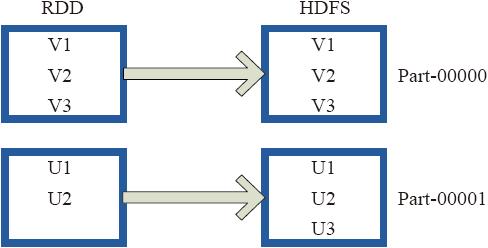
图3-26 saveAsHadoopFile算子对RDD转换
(2)saveAsObjectFile
saveAsObjectFile将分区中的每10个元素组成一个Array,然后将这个Array序列化,映射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
下面代码为函数内部实现。
- map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x))))
图3-27中的左侧方框代表RDD分区,右侧方框代表HDFS的Block。通过函数将RDD的每个分区存储为HDFS上的一个Block。
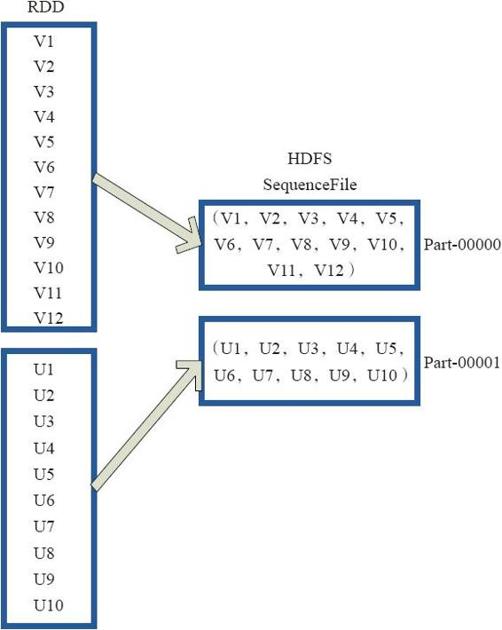
图3-27 saveAsObjectFile算子对RDD转换
3.Scala集合和数据类型
(1)collect
collect相当于toArray,toArray已经过时不推荐使用,collect将分布式的RDD返回为一个单机的scala Array数组。在这个数组上运用scala的函数式操作。
图3-28中的左侧方框代表RDD分区,右侧方框代表单机内存中的数组。通过函数操作,将结果返回到Driver程序所在的节点,以数组形式存储。
(2)collectAsMap
collectAsMap对(K,V)型的RDD数据返回一个单机HashMap。对于重复K的RDD元素,后面的元素覆盖前面的元素。
图3-29中的左侧方框代表RDD分区,右侧方框代表单机数组。数据通过collectAsMap函数返回给Driver程序计算结果,结果以HashMap形式存储。
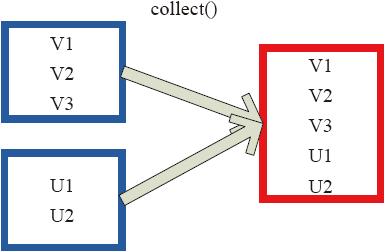
图3-28 Collect算子对RDD转换
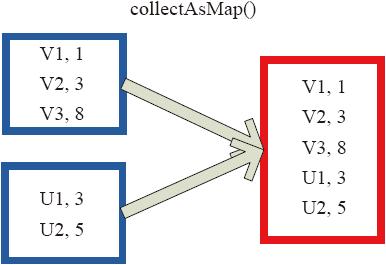
图3-29 collectAsMap算子对RDD转换
(3)reduceByKeyLocally
实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。
(4)lookup
下面代码为lookup的声明。
- lookup(key:K):Seq[V]
Lookup函数对(Key,Value)型的RDD操作,返回指定Key对应的元素形成的Seq。这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。
图3-30中的左侧方框代表RDD分区,右侧方框代表Seq,最后结果返回到Driver所在节点的应用中。
(5)count
count返回整个RDD的元素个数。内部函数实现如下。
- Def count():Long=sc.runJob(this,Utils.getIteratorSize_).sum
在图3-31中,返回数据的个数为5。一个方块代表一个RDD分区。
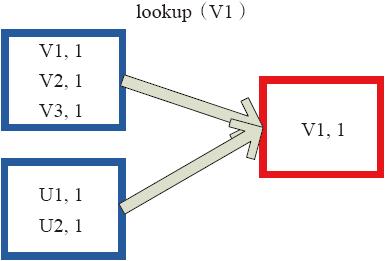
图3-30 lookup对RDD转换
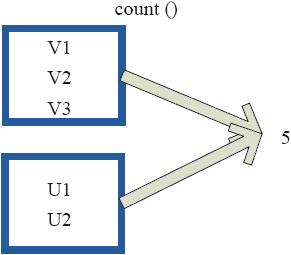
图3-31 count对RDD转换
(6)top
top可返回最大的k个元素。函数定义如下。
- top(num:Int)(implicit ord:Ordering[T]):Array[T]
相近函数说明如下。
·top返回最大的k个元素。
·take返回最小的k个元素。
·takeOrdered返回最小的k个元素,并且在返回的数组中保持元素的顺序。
·first相当于top(1)返回整个RDD中的前k个元素,可以定义排序的方式Ordering[T]。返回的是一个含前k个元素的数组。
(7)reduce
reduce函数相当于对RDD中的元素进行reduceLeft函数的操作。函数实现如下。
- Some(iter.reduceLeft(cleanF))
reduceLeft先对两个元素<K,V>进行reduce函数操作,然后将结果和迭代器取出的下一个元素<k,V>进行reduce函数操作,直到迭代器遍历完所有元素,得到最后结果。
在RDD中,先对每个分区中的所有元素<K,V>的集合分别进行reduceLeft。每个分区形成的结果相当于一个元素<K,V>,再对这个结果集合进行reduceleft操作。
例如:用户自定义函数如下。
- f:(A,B)=>(A._1+"@"+B._1,A._2+B._2)
图3-32中的方框代表一个RDD分区,通过用户自定函数f将数据进行reduce运算。示例最后的返回结果为V1@[1]V2U!@U2@U3@U4,12。
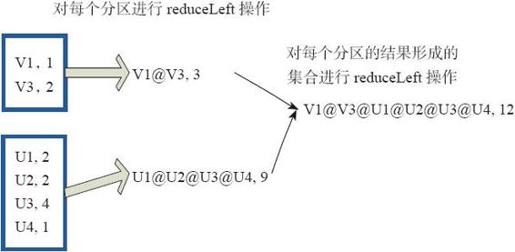
图3-32 reduce算子对RDD转换
(8)fold
fold和reduce的原理相同,但是与reduce不同,相当于每个reduce时,迭代器取的第一个元素是zeroValue。
图3-33中通过下面的用户自定义函数进行fold运算,图中的一个方框代表一个RDD分区。读者可以参照(7)reduce函数理解。
- fold(("V0@",2))( (A,B)=>(A._1+"@"+B._1,A._2+B._2))
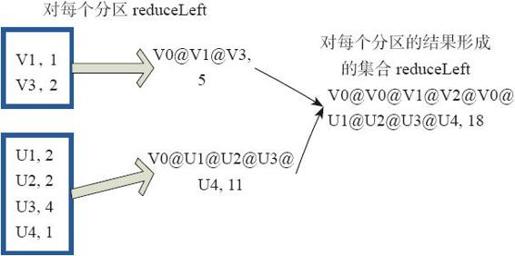
图3-33 fold算子对RDD转换
(9)aggregate
aggregate先对每个分区的所有元素进行aggregate操作,再对分区的结果进行fold操作。
aggreagate与fold和reduce的不同之处在于,aggregate相当于采用归并的方式进行数据聚集,这种聚集是并行化的。而在fold和reduce函数的运算过程中,每个分区中需要进行串行处理,每个分区串行计算完结果,结果再按之前的方式进行聚集,并返回最终聚集结果。
函数的定义如下。
- aggregate[B](z: B)(seqop: (B,A) => B,combop: (B,B) => B): B
图3-34通过用户自定义函数对RDD 进行aggregate的聚集操作,图中的每个方框代表一个RDD分区。
- rdd.aggregate("V0@",2)((A,B)=>(A._1+"@"+B._1,A._2+B._2)),
- (A,B)=>(A._1+"@"+B_1,A._@+B_.2))
最后,介绍两个计算模型中的两个特殊变量。
广播(broadcast)变量:其广泛用于广播Map Side Join中的小表,以及广播大变量等场景。这些数据集合在单节点内存能够容纳,不需要像RDD那样在节点之间打散存储。Spark运行时把广播变量数据发到各个节点,并保存下来,后续计算可以复用。相比Hadoop的distributed cache,广播的内容可以跨作业共享。Broadcast的底层实现采用了BT机制。有兴趣的读者可以参考论文[2]。
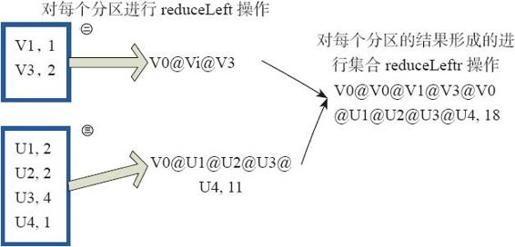
图3-34 aggregate算子对RDD转换
②代表V。
③代表U。
accumulator变量:允许做全局累加操作,如accumulator变量广泛使用在应用中记录当前的运行指标的情景。
[1] @代表数据的分隔符,可替换为其他分隔符。
[2] 参见:Mosharaf Chowdhury,Performance and Scalability of Broadcast in Spark。
