4.2.4 Task调度
通过分析下面的源码,读者可以了解Spark的Task的调度方式。
1.提交任务
在DAGScheduler中提交任务时,分配任务执行节点。
- private def submitMissingTasks(stage: Stage, jobId: Int) {
- logDebug("submitMissingTasks(" + stage + ")")
- val myPending = pendingTasks.getOrElseUpdate(stage, new HashSet)
- myPending.clear()
- var tasks = ArrayBuffer[Task[_]]()
- /*判断是否为Shuffle map stage,如果是,则这个stage输出的结果会经过Shuffle阶段作为下一个stge的输入,如果是Result Stage,则stage的结果输出到Spark空间(如count(),save())*/
- if (stage.isShuffleMap) {
- for (p <- 0 until stage.numPartitions if stage.outputLocs(p) == Nil) {
- val locs = getPreferredLocs(stage.rdd, p)
- /*初始化ShuffleMapTask*/
- tasks += new ShuffleMapTask(stage.id, stage.rdd, stage.shuffleDep.get, p, locs)
- }
- } else {
- val job = resultStageToJob(stage)
- for (id <- 0 until job.numPartitions if !job.finished(id)) {
- val partition = job.partitions(id)
- val locs = getPreferredLocs(stage.rdd, partition)
- /*初始化ResultTask*/
- tasks += new ResultTask(stage.id, stage.rdd, job.func, partition, locs, id)
- }
- }
- val properties = if (jobIdToActiveJob.contains(jobId)) {
- jobIdToActiveJob(stage.jobId).properties
- } else {
- // this stage will be assigned to "default" pool
- null
- }
- /*通过此方法获取任务最佳的执行节点*/
- private[spark]
- def getPreferredLocs(rdd: RDD[_], partition: Int): Seq[TaskLocation] = synchronized {
- ……
- }
2.分配任务执行节点
1)如果是调用过cache()方法的RDD,数据已经缓存在内存,则读取内存缓存中分区的数据。
- val cached = getCacheLocs(rdd)(partition)
- if (!cached.isEmpty) {
- return cached
- }
2)如果直接能获取到执行地点,则返回执行地点作为任务的执行地点,通常DAG中最源头的RDD或者每个Stage中最开始的RDD会有执行地点的信息。例如,HadoopRDD从HDFS读出的分区就是最好的执行地点。这里涉及Hadoop分区的数据本地性问题,感兴趣的读者可以查阅Hadoop的资料了解。
- /@deprecated("Replaced by PartitionwiseSampledRDD", "1.0.0")
- private[spark] class SampledRDD[T: ClassTag](
- override def getPreferredLocations(split: Partition): Seq[String] =
- firstParent[T].preferredLocations(split.asInstanceOf[SampledRDDPartit//ion].prev)/
- val rddPrefs = rdd.preferredLocations(rdd.partitions(partition)).toList
- if (!rddPrefs.isEmpty) {
- return rddPrefs.map(host => TaskLocation(host))
- }
3)如果不是上面两种情况,将遍历RDD获取第一个窄依赖的父亲RDD对应分区的执行地点。
- rdd.dependencies.foreach {
- case n: NarrowDependency[_] =>
- for (inPart <- n.getParents(partition)) {
获取到子RDD分区的父母分区的集合,再继续深度优先遍历,不断获取到这个分区的父母分区的第一个分区,直到没有Narrow Dependency。可以通过图4-8看到RDD2的p0分区位置就是RDD0中p0分区的位置。
- val locs = getPreferredLocs(n.rdd, inPart)
- if (locs != Nil) {
- return locs
- }
- }
- case _ =>
- }
- Nil
- }
如果是Shuffle Dependency,由于在Stage之间需要进行Shuffle,而分区无法确定,所以无法获取分区的存储位置。这表示如果一个Stage的父母Stage还没执行完,则子Stage中的Task不能够获得执行位置。
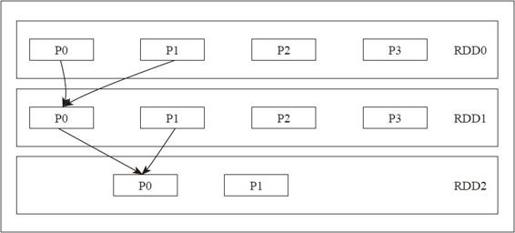
图4-8 分区获取prefer位置
整体的Task分发由TaskSchedulerImpl来实现,但是Task的调度(本质上是Task在哪个分区执行)逻辑由TaskSetManager完成。这个类监控整个任务的生命周期,当任务失败时(如执行时间超过一定的阈值),重新调度,也会通过delay scheduling进行基于位置感知(locality-aware)的任务调度。TaskSchedulerImpl类有几个主要接口:接口resourceOffer,作用为判断任务集合是否需要在一个节点上运行。接口statusUpdate,其主要作用为更新任务状态。
任务的locality由以下两种方式确定。
1)RDD DAG源头有HDFS等类型的分布式存储,它们内置的数据本地性决定(RDD中配置preferred location确定)数据存储位置和分区的选取。
2)每个其他非源头Stage由于都要进行Shuffle,所以地址以在resourceoffer中进行round robin来确定,初始提交Stage时,将prefer的位置设置为Nil。但在Stage调度过程中,内部是通过Narrow dep的祖先Stage确定最佳执行位置的。这样相当于每个RDD的分区都有prefer执行位置。
