4.3.1 序列化
序列化是将对象转换为字节流,本质上可以理解为将链表存储的非连续空间的数据存储转化为连续空间存储的数组中。这样就可以将数据进行流式传输或者块存储。相反,反序列化就是将字节流转化为对象。
序列化主要有以下两个目的。
·进程间通信:不同节点之间进行数据传输。
·数据持久化存储到磁盘:本地节点将对象写入磁盘。
Spark通过集中方式实现进程通信,包括Actor的消息模式、Java NIO和netty的OIO。
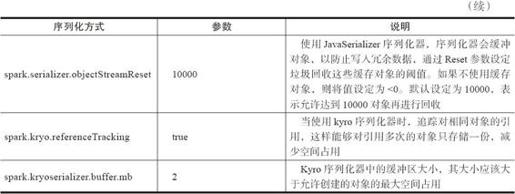
在Spark中,序列化拥有重要地位。无论是内存或者磁盘中的RDD含有的对象存储,还是节点间的传输数据,都需要执行序列化的过程。序列化与反序列化的速度、序列化后的数据大小等都影响数据传输的速度,以致影响集群的计算效率。Spark可以使用Java的序列化库,也可以使用Kyro序列化库。Kyro具有紧凑、快速、轻量的优点,允许自定义序列化方法,且扩展性很好。下面用户可以通过表4-1参数进行序列化配置。
表4-1 序列化参数简介

其他详细介绍会在性能调优章节介绍。
