8.4.6 利用MLlib进行电影推荐
下面介绍MLib进行个性化的电影推荐应用。通过Berkely的这个典型案例,用户可以更加深入地理解MLlib以及学会如何构建自己的MLlib应用。[1]本例中使用MovieLenss收集的72000名用户在1万部影片上的1千万个评分数据集。这里假定这个数据集已经预加载进集群的HDFS文件夹/movielens/large下。为了快速测试代码,可以先使用文件夹/movielens/medium中的小数据集进行测试,这个数据集包含6000名用户在4000部影片上的1百万个评分数据。
1.数据集
本例使用MovieLens数据集中的两个文件:“ratings.dat.”和“movies.dat”。所有的评分数据按照下面的格式存储“ratings.dat”中。
- UserID::MovieID::Rating::Timestamp
在“movies.dat”中以下面的格式存储电影信息。
- MovieID::Title::Genres
2.协同过滤
协同过滤是推荐系统普遍使用的方法。这些技术的本质目的是填充user-item关联矩阵中的缺失数据项。MLlib 1.0支持基于模型的协同过滤,这时通过一个隐含因子的小集合来预测缺失的数据项。MLlib通过实现交替最小二乘法(ALS)去求出这些隐含因子(latent factors)。图8-25为ALS算法的解析图。ALS算法为了最小化损失函数f,通过交替固定Users或者Movies向量,对损失函数求导,最终求出逼近Ratings矩阵的结果,使用这个结果进行电影推荐,如图8-27所示。
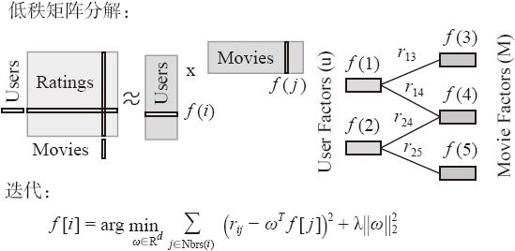
图8-27 ALS算法
3.配置
针对本例使用一个standalone项目模板。假设在用户的环境中,已经配置好所需路径和文件(实例下载地址为https://github.com/amplab/training/tree/ampcamp4/machine-learning/scala),这些已经在/root/machine-learning/scala/中设置,读者将会在目录下找到以下选项。
·sbt:包含SBT工具的目录。
·build.sbt:SBT项目文件。
·MovieLensALS.scala:用户需要编译和运行的主要Scala主程序。
·solution:包含solution代码的目录。
用户需要编辑、编译和运行的主要文件是MovieLensALS.scala,可以将下面的代码模板拷贝到文件中。
- import java.util.Random
- import org.apache.log4j.Logger
- import org.apache.log4j.Level
- import scala.io.Source
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.rdd._
- import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
- object MovieLensALS {
- def main(args: Array[String]) {
- Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
- Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- if (args.length != 1) {
- println("Usage: sbt/sbt package \"run movieLensHomeDir\"")
- exit(1)
- }
- /* 配置环境 */
- val jarFile = "target/scala-2.10/movielens-als_2.10-0.0.jar"
- val sparkHome = "/root/spark"
- val master = Source.fromFile("/root/spark-ec2/cluster-url").mkString.trim
- val masterHostname = Source.fromFile("/root/spark-ec2/masters").mkString.trim
- val conf = new SparkConf()
- .setMaster(master)
- .setSparkHome(sparkHome)
- .setAppName("MovieLensALS")
- .set("spark.executor.memory", "8g")
- .setJars(Seq(jarFile))
- val sc = new SparkContext(conf)
- /* 加载评分和电影标题 */
- val movieLensHomeDir = "hdfs://" + masterHostname + ":9000" + args(0)
- val ratings = sc.textFile(movieLensHomeDir + "/ratings.dat").map { line =>
- val fields = line.split("::")
- /* 格式为: (timestamp % 10, Rating(userId, movieId, rating)) */
- (fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
- }
- val movies = sc.textFile(movieLensHomeDir + "/movies.dat").map { line =>
- val fields = line.split("::")
- /* 格式为: (movieId, movieName) */
- (fields(0).toInt, fields(1))
- }.collect.toMap
- sc.stop();
- }
- /** 计算RMSE (Root Mean Squared Error) */
- def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long) = {
- ……
- }
- def elicitateRatings(movies: Seq[(Int, String)]) = {
- ……
- }
- }
首先通过文本编辑器打开MovieLensALS文件。
- cd /root/machine-learning/scala
vim MovieLensALS.scala#如果不使用vim,还可以使用emacs或者nano进行文本编辑。
可以选用常用的文本编辑器打开文件,将示例拷贝进文件中。
对于任何的Spark计算任务来说,第一步都需要创建SparkConf对象。然后通过它创建SparkContext对象。对于Scala或者Java程序来说,需要配置Spark集群的URL、Spark主目录和用户程序需要的JAR文件进行初始化。对于Python程序来说,只需要配置Spark cluster URL一个参数即可。最后还需要配置一个应用名称,以便在Spark Web UI中确认程序。
①可以参照下面的初始化代码。
- val conf = new SparkConf()
- .setMaster(master)
- .setSparkHome(sparkHome)
- .setAppName("MovieLensALS")
- .set("spark.executor.memory", "8g")
- .setJars(Seq(jarFile))
- val sc = new SparkContext(conf)
②使用SparkContext对象读取评分文件。评分文件以“::”作为分隔符。下面的代码解析评分文件的每行创建以(Int,Rating)对为数据项的一个RDD。这里保存时间戳的最后一个数字作为一个随机关键字。Ratingclass是一个对元组(user:Int,product:Int,rating:Double)的包装类,它在MLlib的包org.apache.spark.mllib.recommendation中定义。
- val movieLensHomeDir = "hdfs://" + masterHostname + ":9000" + args(0)
- val ratings = sc.textFile(movieLensHomeDir + "/ratings.dat").map { line =>
- val fields = line.split("::")
- /* 格式为: (timestamp % 10, Rating(userId, movieId, rating)) */
- (fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).
- toDouble))
- }
③通过读取movie id和title将其转化电影ID到title的映射。
- val movies = sc.textFile(movieLensHomeDir + "/movies.dat").map { line =>
- val fields = line.split("::")
- /* 格式为: (movieId, movieName) */
- (fields(0).toInt, fields(1))
- }.collect.toMap
至此,用户可以统计一些评分数据。
- val numRatings = ratings.count
- val numUsers = ratings.map(_._2.user).distinct.count
- val numMovies = ratings.map(_._2.product).distinct.count
- println("Got " + numRatings + " ratings from "
- + numUsers + " users on " + numMovies + " movies.")
4.运行程序
用户应该知道如何运行例子。保存之前编辑的MovieLensALS文件,然后运行下面的命令。
- cd /root/machine-learning/scala
如果用户需要运行大数据集,则将参数medium转换为large,进而在大数据集上运行例子:
- sbt/sbt package "run /movielens/medium" / *其中/movielens/medium是主程序main函数的输入参数 */
这个命令将会编译MovieLensALS类,然后在/root/machine-learning/scala/target/scala-2.10/目录下创建一个JAR文件,最后运行这个程序,在用户的控制台上显示下面的输出。
- Got 1000209 ratings from 6040 users on 3706 movies.
5.启发评级
为了向用户推荐,需要通过用户评价的一些电影了解用户的兴趣。需要统计每个电影接收到的评分,然后根据评分数排序。最后获取评分最高的50部电影,采样出一个小集合进行启发评级。
- val mostRatedMovieIds = ratings.map(_._2.product)
- /* 抽取 movie id*/
- .countByValue
- /* 计算每个movie的评分*/
- .toSeq
- /* 将数据转换为Seq格式*/
- .sortBy(- _._2)
- /* 通过评分数排序*/
- .take(50)
- /* 获得评分数最多的50部movie*/
- .map(_._1)
- /* 获取它们的ID*/
- val random = new Random(0)
- val selectedMovies = mostRatedMovieIds.filter(x => random.nextDouble() < 0.2)
- .map(x => (x, movies(x)))
- .toSeq
每个被挑选到的电影都需要评分(评分为0~5的整数,如果没有看过,则填0)。方法eclicitateRatings返回用户的评分,用户会分配到一个特殊的用户ID 0。这个评分通过sc.parallelize.转换为一个RDD[Rating]实例。
- val myRatings = elicitateRatings(selectedMovies)
- val myRatingsRDD = sc.parallelize(myRatings)
运行以上程序,将会看到和下面类似的提示。
- Please rate the following movie (1-5 (best), or 0 if not seen):
- Raiders of the Lost Ark (1981):
6.切分训练数据
使用MLlib中的ALS算法将会用RDD[Rating]实例作为输入来训练一个模型。ALS算法有一些训练参数。例如,矩阵因子的排名和正则化器的实例。为了确定一个好的训练参数,基于时间戳的最后一位将数据分成3个没有交集的子集,称为训练集、测试集和评价集,并将它们缓存。接下来会通过训练集训练不同的模型,通过RMSE(root mean squared error)方法和评价集选取最好的集合,通过测试集评价最好的模型,并将用户的评分加入测试集中,进而对用户推荐。在这个过程中,由于需要多次访问这些数据,所以会把训练集、评价集和测试集通过persist方法放到内存。
- val numPartitions = 20
- val training = ratings.filter(x => x._1 < 6)
- .values
- .union(myRatingsRDD)
- .repartition(numPartitions)
- .persist
- val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
- .values
- .repartition(numPartitions)
- .persist
- val test = ratings.filter(x => x._1 >= 8).values.persist
- val numTraining = training.count
- val numValidation = validation.count
- val numTest = test.count
- println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)
在进行切分之后,用户将会看到下面的日志信息。
- Training: 602251, validation: 198919, test: 199049.
7.通过ALS算法进行模型训练
下面使用ALS.train方法来训练一组模型,然后从中评价和选择出最好的模型。ALS所有训练算法中最重要的参数是rank、lambda(正则化常数)和迭代次数iterations。使用的ALS算法中的train方法以下面的方式给出。
- object ALS {
- def train(ratings: RDD[Rating], rank: Int, iterations: Int, lambda: Double)
- : MatrixFactorizationModel = {
- ……
- }
- }
在理想情况下,用户希望能够尝试所有的参数组合来发现最好的状况。但是由于时间的约束,本例只会测试8种组合:两种不同的rank(8和12)、两种不同的lambdas(1.0和10.0)以及两种不同的iterations(10和20)。MLlib中提供方法computeRmse在每个模型的评价集上计算RMSE。RMSE值最小的评价集将被最后选择,RMSE值作为评价指标。
- val ranks = List(8, 12)
- val lambdas = List(0.1, 10.0)
- val numIters = List(10, 20)
- var bestModel: Option[MatrixFactorizationModel] = None
- var bestValidationRmse = Double.MaxValue
- var bestRank = 0
- var bestLambda = -1.0
- var bestNumIter = -1
- for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
- val model = ALS.train(training, rank, numIter, lambda)
- val validationRmse = computeRmse(model, validation, numValidation)
- println("RMSE (validation) = " + validationRmse + " for the model trained
- with rank = "
- + rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".")
- if (validationRmse < bestValidationRmse) {
- bestModel = Some(model)
- bestValidationRmse = validationRmse
- bestRank = rank
- bestLambda = lambda
- bestNumIter = numIter
- }
- }
- val testRmse = computeRmse(bestModel.get, test, numTest)
- println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
- + ", and numIter = " + bestNumIter + ", and its RMSE on the test set is "
- + testRmse + ".")
程序运行成功后,用户将在控制台看到下面的信息。
- The best model was trained using rank 8 and lambda 10.0, and its RMSE on test is 0.8808492431998702.
8.电影推荐
最后可以看到通过训练出的模型推荐给用户哪些电影。推荐是通过生成用户没有评分的电影的(0,movieId)对,然后调用predict方法获取预测。
- class MatrixFactorizationModel {
- def predict(userProducts: RDD[(Int, Int)]): RDD[Rating] = {
- ……
- }
- }
获取所有的预测之后,用户可以列出top 50的推荐电影。
- val myRatedMovieIds = myRatings.map(_.product).toSet
- val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
- val recommendations = bestModel.get
- .predict(candidates.map((0, _)))
- .collect
- .sortBy(-_.rating)
- .take(50)
- var i = 1
- println("Movies recommended for you:")
- recommendations.foreach { r =>
- println("%2d".format(i) + ": " + movies(r.product))
- i += 1
- }
用户会得到类似下面的输出。
- Movies recommended for you:
- 1: Silence of the Lambs, The (1991)
- 2: Saving Private Ryan (1998)
- 3: Godfather, The (1972)
- 4: Star Wars: Episode IV - A New Hope (1977)
- 5: Braveheart (1995)
- 6: Schindler's List (1993)
- 7: Shawshank Redemption, The (1994)
- 8: Star Wars: Episode V - The Empire Strikes Back (1980)
- 9: Pulp Fiction (1994)
- 10: Alien (1979)
- ……
由于数据集较旧,显示的基本都是老电影。
[1] 示例参考:http://ampcamp.berkeley.edu/big-data-mini-course/movie-recommendation-with-mllib.html
