4.2.2 Spark应用程序内Job的调度
在Spark应用程序内部,用户通过不同线程提交的Job可以并行运行,这里所说的Job就是Spark Action(如count、collect等)算子触发的整个RDD DAG为一个Job,在实现上,算子中的本质是调用SparkContext中的runJob提交了Job。例如,通过count的源码看这个过程。
- def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
其中,sc就是SparkContext对象,调用runJob方法提交Job。
Spark的调度器是完全线程安全的,并且支持一个应用处理多请求的用例(如多用户进行查询)。
(1)FIFO模式
在默认情况下,Spark的调度器以FIFO(先进先出)方式调度Job的执行,如图4-6所示。每个Job被切分为多个Stage。第一个Job优先获取所有可用的资源,接下来第二个Job再获取剩余资源。以此类推,如果第一个Job并没有占用所有的资源,则第二个Job还可以继续获取剩余资源,这样多个Job可以并行运行。如果第一个Job很大,占用所有资源,则第二个Job就需要等待第一个任务执行完,释放空余资源,再申请和分配Job。
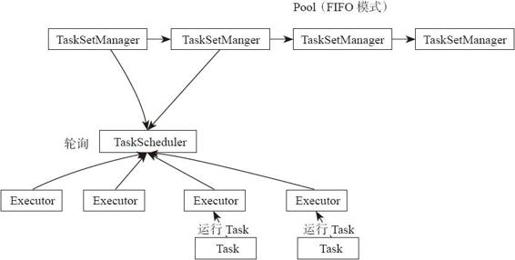
图4-6 FIFO模式调度示意图
读者可以通过图示大致了解FIFO模式,下面通过源码更加深入地剖析FIFO模式。
- private[spark] class FIFOSchedulingAlgorithm extends
- SchedulingAlgorithm {
- override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
- /*执行优先级*/
- val priority1 = s1.priority
- val priority2 = s2.priority
- var res = math.signum(priority1 - priority2)
- if (res == 0) {
- val stageId1 = s1.stageId
- val stageId2 = s2.stageId
- /*signum是符号函数。功能是如果参数为 0,则返回 0;如果参数大于 0,则返回 1.0;如果参数小于 0,则返回-1.0*/
- res = math.signum(stageId1 - stageId2)
- }
- if (res < 0) {
- true
- } else {
- false
- }
- }
- }
在算法执行中,先看优先级,TaskSet的优先级是JobID,因为先提交的JobID小,所以就会被更优先地调度,这里相当于进行了两层排序,先看是否是同一个Job的Taskset,不同Job之间的TaskSet先排序。
最后执行的stageId最小为0,最先应该执行的stageId最大。但是这里的调度机制是优先调度Stageid小的。在DAGScheduler中控制Stage是否被提交到队列中,如果还有父母Stage未执行完,则该stage的Taskset不会提交到调度池中,这就保证了虽然最先做的stage的id大,但是排序完,由于后面的还没提交到调度池中,所以会先执行。由此可见,stage的TaskSet调度逻辑主要在DAGScheduler中,而Job调度由FIFO或者FAIR算法调度。
Job调度的FIFO或FAIR方式是通过Pool类实现的。在下面代码为Pool类的实现、代码通过taskSetSchedulingAlgorithm选择使用FIFO还是FAIR进行Job调度。
- private[spark] class Pool(
- ……
- var taskSetSchedulingAlgorithm: SchedulingAlgorithm = {
- schedulingMode match {
- case SchedulingMode.FAIR =>
- new FairSchedulingAlgorithm()
- case SchedulingMode.FIFO =>
- new FIFOSchedulingAlgorithm()
- }
- }
- ……
/这里是使用调度算法的地方,实际上通过调度算法进行了Job的调度和Job内的TaskSetManager的两级调度。获取优先级最高的可调度资源执行/
- override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
- var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
- val sortedSchedulableQueue =
- /*使用比较器进行排序*/
- schedulableQueue.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
- for (schedulable <- sortedSchedulableQueue) {
- sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
- }
- sortedTaskSetQueue
- }
这里是使用调度算法的地方,实际上通过调度算法进行了Job的调度和Job内的TaskSetManager的两级调度。获取优先级最高的可调度资源执行。这里使用了设计模式中的策略模式,使用FIFO充当TaskSetManager的比较器。
(2)FAIR模式
从Spark 0.8版本开始,可以通过配置FAIR共享调度模式调度Job,如图4-7所示。在FAIR共享模式调度下,Spark在多Job之间以轮询(round robin)方式为任务分配资源,所有的任务拥有大致相当的优先级来共享集群的资源。这就意味着当一个长任务正在执行时,短任务仍可以分配到资源,提交并执行,并且获得不错的响应时间。这样就不用像以前一样需要等待长任务执行完才可以。这种调度模式很适合多用户的场景。用户可以通过配置spark.scheduler.mode方式来让应用以FAIR模式调度。FAIR调度器同样支持将Job分组加入调度池中调度,用户可以同时针对不同优先级对每个调度池配置不同的调度权重。这种方式允许更重要的Job配置在高优先级池中优先调度。这种方式借鉴了Hadoop的FAIR调度模型,如图4-7所示。
如果读者对FAIR调度模式的源码感兴趣,可以参照FairSchedulingAlgorithm.scala源码了解,限于篇幅先不在这里介绍。
在默认情况下,每个调度池拥有相同的优先级来共享整个集群的资源,同样default pool中的每个Job也拥有同样优先级进行资源共享,但是在用户创建的每个资源池中,Job是通过FIFO方式进行调度的。例如,如果每个用户都创建了一个调度池,这就意味着每个用户的调度池将会获得同样的优先级来共享整个集群,但是每个用户的调度池内部的请求是按照先进先出的方式调度的,后到的请求不能比先到的请求更早获得资源。
在没有外部干预的情况下,新提交的任务放入default pool中进行调度。如果用户也可以自定义调度池,通过在SparkContext中配置参数spark.scheduler.pool创建调度池。
- /*假设sc是 SparkContext变量*/
- sc.setLocalProperty("spark.scheduler.pool", "pool6")
这样配置了这个参数的线程每次提交的任务都是放入这个池中进行调度(如这个线程调用RDD.collect或者RDD.count等action算子)。这种调度池的配置可以很方便地让同一个用户在一个线程中运行多个Job。如果用户不想再使用这个调度池,可以通过调用SparkContext的方法来终止这个调度池的使用:
- sc.setLocalProperty("spark.scheduler.pool6", null)
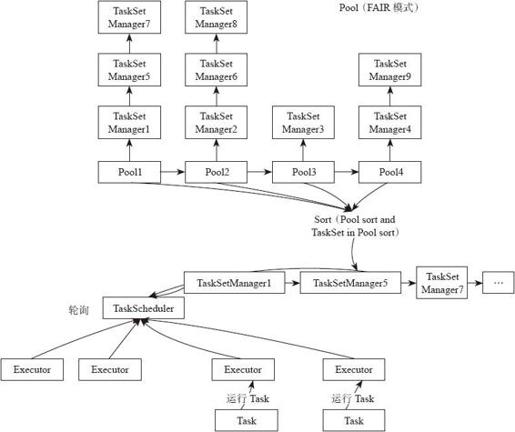
图4-7 FAIR调度模型
(3)配置调度池
用户可以通过配置文件自定义调度池的属性。每个调度池支持下面3个配置参数。
1)调度模式(schedulingMode):用户可以选择FIFO或者FAIR方式进行调度。
2)权重(Weight):这个参数控制在整个集群资源的分配上,这个调度池相对其他调度池优先级的高低。例如,如果用户配置一个指定的调度池权重为3,那么这个调度池将会获得相对于权重为1的调度池3倍的资源。
3)minShare:配置minShare参数(这个参数代表多少个CPU核),这个参数决定整体调度的调度池能给待调度的调度池分配多少资源就可以满足调度池的资源需求,剩余的资源还可以继续分配给其他调度池。
用户可以通过conf/fairscheduler.xml文件配置调度池的属性,同时需要在程序的SparkConf对象中配置属性。
- conf.set("spark.scheduler.allocation.file", "/path/to/file")
读者可以参考下面官方文档的配置例子进行配置,配置文件的格式为XML。
- <?xml version="1.0"?>
- <allocations>
- <pool name="production">
- <schedulingMode>FAIR</schedulingMode>
- <weight>1</weight>
- <minShare>2</minShare>
- </pool>
- <pool name="test">
- <schedulingMode>FIFO</schedulingMode>
- <weight>2</weight>
- <minShare>3</minShare>
- </pool>
- </allocations>
读者可以参考conf/fairscheduler.xml.template这个模板文件,文件中提供了更加全面的配置介绍。
