1.5.2 Spark在Yahoo!的应用
在Spark技术的研究与应用方面,Yahoo!始终处于领先地位,它将Spark应用于公司的各种产品之中。移动App、网站、广告服务、图片服务等服务的后端实时处理框架均采用了Spark+Shark的架构。
在2013年,Yahoo!拥有72656600个页面,有上百万的商品类别,上千个商品和用户特征,超过800万用户,每天需要处理海量数据。
通过图1-11可以看到Yahoo!使用Spark进行数据分析的整体架构。
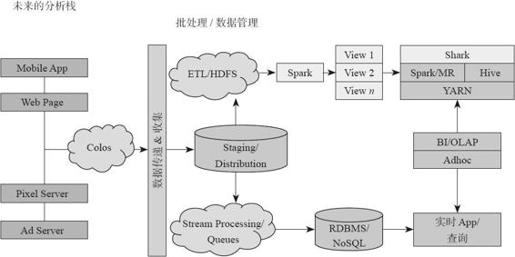
图1-11 Yahoo!大数据分析栈
大数据分析平台架构解析如下。
整个数据分析栈构建在YARN之上,这是为了让Hadoop和Spark的任务共存。主要包含两个主要模块:
1)离线处理模块:使用MapReduce和Spark+Shark混合架构。由于MapReduce适合进行ETL处理,还保留Hadoop进行数据清洗和转换。数据在ETL之后加载进HDFS/HCat/Hive数据仓库存储,之后可以通过Spark、Shark进行OLAP数据分析。
2)实时处理模块:使用Spark Streaming+Spark+Shark架构进行处理。实时流数据源源不断经过Spark Steaming初步处理和分析之后,将数据追加进关系数据库或者NoSQL数据库。之后,结合历史数据,使用Spark进行实时数据分析。
之所以选择Spark,Yahoo!基于以下几点进行考虑。
1)进行交互式SQL分析的应用需求。
2)RAM和SSD价格不断下降,数据分析实时性的需求越来越多,大数据急需一个内存计算框架进行处理。
3)程序员熟悉Scala开发,接受Spark学习曲线不陡峭。
4)Spark的社区活跃度高,开源系统的Bug能够更快地解决。
5)传统Hadoop生态系统的分析组件在进行复杂数据分析和保证实时性方面表现得力不从心。Spark的全栈支持多范式数据分析能够应对多种多样的数据分析需求。
6)可以无缝将Spark集成进现有的Hadoop处理架构。
Yahoo!的Spark集群在2013年已经达到9.2TB持久存储、192GB RAM、112节点(每节点为SATA 1×500GB(7200转的硬盘))、400GB SSD(1×400GB SATA 300MB/s)的集群规模。
