1.5.4 Spark在淘宝的应用
数据挖掘算法有时候需要迭代,每次迭代时间非常长,这是淘宝选择一个更高性能计算框架Spark的原因。Spark编程范式更加简洁也是一大原因。另外,GraphX提供图计算的能力也是很重要的。
1.Spark on YARN架构
Spark的计算调度方式从Mesos到Standalone,即自建Spark计算集群。虽然Standalone方式性能与稳定性都得到了提升,但自建集群资源少,需要从云梯集群复制数据,不能满足数据挖掘与计算团队业务需求[1]。而Spark on YARN能让Spark计算模型在云梯YARN集群上运行,直接读取云梯上的数据,并充分享受云梯YARN集群丰富的计算资源。图1-13为Spark on YARN的架构。
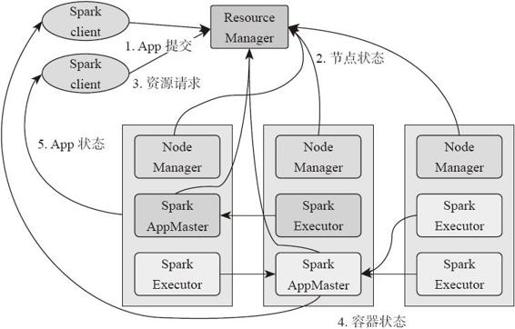
图1-13 Spark on YARN架构
Spark on YARN架构解析如下。
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。目前,淘宝数据挖掘与计算团队通过Spark on YARN已实现MLR、PageRank和JMeans算法,其中MLR已作为生产作业运行。
2.协作系统
1)Spark Streaming:淘宝在云梯构建基于Spark Streaming的实时流处理框架。Spark Streaming适合处理历史数据和实时数据混合的应用需求,能够显著提高流数据处理的吞吐量。其对交易数据、用户浏览数据等流数据进行处理和分析,能够更加精准、快速地发现问题和进行预测。
2)GraphX[2]:淘宝将交易记录中的物品和人组成大规模图。使用GraphX对这个大图进行处理(上亿个节点,几十亿条边)。GraphX能够和现有的Spark平台无缝集成,减少多平台的开发代价。
本节主要介绍了Spark在工业界的应用。Spark起源于学术界,发展于工业界,现在已经成为大数据分析不可或缺的计算框架。通过Amazon提供Spark云服务,可以看到Big Data on Cloud已经兴起。Yahoo!很早就开始使用Spark,将Spark用于自己的广告平台、商品交易数据分析和推荐系统等数据分析领域。同时Yahoo!也积极回馈社区,与社区形成良好的互动。Stratio公司为西班牙电信提供基于Spark+Cassandra+Storm架构的数据分析解决方案,实现流数据实时处理与离线数据分析兼顾,通过它们的案例可以看到多系统混合提供多数据计算范式分析平台是未来的一个趋势。最后介绍国内淘宝公司的Spark应用案例,淘宝是国内较早使用Spark的公司,通过Spark进行大规模机器学、图计算以及流数据分析,并积极参与社区,与社区形成良好互动,并乐于分享技术经验。希望读者通过企业案例能够全面了解Spark的广泛应用和适用场景。
[1] 参见沈洪的《深入剖析阿里巴巴云梯YARN集群》,《程序员》,2013.12。
[2] 参见文章:黄明,吴炜.快刀初试:Spark GraphX在淘宝的实践.程序员,2014.8。
