3.1 Spark程序模型
下面通过一个经典的示例程序来初步了解Spark的计算模型,过程如下。
1)SparkContext中的textFile函数从HDFS[1]读取日志文件,输出变量file[2]。
- val file=sc.textFile("hdfs://xxx")
2)RDD中的filter函数过滤带“ERROR”的行,输出errors(errors也是一个RDD)。
- val errors=file.filter(line=>line.contains("ERROR")
3)RDD的count函数返回“ERROR”的行数:errors.count()。
RDD操作起来与Scala集合类型没有太大差别,这就是Spark追求的目标:像编写单机程序一样编写分布式程序,但它们的数据和运行模型有很大的不同,用户需要具备更强的系统把控能力和分布式系统知识。
从RDD的转换和存储角度看这个过程,如图3-1所示。
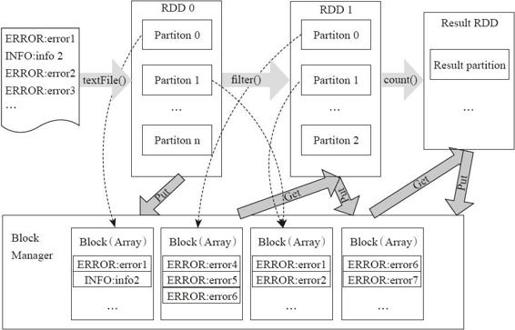
图3-1 Spark程序模型
在图3-1中,用户程序对RDD通过多个函数进行操作,将RDD进行转换。Block-Manager管理RDD的物理分区,每个Block就是节点上对应的一个数据块,可以存储在内存或者磁盘。而RDD中的partition是一个逻辑数据块,对应相应的物理块Block。本质上一个RDD在代码中相当于是数据的一个元数据结构,存储着数据分区及其逻辑结构映射关系,存储着RDD之前的依赖转换关系。
[1] 也可以是本地文件或者其他的持久化层,如Hive等。
[2] file是一个RDD,数据项是文件中的每行数据。
