4.1.1 Spark执行机制总览
Spark应用提交后经历了一系列的转换,最后成为Task在每个节点上执行。Spark应用转换(见图4-1):RDD的Action算子触发Job的提交,提交到Spark中的Job生成RDD DAG,由DAGScheduler转化为Stage DAG,每个Stage中产生相应的Task集合,TaskScheduler将任务分发到Executor执行。每个任务对应相应的一个数据块,使用用户定义的函数处理数据块。
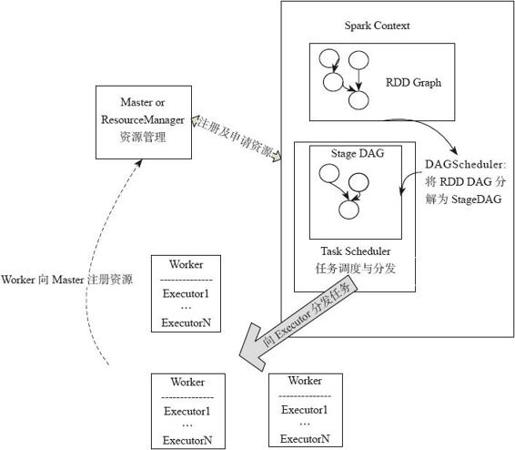
图4-1 Spark应用转换流程
Spark执行的底层实现原理,如图4-2所示。在Spark的底层实现中,通过RDD进行数据的管理,RDD中有一组分布在不同节点的数据块,当Spark的应用在对这个RDD进行操作时,调度器将包含操作的任务分发到指定的机器上执行,在计算节点通过多线程的方式执行任务。一个操作执行完毕,RDD便转换为另一个RDD,这样,用户的操作依次执行。Spark为了系统的内存不至于快速用完,使用延迟执行的方式执行,即只有操作累计到Action(行动),算子才会触发整个操作序列的执行,中间结果不会单独再重新分配内存,而是在同一个数据块上进行流水线操作。
在集群的程序实现上,有一个重要的分布式数据结构,即弹性分布式数据集(Resilient Distributed Dataset,RDD)。Spark实现了分布式计算和任务处理,并实现了任务的分发、跟踪、执行等工作,最终聚合结果,完成Spark应用的计算。
对RDD的块管理通过BlockManger完成,BlockManager将数据抽象为数据块,在内存或者磁盘进行存储,如果数据不在本节点,则还可以通过远端节点复制到本机进行计算。
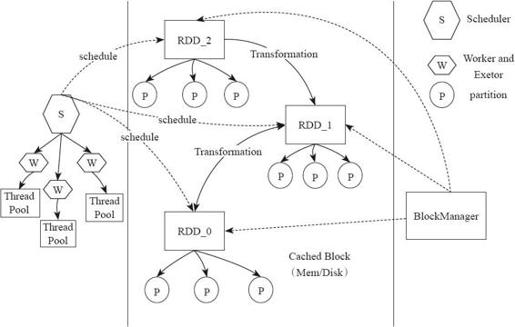
图4-2 Spark执行底层实现
在计算节点的执行器Executor中会创建线程池,这个执行器将需要执行的任务通过线程池并发执行。
