4.6 Shuffle机制
Shuffle的本义是洗牌、混洗,即把一组有一定规则的数据打散重新组合转换成一组无规则随机数据分区。Spark中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据,Spark中的Shuffle和MapReduce中的Shuffle思想相同,在实现细节和优化方式上不同,因此掌握Hadoop的Shuffle原理的用户很容易将原有知识迁移过来。
为什么Spark计算模型需要Shuffle过程?我们都知道,Spark计算模型是在分布式的环境下计算的,这就不可能在单进程空间中容纳所有的计算数据来进行计算,这样数据就按照Key进行分区,分配成一块一块的小分区,打散分布在集群的各个进程的内存空间中,并不是所有计算算子都满足于按照一种方式分区进行计算。例如,当需要对数据进行排序存储时,就有了重新按照一定的规则对数据重新分区的必要,Shuffle就是包裹在各种需要重分区的算子之下的一个对数据进行重新组合的过程。在逻辑上还可以这样理解[1]:由于重新分区需要知道分区规则,而分区规则按照数据的Key通过映射函数(Hash或者Range等)进行划分,由数据确定出Key的过程就是Map过程,同时Map过程也可以做数据处理,例如,在Join算法中有一个很经典的算法叫Map Side Join,就是确定数据该放到哪个分区的逻辑定义阶段。Shuffle将数据进行收集分配到指定Reduce分区,Reduce阶段根据函数对相应的分区做Reduce所需的函数处理。
下面结合源码和图4-20从物理实现上看Spark的Shuffle是怎样实现的,将Shuffle分为两个阶段:Shuffle Write和Shuffle Fetch阶段(Shuffle Fetch中包含聚集Aggregate),在Spark中,整个Job转化为一个有向无环图(DAG)来执行,从图4-21中可以看出在整个DAG中是在每个Stage的承接阶段做Shuffle过程。
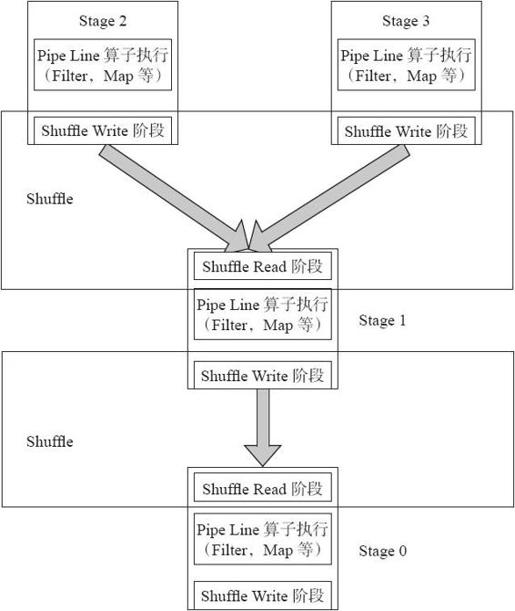
图4-20 Shuffle阶段图
图4-20中,整个Job分为Stage0~Stage3,4个Stage。
首先从最上端的Stage2、Stage3执行,每个Stage对每个分区执行变换(transformation)的流水线式的函数操作,执行到每个Stage最后阶段进行Shuffle Write,将数据重新根据下一个Stage分区数分成相应的Bucket,并将Bucket最后写入磁盘。这个过程就是Shuffle Write阶段。
执行完Stage2、Stage3之后,Stage1去存储有Shuffle数据节点的磁盘Fetch需要的数据,将数据Fetch到本地后进行用户定义的聚集函数操作。这个阶段叫Shuffle Fetch,Shuffle Fetch包含聚集阶段。这样一轮一轮的Stage之间就完成了Shuffle操作。
下面我们更细粒度地将Shuffle的阶段进行拆分,以更深入剖析和了解。
1.Shuffle Write
由于Spark的每个Stage中是通过执行任务来进行运算的,而Spark中只分为两种任务,ShuffleMapTask和ResultTask。其中ResultTask就是最底层的Stage,也是整个任务执行的最后阶段将数据输出到Spark执行空间Stage,除了这个阶段执行ResultTask,其余阶段都执行ShuffleMapTask。因此主要的Shuffle Write逻辑存在这种任务的代码中。
由于Shuffle属于大数据优化的一个很重要的阶段,所以这里的代码优化会比较频繁,下面基于Spark 1.0的代码进行介绍,后续发展变化请读者参考相应版本。
(1)Shuffle Write流程
ShuffleWrite的入口是通过ShuffleMapTask中的runTask方法进入的,也是整个Shuffle Write的控制骨架。
- override def runTask(context: TaskContext): MapStatus = {
- ……
- writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
- /*此处相当于使用ShuffleWriter将相应的分区进行Shuffle Write*/
- writer.write(rdd.iterator(split, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
- return writer.stop(success = true).get
- ……
- }
ShuffleWriter是个抽象的特征(Trait),下面看下它的具体实现。例如,我们看看HashShuffleWriter中是怎样实现的,HashShuffleWriter的主要功能其实就是判断是否需要做MapSideCombine或者做普通的Shuffle,并且提供Shuffle Write各个流程的函数。
- override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {
- private val shuffle = shuffleBlockManager.forMapTask(dep.shuffleId, mapId, numOutputSplits, ser)
- /*这里判断是否进行MapSideCombine,也就是判断是否做Map端聚集合并,如果合并能够在Map端做,将会很大程度减少网络传输的数据量,减少开销*/
- val iter = if (dep.aggregator.isDefined) {
- if (dep.mapSideCombine) {
- dep.aggregator.get.combineValuesByKey(records, context)
- } else {
- records
- }
- ……
- for (elem <- iter) {
- val bucketId = dep.partitioner.getPartition(elem._1)
- /*这里调用ShuffleWriterGroup的writers获取数据写入器,将数据写入bucket*/
- shuffle.writers(bucketId).write(elem)
- }
- }
下面进入ShuffleBlockManager,来分析最终要做的Shuffle Write逻辑。从这段代码中可以看出Spark支持两种类型的Shuffle:Shuffle和优化的Consolidate Shuffle。
- val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
- fileGroup = getUnusedFileGroup()
- Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
- val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
- /*两种Shuffle的区别其实是在对Bucket的处理是否写入FileGroup中
- FileGroup就是一个文件数组,存储文件的引用。在内存中维持这些FileGroup的引用*/
- blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize)
- }
- } else {
- Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
- val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
- /*此处逻辑是获取相应的块,由于每次都是第一次获取,所以会创建新文件,这里每次都会产生新的文件*/
- val blockFile = blockManager.diskBlockManager.getFile(blockId)
- ……
- blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize)
- }
- }
其中,图4-21为Shuffle FileGroup的结构。
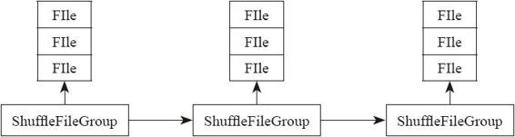
图4-21 Shuffle FileGroup结构
Shuffle做Shuffle Write的细节如图4-22所示。注意:这里的数据是直接写入缓冲中,而未经过排序。
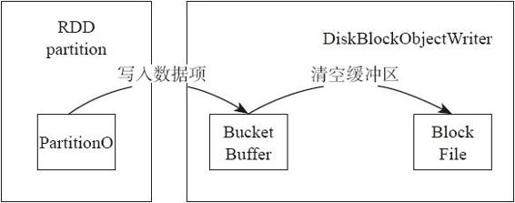
图4-22 Shuffle数据写入磁盘
最终在HashShuffleWriter,将内存的Bucket写到磁盘,存储为文件,并将Shuffle的各个Bucket及映射信息返回给主节点。
(2)Shuffle和Consolidate Shuffle对比
下面从图4-23和图4-24中,更加直观地对比Shuffle和Consolidate Shuffle的整体流程区别。
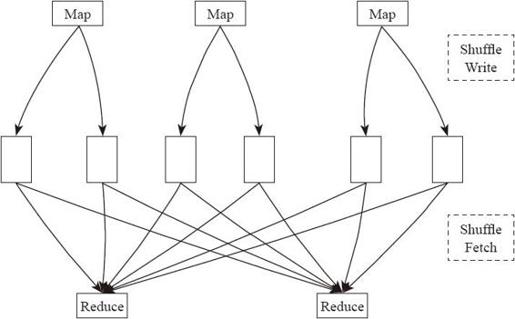
图4-23 Shuffle流程
图4-23中是进行Shuffle的整体流程,假定该Shuffle中有3个Mapper和2个Reducer,这样会产生3×2=6个Bucket,也就是会产生6个Shuffle文件。因此,产生的Shuffle文件个数为M×R,M是Map任务个数,R是Reduce任务数。
图4-24是Consolidation Shuffle的流程图。其中每一个Bucket并非对应一个文件,而是对应文件中的一个segment,同时Consolidation Shuffle所产生的Shuffle文件数量与Spark Core的个数也具有相关性。在上面的图例中,Job的4个Mapper分为两批运行,在第一批2个Mapper运行时,申请4个Bucket,产生4个Shuffle文件;在第二批Mapper运行时,由于只有一个Mapper,申请的4个bucket并不会再产生4个新的文件,而是追加写到之前的其中两个文件后面,这样一共只有4个shuffle文件,而在文件内部这有6个不同的segment。因此,从理论上讲Shuffle Consolidation所产生的shuffle文件数量为C×R,其中C是Spark集群的Core Number,R是Reducer的个数。
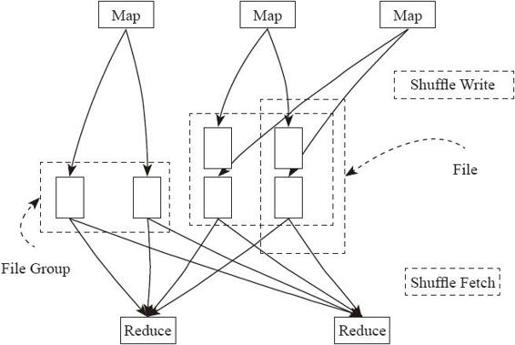
图4-24 Consolidation Shuffle流程
这里的特殊情况是当M=C时,Consolidation Shuffle所产生的文件数和之前的实现相同。
Consolidation Shuffle显著减少了shuffle文件的数量,解决了文件数量过多的问题,但是Writer Handler的Buffer开销过大依然没有减少,若要减少Writer Handler的Buffer开销,只能减少Reducer的数量,但是这又会引入新的问题。
2.Shuffle Fetch
Shuffle write阶段写到各个节点的数据,Reducer端的节点通过拉取数据进而获取需要的数据,在Spark中这个叫Fetch。这就需要Shuffle Fetcher将所需的数据拉过来。这里的fetch包括本地和远端,因为shuffle数据有可能一部分存储在本地。Spark使用两套框架实现Shuffle Fetcher:NIO通过Socket连接去fetch数据;OIO通过Netty去Fetch数据,分别对应的类是BasicBlockFetcherIterator和NettyBlockFetcherIterator。
Spark的团队最终还是想用一个NIO的通信层来解决问题,但是经过性能测试,在一些特定情况下,如集群CPU核数很多地进行大规模Shuffle时,NIO性能表现不如OIO,所以Spark开发团队目前选择让二者共存。
图4-25以reduceByKey为例介绍这个算子对应的Shuffle Fetch阶段。这个Job分为两个Stage,在Stage1和Stage0之间做Shuffle Fetch的操作。HadoopRDD的每个B代表HDFS的一个分区,读入后通过映射转化为MapPartitionsRDD,做完Shuffle Write之后,Shuffle数据按照Bucket存储磁盘。Stage0的每个Task通过元数据知道数据存储在哪个节点,到该节点Fetch需要的指定Key的数据。在Stage0将Fetch到的数据形成分区,所有分区形成ShuffledRDD。通过聚集函数将ShuffledRDD每个分区中的每条数据存储到AppandOnlyMap(其本质可以理解为一个哈希表)中,在这个过程中执行用户定义的聚集函数,做聚集操作。最后将形成的结果形成分区,所有分区形成MapPartitionsRDD。
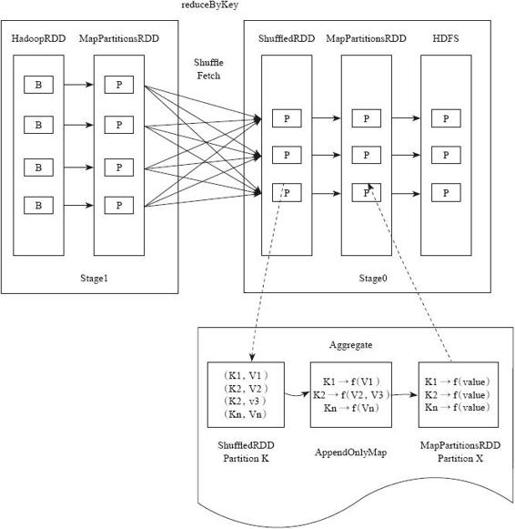
图4-25 reduceByKey的Shuffle Fetch流程
Shuffle Fetch和聚集Aggregate的操作过程是边Fetch数据边处理,而不是一次性Fetch完再处理。通过Aggregate的数据结构,AppandOnlyMap(一个Spark封装的哈希表)。Shuffle Fetch得到一条Key-Value对,直接将其放进AppandOnlyMap中。如果该HashMap已经存在相应的Key,那么直接处理用户自定义聚集函数,合并聚集数据。
3.Shuffle Aggregator
接下来介绍Aggregator(聚集)。我们都知道在Hadoop MapReduce的Shuffle过程中,Shuffle Fetch过来的数据会进行归并排序(merge sort),使得相同Key下的不同Value按序归并到一起供Reducer使用,但是Spark认为并不是所有的情况下Aggregator都需要排序,强制的排序只会增加不必要的开销。
下面介绍Spark的聚集是怎样实现的。
Spark的聚集方式分为两种:不需要外排和需要外排的。不需要外排的聚集,在内存中的AppendOnlyMap中对数据进行聚集,而需要外排的聚集,先在内存做聚集,当内存数据达到阈值时,将数据排序后写入磁盘,由于磁盘的每部分数据只是整体的部分数据,最后再将磁盘数据全部进行合并和聚集。实现上,分别采用了不同自定义容器收集聚集。Aggregator采用封装好的数据容器存储Key-Value,本质上是一个哈希表来存储。
图4-26是AppendOnlyMap不需要外排的聚集。容器本质上可以理解为一个HashMap。当要增加数据时,首先对关键字进行哈希运算查找存放位置,如果存放位置已经被占用,则通过探测方法来找下一个空闲位置。图4-26中如果插入Key1-Value3,则冲突两次,需要再哈希两次,找到新位置插入数据。
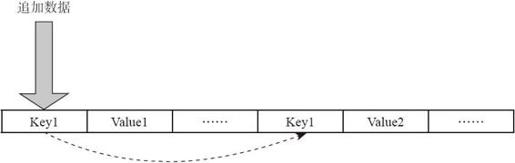
图4-26 Aggregator底层存储结构AppendOnlyMap
当进行迭代AppendOnlyMap中的元素时,从前到后扫描输出。
如果Array的利用率达到70%,就扩张一倍,并对所有Key进行再哈希后,重新排列每个Key的位置。
当用户计算count时,它会更新shuffle fetch到的每一个Key-Value对数据,插入Map中(若在Map中没有查找到,则插入其中;若查找到,则更新value值)。数据来一个处理一个,减少了不必要的排序开销。但同时需要注意,Reducer的内存必须足以存放这个分区的所有Key和count值,因此需要Worker节点保证提供足够内存。
需要外排的聚集的原因是,如果是Reduce型的操作,则数据不断被计算合并,数据量不会暴增。考虑一下如果是groupByKey这样的操作,Reducer需要得到Key对应的所有Value。Spark需要将Key-Value全部存放在Hashmap中,并将Value合并成一个数组。为了能够存放所有数据,必须确保每一个分区足够小,内存能够容纳这个分区。因此官方建议涉及这类操作时,尽量增加分区数量,也就是增加Mapper和Reducer的数量。
增加Mapper和Reducer的数量可以减小分区的大小,使得内存可以容纳这个分区。Bucket的数量由Mapper和Reducer的数量决定,Task越多,Bucket增加得越多,由此带来Writer所需的Buffer缓存也会更多。增加Task数量,又会带来缓冲开销更大的问题,正是这个原因,Spark提供了外排方案。下面通过源码剖析内排和外排两种方式的选择逻辑。
下面代码为Aggregator类,其封装相应的聚集函数逻辑:
- @DeveloperApi
- case class Aggregator[K, V, C] (
- createCombiner: V => C,
- mergeValue: (C, V) => C,
- mergeCombiners: (C, C) => C) {
- /此处决定内存容量不足时是否采用外排的方式,而这又是通过这个参数来确定的/
- private val externalSorting =
- SparkEnv.get.conf.getBoolean("spark.shuffle.spill", true)
- ……
- def combineValuesByKey(iter: Iterator[_ <: Product2[K, V]],
- context: TaskContext): Iterator[(K, C)] = {
- if (!externalSorting) {
- /此处使用了内部优化的数据结构combiners存储了combiner的集合,每个combiner代表一个Key和对应Key的元素Seq/
- val combiners = new AppendOnlyMap[K,C]
- var kv: Product2[K, V] = null
- val update = (hadValue: Boolean, oldValue: C) => {
- /看处理的是否是第一个元素,如果是,则需要创建集合结构,如果不是第一个,则插入原来创建的结构中/
- if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
- }
- while (iter.hasNext) {
- kv = iter.next()
- /如果不采用外排,则调用AppendOnlyMap的聚集数据结构进行存储,有兴趣可以看具体的实现/
- combiners.changeValue(kv._1, update)
- }
- combiners.iterator
- } else {
- val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners)
- while (iter.hasNext) {
- val (k, v) = iter.next()
- /如果采用外排,则使用ExternalAppendOnlyMap这个Spark定义的数据结构存储聚集数据/
- combiners.insert(k, v)
- }
- }
- }
[1] 注意:在Spark中没有明确限定是Map过程,还是Reduce过程,由于整个逻辑过程在Hadoop已经成为事实公认的标准,可以迁移原有知识理解。
