6.4 倒排索引
倒排索引(inverted index)源于实际应用中需要根据属性的值来查找记录。在索引表中,每一项均包含一个属性值和一个具有该属性值的各记录的地址。由于记录的位置由属性值确定,而不是由记录确定,因而称为倒排索引。将带有倒排索引的文件称为倒排索引文件,简称倒排文件(inverted file)。其基本结构如图6-1所示。
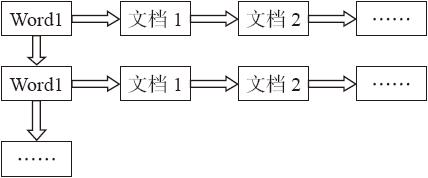
图6-1 倒排索引基本结构
搜索引擎的关键步骤是建立倒排索引。相当于为互联网上几千亿页网页做了一个索引,与书籍目录相似,用户想看与哪一个主题相关的章节,直接根据目录即可找到相关的页面。
1.实例描述
输入为一批文档集合,合并为一个HDFS文件,以分隔符分隔。
- Id1 The Spark
- ……
- Id3 The Spark
- ……
输出如下(单词,文档ID合并字符串)。
- Spark id1 id2
- Hadoop id3 id4
- The id1 id3 id6
2.设计思路
首先进行预处理和分词,转换数据项为(文档ID,文档词集合)的RDD,然后将数据映射为(词,文档ID)的RDD,去重,最后在reduceByKey阶段聚合每个词的文档ID。
3.代码示例
倒排索引的示例代码如下所示:
- import org.apache.spark.SparkContext
- import scala.collection.mutable._
- object InvertedIndex {
- def main(args : Array[String]) {
- val spark = new SparkContext("local", "TopK",
- System.getenv("SPARK_HOME"), SparkContext.jarOfClass(this.getClass))
- /*读取数据,数据格式为一个大的HDFS文件中用\n分隔不同的文件,用\t分隔文件ID和文件内容,用" "分隔文件内的词汇*/
- val words = spark.textFile("dir").map(file => file.split("\t")).map(item => {
- (item(0), item(1))
- }).flatMap(file => {
- /*将数据项转换为LinkedList[(词, 文档id)]的数据项,并通过flatmap将RDD内的数据项转换为(词, 文档ID)*/
- val list = new LinkedList[(String, String)]
- val words = file._2.split(" ").iterator
- while(words.hasNext) {
- list+words.next()
- }
- list
- }).distinct()
- /*将(词,文档ID)的数据进行聚集,相同词对应的文档ID统计到一起,形成*/
- (词, "文档ID1,文档ID2 ,文档ID3……"),形成简单的倒排索引*/
- words.map(word => {
- (word._2, word._1)
- }).reduce((a, b) => {
- a+"\t"+b
- }).saveAsTextFile("index")
- }
- }
4.应用场景
搜索引擎及垂直搜索引擎中需要构建倒排索引,文本分析中有的场景也需要构建倒排索引。
