7.1.3 Bigbench、BigDataBenchmark与TPC-DS
1.Bigbench
BigBench[1]是由Teradata、多伦多大学、InfoSizing、Oracle开发的一款大数据Benchmark。其设计思想和复用扩展的方式很具有研究价值,如果读者感兴趣,可以参阅论文:Bigbench:Towards an industry standard benchmark for big data analytics。
Bigbench可以作为Benchmark研究者的一个范例。Bigbench基于零售业的产品销售场景,用于评测的系统是大规模并行关系数据库和MapReduce类型的执行引擎。
BigBench的数据模型具有以下3种类型。
·结构化的数据:利用TPC-DS生成,筛选了TPC-DS的星型模型数据,并从中挑选部分典型关系表。
·半结构化的数据:利用网页浏览日志并通过PDGF工具生成,这些日志由零售业的客户的浏览页面产生。这些日志格式很像Apache服务器产生的日志格式,并和TPC-DS的数据模式融合,其数据规模也可以随着配置规模因子弹性调整。
·非结构化的数据:数据基于真实数据作为输入,进行采样,并利用字典通过一种使用马尔科夫链的算法生成的文本数据。同样,非结构化数据与结构化和半结构化数据融合。数据规模也可以根据配置的因子弹性动态增长。
整个数据生成器的数据模型如图7-1所示。
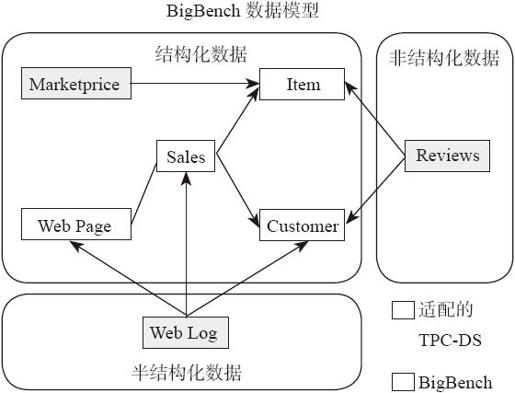
图7-1 BigBench数据模型
BigBench的工作负载主要是针对零售业的大数据分析,同时覆盖了机器学习等算法。现在的工作负载还不是很多,但已经有30个Query。这个Benchmark工具还在扩展。
可以从以下几个维度来理解这个Benchmark工具现在和未来将要扩展的工作负载类型。
1)从业务维度:针对市场、销售、运营、供应链、报表5方面的负载。
2)从数据源的维度:针对结构化数据、半结构化数据、非结构化数据。
3)数据处理的方式和类型的维度:声明型语言、结构化语言或者二者的混合。
4)从分析技术的维度:统计分析、数据挖掘分析和采样报告3个维度。
2.BigDataBenchmark
BigDataBenchmark[2]是由中科院计算所开发的一款开源的大数据Benchmark。BigDataBenchmark集成了19个大数据Benchmark,并从应用情景维度、运营和算法维度、数据类型维度、数据源维度以及软件栈和应用类型维度综合考虑,开发出这款Benchmark用来公正地对比和评判大数据系统和架构。BigDataBenchmark包含多样的数据输入类型。感兴趣的读者可以参见论文:BigDataBench:a Big Data Benchmark Suite from Internet Services,访问官方主页:http://prof.ict.ac.cn/BigDataBench/publications/。
BigDataBenchmark的设计基于典型的大数据负载。由于在生产环境中,大数据应用的主导领域是搜索引擎、社交网络、电商。这三大领域占据了整个互联网80%的页面。BigDataBenchmark围绕这三大方向选取和开发相应领域的典型负载。
数据生成器也是基于这3个领域开发和设计的。针对搜索引擎领域产生文本数据,针对社交网络产生图数据,针对电商产生结构化关系表数据。
同时针对三大领域生成不同计算延迟的负载。在线(online)需要短的延迟;离线(offline)需要进行复杂数据计算分析;实时(Real-Time)需要交互式分析的负载。
3.TPC-DS
SQL on Hadoop产品的本质就是数据仓库系统,其作用是在大规模分布式的环境下分析和查询离线数据。TPC-DS(注:参见:TPC BenchmarkTM DS (TPC-DS):The New Decision Support Benchmark Standard。)广泛用于SQL on Hadoop的产品评测。但是,目前TPC-DS基准已经很难模拟越来越复杂的决策支持系统的业务需求。
TPC-H的数据模型满足数据库模式设计的第三范式,数据模型不是现在决策支持系统主流的星型模型或者雪花型模型,业务类型也不能很好地体现物化视图和索引等OLAP型查询引擎的优势,而且其数据表不能表达数据倾斜问题,限制了索引的过度使用。为了应对这个挑战,TPC组织推出了TPC-DS,现在也正在制作和推出大数据领域的Benchmark,但还未发布。所以现在很多厂商和科研院所采用TPC-DS暂时作为SQL on Hadoop的大数据测试的Benchmark。
传统数据仓库使用的主流Benchmark就是TPC-DS。我们可以使用TPC-DS最高生成100TB的数据,能够满足大数据量的要求。数据模式采用雪花型模式:24个平均含有18列的数据库表,同时提供了99个典型Query供用户使用。这些Query类型丰富,如Ad-hoc Query、Reporting Query等,满足用户多方面的要求。
笔者在2013年参与学校DB-IIR实验室的SQL on Hadoop结构化大数据测试,采用TPC-DS作为Benchmark测试大数据分析系统,这个测试结果在中国大数据大会2013上发布,并在VL DB 2014的workshop上进行了公布。
当时采用的查询负载有以下几种。
(1)单表查询
- --qA5o--
- select ss_store_sk as store_sk, ss_sold_date_sk as date_sk
- ss_ext_sales_price as sales_price, ss_net_profit as profit
- from store_sales
- where ss_ext_sales_price>20
- order by profit
- limit 100;
- --qA9--
- select count(*) from store_sales
- where ss_quantity between 1 and 20
- limit 100;
(2)Ad hoc查询:—qB65g—(2表连接)
- select ss_store_sk,
- ss_item_sk,
- sum(ss_sales_price) as revenue
- from store_sales
- join date_dim on(store_sales.ss_sold_date_sk =date_dim.d_date_sk)
- where d_month_seq between 1176 and 1176+11
- group by ss_store_sk, ss_item_sk
- limit 100;
(3)星型查询:—qD27go—(5表连接)
- select i_item_id, s_state, avg(ss_quantity) agg1, avg(ss_list_price) agg2,
- avg(ss_coupon_amt) agg3, avg(ss_sales_price) agg4
- from store_sales ss
- join customer_demographics cd on(ss.ss_cdemo_sk = cd.cd_demo_sk)
- join date_dim dd on(ss.ss_sold_date_sk = dd.d_date_sk)
- join store s on(ss.ss_store_sk = s.s_store_sk)
- join item i on(ss.ss_item_sk = i.i_item_sk)
- where
- cd_gender = 'M' and
- cd_marital_status = 'S' and
- cd_education_status = 'College' and
- d_year = 2002 and s_state='TN'
- group by i_item_id, s_state
- order by i_item_id ,s_state
- limit 100 ;
(4)复杂查询:—qD6gho—(5表连接)
- select a.ca_state state, count(*) cnt
- from customer_address a
- join customer c on(a.customer_address.ca_address_sk =
- c.c_current_addr_sk)
- join store_sales s on(c.c_customer_sk = s.ss_customer_sk)
- join date_dim d on(s.ss_sold_date_sk = d.d_date_sk)
- join item i on(s.ss_item_sk = i.i_item_sk)
- group by a.ca_state
- having count(*) >= 10
- order by cnt
- limit 100;
[1] 参见论文:BigBench:Towards an Industry Standard Benchmark for Big Data Analytics。
[2] 参见:BigDataBench,A Big Data Benchmark Suite,ICT,Chinese Academy of Sciences。
