8.2.5 Spark Streaming实例
在互联网应用中,流数据处理是一种常用的应用模式,需要在不同粒度上对不同数据进行统计,保证实时性的同时,又需要涉及聚合(aggregation)、去重(distinct)、连接(join)等较为复杂的统计需求[1]。如果使用MapReduce框架,虽然可以容易地实现较为复杂的统计需求,但实时性却无法得到保证;反之,若是采用Storm这样的流式框架,实时性虽可以得到保证,但需求的实现复杂度也大大提高了。Spark Streaming在实时性与复杂统计需求之间的权衡中找到了一个平衡点,能够满足大多数用户的流计算需求。
Spark Streming是Spark的一个组成部分,提供高扩展性、容错的流处理功能。下面的例子基于Standalone的Spark程序,接收和处理Twitter的真实采样推特流。在这个例子中,用户可以选择使用Scala或者Java书写程序。
1.设置Setup
首先介绍基本的配置Spark Streaming程序的方法,然后介绍如何进行Twitter流身份验证令牌的配置。
(1)系统设置
1)twitter.txt:包含Twitter证书细节的文件。
2)目录介绍
①Scala用户:
·scala/sbt:包含SBT工具的目录。
·scala/build.sbt:SBT项目文件。
·scala/Tutorial.scala:主程序,需要用户编辑、编译和运行。
·scala/TutorialHelper.scala:包含一些帮助函数的Scala文件。
②Java用户:
·java/sbt:包含SBT工具的目录。
·java/build.sbt:SBT项目文件。
·java/Tutorial.java:Java主程序,需要用户编辑、编译和运行。
·java/TutorialHeler.java:包含一些帮助函数的Java文件。
·java/ScalaHelper.java:包含一些帮助函数的Scala文件。
用户需要编辑、编译和运行的主文件是Tutorial.scala或者Tutorial.java。注意:需要在模板文件中更改sparkUrl。
- import org.apache.spark._
- import org.apache.spark.SparkContext._
- import org.apache.spark.streaming._
- import org.apache.spark.streaming.twitter._
- import org.apache.spark.streaming.StreamingContext._
- import TutorialHelper._
- object Tutorial {
- def main(args: Array[String]) {
- /* Spark的目录*/
- val sparkHome = "/root/spark"
- /* Spark集群的Master 节点链接*/
- val sparkUrl = "local[4]"
- /* 应用所需的Jar包地址*/
- val jarFile = "target/scala-2.10/tutorial_2.10-0.1-SNAPSHOT.jar"
- /* 为了检查点而配置的HDFS目录 */
- val checkpointDir = TutorialHelper.getHdfsUrl() + "/checkpoint/"
- /* 使用 twitter.txt 配置twitter证书 */
- TutorialHelper.configureTwitterCredentials()
- /* 在此处书写用户代码 */
- }
- }
为了方便用户,例子中增加了一些帮助函数来配置需要的参数。
getSparkUrl()是一个帮助函数用于在/root/spark-ec2/cluster-url下获取Spark集群的URL。
configureTwitterCredential()是一个帮助函数。使用文件file/root/streaming/twitter.txt配置Twitter证书。这个配置将会在下面介绍。
(2)Twitter证书设置
由于所有的例子都是基于Twitter采样tweet流。首先需要有一个Twitter账号用来配置OAuth证书。为了达到这个目的,用户需要使用Twitter账号来设置一个消费者的key+secret对和访问token+secret对。请读者按照下面的步骤通过Twitter账号设置这些临时访问关键字。
1)打开链接https://dev.twitter.com/apps。用户页面罗列了基于Twitter的应用、应用的消费者关键字和访问令牌。如果没有创建任何应用,则这个页面是空的。在这个教程中,用户可以创建一个临时的应用。单击蓝色的“Create a new application”按钮,出现一个新应用的页面,如图8-16所示。需要填入一些信息:因为应用的名字(Name)必须是全局唯一的,所以可以使用Twitter的用户名作为前缀。描述(Description)字段可以随意设置。网址(Website)字段可以任意,但是需要确保是一个有http://前缀的全格式的URL。单击Developer Rules of the Road下面的“Yes,I agree”,最后单击“Create your Twitter application”按钮。
2)创建应用程序后,将会看到一个和图8-17相似的确认页面。用户可以获取consumer key和consumer secret。为了生成访问token和secret,需要单击页面底部的蓝色“Create my access token”按钮。注意:页面顶部会出现小的绿色确认信息,说明令牌已经生成。
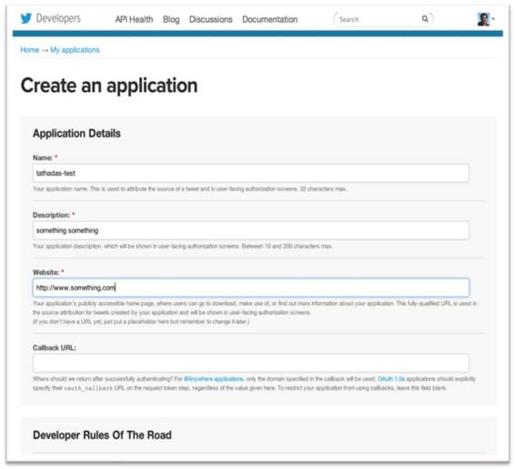
图8-16 填写应用信息
3)为了获取证书需要的所有key和secret,在页面的菜单顶部单击OAuth Tool,将会看到如图8-18所示的页面。
4)更新twitter.txt配置文件。
- cd /root/streaming/
- vim twitter.txt
用户会看到下面的模板。
- consumerKey =
- consumerSecret =
- accessToken =
- accessTokenSecret =
请用户复制之网页上相应参数值到这个配置文件对应位置,复制后,会出现类似下面的配置信息。
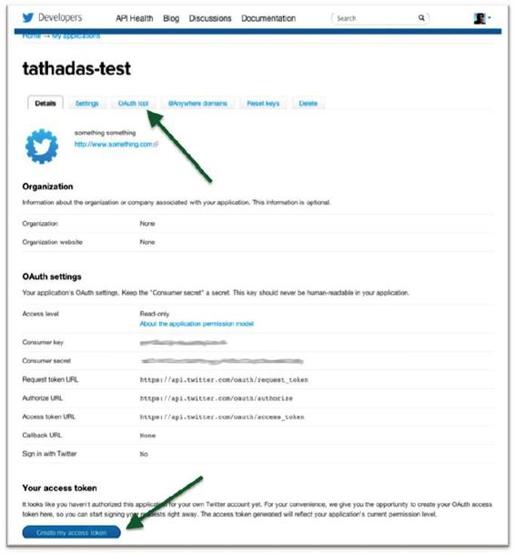
图8-17 确认页面

图8-18 OAuth Tool页面
- consumerKey = z25xt02zcaadf12 ...
- consumerSecret = gqc9uAkjla13 ...
- accessToken = 8mitfTqDrgAzasd ...
- accessTokenSecret = 479920148 ...
确认无误后,保存文件,就可以开发Spark Streaming程序了。
5)如果做完练习不再使用这个Twitter应用,可以到官网的页面单击Delete按钮,将应用删除,如图8-19所示。
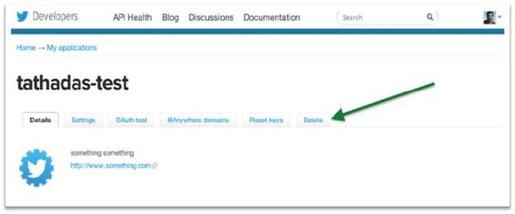
图8-19 删除应用页面
2.书写第一个Spark Streaming程序
下面介绍一个简单的Spark Streaming应用程序,它会每秒将接收到的推文打印出来。
1)打开并编辑Tutorial.scala文件。
- cd /root/streaming/scala/
- vim Tutorial.scala
2)创建StreamingContext对象。这个对象是Spark Streaming程序的入口。
- val ssc = new StreamingContext(sparkUrl, "Tutorial", Seconds(1), sparkHome, Seq(jarFile))
在本例中,创建了一个StreamingContext对象,并传入Spark集群的URL(sparkUrl)、流数据的批处理(batch)持续时间(Seconds(1))、Spark的根目录(sparkHome)程序运行需要的jar包jarFile)和应用程序名(Tutorial)。
- val tweets = TwitterUtils.createStream(ssc, None)
3)使用StreamingContext对象创建tweet数据流。
tweets对象是一个DStream对象,是一个源源不断的RDD流,RDD中的数据项就是twitter4j.Status对象。用户可以通过下面的语句打印出现在的数据流一探究竟。
- val statuses = tweets.map(status => status.getText())
- statuses.print()
类似本书前几章提到的RDD变换(transformation),tweets上的map算子作用在tweets对象上又创建了一个新的Dstream,叫作status。print函数打印DStream中每个RDD的前10条数据。
如果需要容错,可以调用Checkpoint方法,输入参数为HDFS的文件路径,将数据冗余存储在HDFS中。
- ssc.checkpoint(checkpointDir)
4)通过下面两个方法触发整个程序的运行。
- ssc.start()
- ssc.awaitTermination()
注意:上面的两个参数应该在用户做完所有操作之后再触发。
5)编辑好后保存Tutorial.scala文件,在根目录运行下面的命令。
- sbt/sbt package run
这个命令将会自动编译Tutorial类,并在/root/streaming/[language]/target/scala-2.10/.目录下创建jar包。最后运行这个程序,如果运行成功,将会在控制台看到类似下面的日志信息。
- -------------------------------------------
- Time: 1359886325000 ms
- -------------------------------------------
- RT @__PiscesBabyyy: You Dont Wanna Hurt Me But Your Constantly Doing It
- @Shu_Inukai ?????????????????????????????????????????
- @Condormoda Us vaig descobrir a la @080_bcn_fashion. Molt bona desfilada. Salutacions des de #Manresa
- RT @dragon_itou: ?RT???????3000???????????????????????????????????10???????
- ?????????????????2?3???9???? #???? http://t.co/PwyA5dsI ? h ...
- Sini aku antar ke RSJ ya "@NiieSiiRenii: Memang (?? ?`? )"@RiskiMaris: Stresss"@NiieSiiRenii: Sukasuka aku donk:p"@RiskiMaris: Makanya jgn"
- @brennn_star lol I would love to come back, you seem pretty cool! I just dont know if I could ever do graveyard again :( It KILLs me
- ????????????????????????????????????????????????????????????????????????????????????????ww
- ??????????
- When the first boats left the rock with the artificers employed on.
- @tgs_nth ????????????????????????????
- ……
- -------------------------------------------
- Time: 1359886326000 ms
- -------------------------------------------
- ???????????
- ???????????
- @amatuki007 ????????????????????????????????
- ?????????????????
- RT @BrunoMars: Wooh!
- Lo malo es qe no tiene toallitas
- Sayang beb RT @enjaaangg Piye ya perasaanmu nyg aku :o
- Baz? ?eyler yar??ma ya da reklam konusu olmamal? d???ncesini yenemiyorum.
- ?????????????MTV???????the HIATUS??
- @anisyifaa haha. Cukupla merepek sikit2 :3
- @RemyBot ?????????
- ……
[1] 示例参考http://ampcamp.berkeley.edu/big-data-mini-course/realtime-processing-with-spark-streaming.html。
