9.2.4 序列化与压缩
前面章节详细介绍了Spark的I/O机制,下面介绍I/O中的主要调优方向。
1.通过序列化优化
序列化的本质作用是将链式存储的对象数据,转化为连续空间的字节数组存储的数据。这样的存储方式就会产生以下几个好处。
1)对象可以以数据流方式进行进程间传输(包含网络传输),同样可以以连续空间方式存储到文件或者其他持久化层中。
2)连续空间的存储意味着可以进行压缩。这样减少数据存储空间和传输时间。
3)减少了对象本身的元数据信息和基本数据类型的元数据信息的开销。
4)对象数减少也会减少GC的开销和压力。
综上所述,数据进行序列化还是很有价值的。
Spark中提供了两个序列化库和两种序列化方式:使用Java标准序列化库进行序列化的方式和使用Kyro库进行序列化的方式。Java标准序列化库兼容性好,但体积大、速度慢,Kyro库兼容性略差,但是体积小、速度快。所以在能使用Kyro的情况下,还是推荐使用Kyro进行序列化。
可以通过spark.serializer="org.apache.spark.serializer.KryoSerializer"来配置是否使用Kyro进行序列化,这个配置参数决定了Shuffle进行网络传输和当内存无法容纳RDD将分区写入磁盘时,使用的序列化器的类型。
在分布式应用中,序列化处于举足轻重的地位。那些需要大量时间进行序列化的数据格式和占据过大空间的对象会拖慢整个应用。通常情况下,序列化是Spark调优的第一步。Spark为了权衡兼容性和性能提供了两种序列化库。
(1)Java标准序列化库
在默认情况下,Spark使用ObjectOutputStream框架进行对象的序列化。可以通过实现java.io.Serializable接口,使对象可以被序列化,也可以扩展java.io.Externalizable进而控制序列化的性能。Java标准序列化库很灵活,并且兼容性好,但是通常情况下,速度较慢,而且导致序列化后数据量较大。
(2)Kyro序列化库
Spark也可以使用Kyro序列化库来更加快速地序列化对象。Kyro相对于Java序列化库能够更加快速和紧凑地进行序列化(通常有10倍的性能优势),但是Kyro并不能支持所有可序列化的类型,如果对程序有较高的性能优化要求,就需要自定义注册类。官方推荐对于网络传输密集型(network-intensive)计算,采用Kyro序列化性能更好。
Spark自动引入了对许多常用的Scala核心类的Kyro的序列化支持,这些类均是在Spark使用的Twitter chill库支持的类。
(3)序列化示例
下面通过一个例子演示如何自定义一个Kryo的可序列化的类。
创建一个公共类,这个类要扩展org.apache.spark.serializer.KryoRegistrator,然后配置spark.kryo.registrator指向它,代码如下。
- import com.esotericsoftware.kryo.Kryo
- import org.apache.spark.serializer.KryoRegistrator
- class MyRegistrator extends KryoRegistrator {
- override def registerClasses(kryo: Kryo) {
- kryo.register(classOf[MyClass1])
- kryo.register(classOf[MyClass2])
- }
- }
- val conf = new SparkConf().setMaster(...).setAppName(...)
- conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
- conf.set("spark.kryo.registrator", "mypackage.MyRegistrator")
- val sc = new SparkContext(conf)
Kyro序列化库的官方文档上描述了更加高级的一些注册方式,如增加自定义序列化代码,用户在使用时可以参考相应文档中的样例,文档网址是https://code.google.com/p/kryo/。
如果对象占用空间很大,需要增加Kryo的缓冲区容量,就需要增加配置项spark.kryoserializer.buffer.mb的数值,默认是2MB,但参数值应该足够大,以便容纳最大的序列化后对象的传输。
如果用户不注册自定义的类,Kyro仍可以运行,但是它会针对每个对象存储一次整个类名,这样会造成很大的空间浪费。
2.通过压缩方式优化
在Spark中对RDD或者Broadcast数据进行压缩,是提高数据吞吐量和性能的一种手段。压缩数据,可以大量减少磁盘的存储空间,同时压缩后的文件在磁盘间传输和I/O以及网络传输的通信开销也会减小;当然压缩和解压缩也会带来额外的CPU开销,但可以节省更多的I/O和使用更少的内存开销。
在Spark应用中,有很大一部分作业是I/O密集型的。数据压缩对I/O密集型的作业带来性能的大大提升,但是如果用户的jobs作业是CPU密集型的,那么再压缩就会降低性能,这就要判断作业的类型,权衡是否要压缩数据。
压缩数据,可以最大限度地减少文件所需的磁盘空间和网络I/O的开销,但压缩和解压缩数据总会增加CPU的开销,故最好对那些I/O密集型的作业使用数据压缩——这样的作业会有富余的CPU资源,或者对那些磁盘空间不富裕的系统。
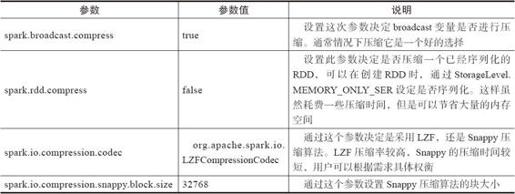
Spark目前支持LZF和Snappy两种解压缩方式。Snappy提供了更高的压缩速度,LZF提供了更高的压缩比,用户可以根据具体的需求选择压缩方式。具体的介绍可以参见第2章。可以通过表9-1的配置参数配置压缩。
表9-1 压缩配置