4 提高叠加处理速度(2)(harib07d)
虽然我们想了如此多的办法,但结果还是没有达到我们的期望,真让人郁闷。到底是怎么回事呢?原来还是refreshsub有些问题。
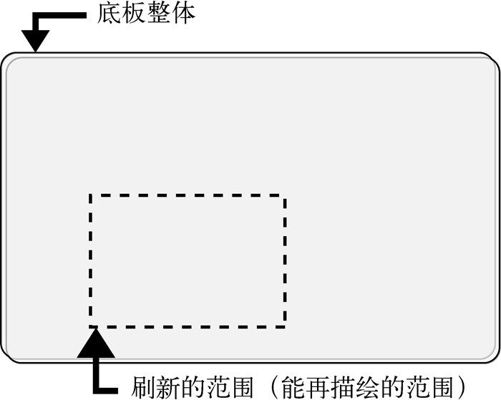
不是太快的refreshsub
void sheet_refreshsub(struct SHTCTL *ctl, int vx0, int vy0, int vx1, int vy1){int h, bx, by, vx, vy;unsigned char *buf, c, *vram = ctl->vram;struct SHEET *sht;for (h = 0; h <= ctl->top; h++) {sht = ctl->sheets[h];buf = sht->buf;for (by = 0; by < sht->bysize; by++) {vy = sht->vy0 + by;for (bx = 0; bx < sht->bxsize; bx++) {vx = sht->vx0 + bx;if (vx0 <= vx && vx < vx1 && vy0 <= vy && vy < vy1) {c = buf[by * sht->bxsize + bx];if (c != sht->col_inv) {vram[vy * ctl->xsize + vx] = c;}}}}}return;}
依照这个程序,即使不写入像素内容,也要多次执行if语句,这一点不太好,如果能改善一下,速度应该会提高不少。
■■■■■
按照上面这种写法,即便只刷新图层的一部分,也要对所有图层的全部像素执行if语句,判断“是写入呢,还是不写呢”。而对于刷新范围以外的部分,就算执行if判断语句,最后也不会进行刷新,所以这纯粹就是一种浪费。既然如此,我们最初就应该把for语句的范围限定在刷新范围之内。
基于以上思路,我们做好了改良版本。
本次的*sheet.c节选
void sheet_refreshsub(struct SHTCTL *ctl, int vx0, int vy0, int vx1, int vy1){int h, bx, by, vx, vy, bx0, by0, bx1, by1;unsigned char *buf, c, *vram = ctl->vram;struct SHEET *sht;for (h = 0; h <= ctl->top; h++) {sht = ctl->sheets[h];buf = sht->buf;/* 使用vx0~vy1,对bx0~by1进行倒推/bx0 = vx0 - sht->vx0;by0 = vy0 - sht->vy0;bx1 = vx1 - sht->vx0;by1 = vy1 - sht->vy0;if (bx0 < 0) { bx0 = 0; } /* 说明(1) */if (by0 < 0) { by0 = 0; }if (bx1 > sht->bxsize) { bx1 = sht->bxsize; } /* 说明(2) */if (by1 > sht->bysize) { by1 = sht->bysize; }for (by = by0; by < by1; by++) {vy = sht->vy0 + by;for (bx = bx0; bx < bx1; bx++) {vx = sht->vx0 + bx;c = buf[by * sht->bxsize + bx];if (c != sht->col_inv) {vram[vy * ctl->xsize + vx] = c;}}}}return;}
改良的关键在于,bx在for语句中并不是在0到bxsize之间循环,而是在bx0到bx1之间循环(对于by也一样)。而bx0和bx1都是从刷新范围“倒推”求得的。倒推其实就是把公式变形转换了一下,具体如下:
vx = sht->vx0 + bx; → bx = vx - sht->vx0;
计算vx0的坐标相当于bx中的哪个位置,然后把它作为bx0。其他的坐标处理方法也一样。
■■■■■
这样算完以后,就该执行以上程序中说明(1)的地方了。这行代码用于处理刷新范围在图层外侧的情况。什么时候会出现这种情况呢?比如在sht_back中写入字符并进行刷新,而且刷新范围的一部分被鼠标覆盖的情况。
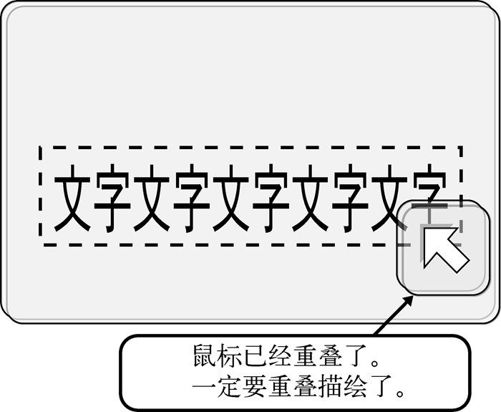 |  | |
| 刷新范围与鼠标的图层像这样重叠在一起 | 这时候的vx和vy |
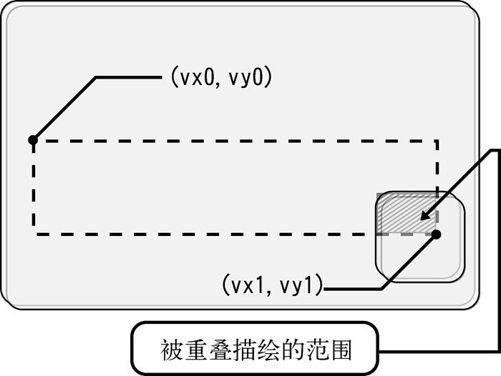
假设在这种情况下h=1,且想要重复刷新鼠标的图层,那么就变成了下面这样。
对sheets[1]进行bx0~bx1计算的时候
在这里必须要进行重复描绘的只有与鼠标图层重叠的那一小块范围,而其他部分并没有被要求刷新,所以不能刷新。这样的话,可以把bx0和by0置0。
■■■■■
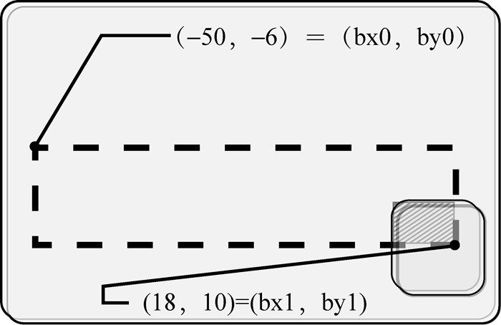
程序中“说明(2)”部分所做的,是为了应对不同的重叠方式。
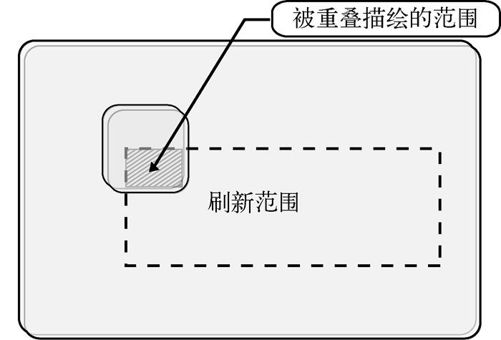
需要执行“说明(2)”部分的情形
在这种情况下,bx0和by0虽然可以从vx0和vy0顺利求取, 但bx1和by1就变得太大了(超出了图层的范围),因此要修改这里。
第三种情况是完全不重叠的情况。例如,鼠标的图层往左移动直至不再重叠。此时当然完全不需要进行重复描绘,那么程序是否可以正常运行呢?
利用倒推计算得出的bx0和bx1都是负值,在说明(1)中,仅仅bx0被修正为0,而在说明(2) 中bx1没有被修正,还是负的。这样的话,for(bx = bx0;bx < bx1;bx++)这个语句里的循环条件bx < bx1从最开就不成立,所以for语句中的命令得不到循环,这样就完全不会进行重复描绘了,很好。
■■■■■
仅仅改了这些地方,就可以提高速度吗?我们来试一下。“make run”(要等待一会儿)吗?哦,这次感觉很好,操作系统正在迅速地运行,太开心了!虽然从表面上看不出有什么不同,不过这次我们要附上照片,展示一番。太棒了!
太好了!真开心。
纪念照片也拍完了(笑),在这里我们看一下haribote.sys的大小吧。哦,是11 104字节。除以1024的话,大约是10.8,也就是10.8KB。……我们的系统正在茁壮成长! 到这里可以暂时告一段落了,那好,我们今天就到此结束吧。明天见!
