5 IPL的改良(harib27e)
进入本章以后(尤其是在测试mmlplay.hrb的时候),笔者在真机环境下运行了几次“纸娃娃系统”,发现启动时读取磁盘的时间还是有点长。现在我们是读取20个柱面,如果能减少到14或者18个这样勉强够用的柱面数的话,启动速度就可以加快了(不过代价是,以后新增文件的时候又要重新调整)。
于是我们先用二进制编辑器查看一下harib27d的haribote.img文件,发现数据占用的部分是到028C98为止。额,这是多少个柱面呢?一个柱面是512×18×2=18432字节(当然,这是用calc.hrb计算的哟!……笑),因此0x28c99 / 18432=9个柱面。
什么!只要9个柱面就够了吗?!真奇怪,当初明明是因为10个柱面不够用我们才特地抛弃了ipl10.nas改用ipl20.nas的呀?哦,对了,我们用tek对nihongo.fnt进行了压缩,因此大幅度减少了容量,真开心呀。那我们将ipl10.nas还原回去就好了呢,这样启动时间就只有现在的一半了。
不过且慢,0x28c99 % 18432=1193字节(求余数运算用calc.hrb也可以轻松搞定,真方便),也就是说,如果我们能再将文件容量缩减1KB左右,就可以将读取的范围缩小到9个柱面了,这样一来启动时间又可以缩短一成。好,我们加油试试看,有什么好办法呢?啊,有了,我们将ipl20.nas也用tek压缩一下就好了呢!如果可以减小3个扇区的话,ipl09.nas就足够了。
■■■■■
嗯,既然要做ipl09.nas的话,不如顺便对磁盘读取做个优化。这里所说的优化,是将AL = 1这样逐个扇区读取的方法,改为同时读取多个扇区(参见3.1节和3.3节)。至于这种优化是否会带来速度上的提升则是因人而异的。在大部分内置软驱的电脑上,逐个扇区读取的速度可能已经相当快了,优化之后速度也不会有什么提升。不过像笔者这样使用USB1.1外置软驱来启动的话,优化之后大约可以比原来的速度提高10倍左右。
ipl09.nas节选
; haribote-ipl; TAB=4CYLS EQU 9 ; 要读取多少内容; (中略); 读取磁盘MOV AX,0x0820MOV ES,AXMOV CH,0 ; 0柱面MOV DH,0 ; 0磁头MOV CL,2 ; 2扇区MOV BX,18*2*CYLS-1 ; 要读取的合计扇区数 从此开始CALL readfast ; 告诉读取; 读取结束,运行haribote.sys!MOV BYTE [0x0ff0],CYLS ; 记录IPL实际读取了多少内容 到此结束JMP 0xc200error:MOV AX,0MOV ES,AXMOV SI,msgputloop:MOV AL,[SI]ADD SI,1 ; 将SI加1CMP AL,0JE finMOV AH,0x0e ; 显示一个字符的函数MOV BX,15 ; 颜色代码INT 0x10 ; 调用显示BIOSJMP putloopfin:HLT ; 暂时让CPU停止运行JMP fin ; 无限循环msg:DB 0x0a, 0x0a ; 两个换行DB "load error"DB 0x0a ; 换行DB 0readfast: ; 使用AL尽量一次性读取数据 从此开始; ES:读取地址, CH:柱面, DH:磁头, CL:扇区, BX:读取扇区数MOV AX,ES ; < 通过ES计算AL的最大值 >SHL AX,3 ; 将AX除以32,将结果存入AH(SHL是左移位指令)AND AH,0x7f ; AH是AH除以128所得的余数(512*128=64K)MOV AL,128 ; AL = 128 - AH; AH是AH除以128所得的余数(512*128=64K)SUB AL,AHMOV AH,BL ; < 通过BX计算AL的最大值并存入AH >CMP BH,0 ; if (BH != 0) { AH = 18; }JE .skip1MOV AH,18.skip1:CMP AL,AH ; if (AL > AH) { AL = AH; }JBE .skip2MOV AL,AH.skip2:MOV AH,19 ; < 通过CL计算AL的最大值并存入AH >SUB AH,CL ; AH = 19 - CL;CMP AL,AH ; if (AL > AH) { AL = AH; }JBE .skip3MOV AL,AH.skip3:PUSH BXMOV SI,0 ; 计算失败次数的寄存器retry:MOV AH,0x02 ; AH=0x02 : 读取磁盘MOV BX,0MOV DL,0x00 ; A盘PUSH ESPUSH DXPUSH CXPUSH AXINT 0x13 ; 调用磁盘BIOSJNC next ; 没有出错的话则跳转至nextADD SI,1 ; 将SI加1CMP SI,5 ; 将SI与5比较JAE error ; SI >= 5则跳转至errorMOV AH,0x00MOV DL,0x00 ; A盘INT 0x13 ; 驱动器重置POP AXPOP CXPOP DXPOP ESJMP retrynext:POP AXPOP CXPOP DXPOP BX ; 将ES的内容存入BXSHR BX,5 ; 将BX由16字节为单位转换为512字节为单位MOV AH,0ADD BX,AX ; BX += AL;SHL BX,5 ; 将BX由512字节为单位转换为16字节为单位MOV ES,BX ; 相当于EX += AL * 0x20;POP BXSUB BX,AXJZ .retADD CL,AL ; 将CL加上ALCMP CL,18 ; 将CL与18比较JBE readfast ; CL <= 18则跳转至readfastMOV CL,1ADD DH,1CMP DH,2JB readfast ; DH < 2则跳转至readfastMOV DH,0ADD CH,1JMP readfast.ret:RET ; 到此结束RESB 0x7dfe-$ ; 到0x7dfe为止用0x00填充的指令DB 0x55, 0xaa
完工,代码中加入了很多注释,应该没有什么特别难懂的地方了。
■■■■■
哎呀呀,糟糕!我们修改了ipl09.nas之后,为了实现对磁盘读取的优化,结果代码却变长了。和ipl20.nas相比,从2992字节增加到了4081字节。不过大家也不用担心,我们还有tek5压缩呢,压缩之后就变成了1778字节。你看,变小了很多吧。
我们修改一下Makefile,将这个新文件装入磁盘映像,然后“make”,再用二进制编辑器打开生成好的磁盘映像确认一下。唔,貌似数据占用的部分到028898。0x28899 / 18432 = 9个柱面,0x28899 % 18432 = 153字节……什么!居然超出了153字节?!不是吧!
如果在这里乖乖就范,换回ipl10.nas的话也太憋屈了,于是我们可以抛弃其中一个应用程序,比如sosu或者hello之类的。能抛弃的应用程序实在是太多了(苦笑),反而不知道该抛弃哪个比较好了1。呜呜呜!
1 大家可千万别说“这种程序全部丢掉算了”这种话,虽然这个主意挺正确的,但实在是太“残忍”了。这些应用程序中可满载着这些日子我们开发工作中所留下的回忆啊!
既然如此,我们就下定决心,一定要在一个都不能少的前提下,解决这个问题。唔,到底怎么办才好呢……有了!我们将invader.hrb修改一下,如果不用sprintf函数的话,程序就可以变小了!
■■■■■
invader.c中只有一处调用了sprintf,因此修改起来也很简单,首先替换下面一句:
sprintf(s, "%08d", score); → setdec8(s, score);
然后再添加下面这个函数:
本次的invader.c节选
void setdec8(char *s, int i)/*将i用十进制表示并存入s*/{int j;for (j = 7; j >= 0; j--) {s[j] = '0' + i % 10;i /= 10;}s[8] = 0;return;}
这样就完工了,仅通过这一点修改,invader.hrb就从2335字节变成了1509字节,大幅度瘦身了,大获全胜!反过来说,sprintf这个函数是如此之大,真是减肥瘦身的大敌呢(笑)。
当然,修改了之后的invader.hrb运行起来不会有任何变化,不信的话可以“make run”试试看哦。
■■■■■
修改完成之后,我们再重新“make”一下磁盘映像,并用二进制编辑器打开看看,数据占用的部分到028498。0x28499 / 18432 = 8个柱面,0x28499 % 18432 = 17561字节,正好缩减到9个柱面的范围内,撒花!
到此为止,我们的应用程序编写活动也该告一段落了,我们来总结一下本章的成果吧。
invader.hrb……1509字节:外星人游戏
calc.hrb……1668字节:命令行计算器
tview.hrb……1753字节:文本阅览器
mmlplay.hrb……1975字节:MML播放器
gview.hrb……3865字节:图片阅览器
看起来从上到下文件的大小是在不断递增的呢。虽然很有趣,不过这只是个巧合啦。
最后我们来一张纪念截图吧。
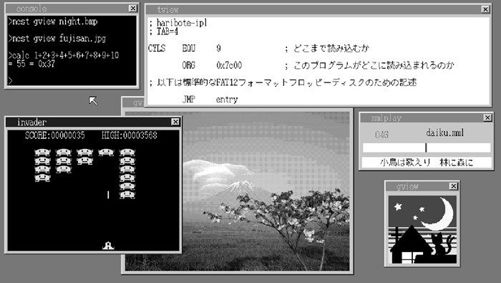
大家来拍个全家福
