5 日文文字显示(1)(harib25e)<sup>1</sup>
1 本章中作者为大家讲解了如何实现对日文显示的支持,由于本书涉及大量操作系统底层功能的实现,可谓牵一发而动全身,因此在翻译过程中我们原原本本地呈现了关于日文显示的内容。和中文一样,在日文中也有大量的汉字,因此日文显示和中文显示实现起来有很多相似的地方,而且中文显示比日文显示在实现上还相对简单一些。我们在相关章节中补充了一些关于中文显示的内容供大家参考,希望大家本着求同存异的原则,能够对相关知识有一个更加深入的了解。
我们终于等到了这个时刻,那就是对日文显示的支持,估计很多人早就摩拳擦掌盼着实现这个功能吧,其实笔者也很期待呢。日文显示,其实说到底只要准备好相应的字库就好了。
如果将字库内置到操作系统核心中的话,操作系统会变得很大,而且要更换新字体时还必须重新make一遍。因此我们不将日文字库内置到haribote.sys中,而是单独生成一个名叫nihongo.fnt的文件,在“纸娃娃系统”启动时先检查是否存在该文件,如果存在则自动将其读入内存。
■■■■■
那么这样一个字库文件到底有多大呢?我们不妨来计算一下。日文的字符基本上都是用全角来显示的,相对于8 × 16点阵的半角字符来说,1个全角字符的大小为16×16点阵。如果1个半角字符的字库数据需要16字节的话,那么1个全角字符就需要32字节。
日文汉字编码表按照使用频率分类,常用的汉字为第一水准,偶尔使用的汉字为第二水准,基本上不会用到的汉字为第三水准,用得更少的为第四水准(这样的分类是以总体使用情况为基准的,如果你的名字或者住址里面用到了第四水准汉字,那对于你来说可能就会出现“第四水准汉字更加常用”的情况哦)。
在JIS制定的汉字编码表中,非汉字加上第一水准汉字~第三水准汉字一共有94×94=8836个字符(再加上第四水准汉字的话就更多了)。如果我们要用上所有的这8836个字符的话,就需要32×8836=282752字节的容量,也就是276KB!2
2 在中文汉字编码标准GB2312中,也按照汉字的常用度划分了一级汉字和二级汉字,其中一级汉字3755个,二级汉字3008个,再加上非汉字(拉丁字母、希腊字母等)字符682个,一共有7445个字符,基本上与上述JIS编码中非汉字加第一~第三水准汉字的容量相当。——译者注
276KB实在是太大了,虽然这个大小还能够装进软盘,但差不多消耗了软盘总容量的20%。这么大的文件,用type ipl10.nas是不行了,必须要在启动时读取更多的扇区,可这样一来在真机环境下的启动速度又要变慢了,看来我们必须要给字库文件瘦瘦身。
■■■■■
根据JIS规格,全角字符的编码以“点、区、面”为单位来进行定义,点和区的关系类似于几号楼几单元,比如说“3号楼4单元”可以类比成“3区4点”,而面则是比它们更大的一个单位。
1个点就对应1个全角字符
1个区中包含94个点
1个面中包含94个区
第一水准~第三水准全部位于1面,第四水准全部位于2面3
3 这一段是不是有点看不懂呢?其实以前的编码表示方法更加简单一些。例如,“あ”(注:日文平假名,读作“啊”)这个字符的编码为0x2422,“川”的编码为0x406e,这种方法比较简单吧,因为每一个字符都有它对应的一个编号。但现在我们所使用的表示方法和以前不同,按照现在的方法,“あ”的字符编码为1面04区02点,“川”的字符编码为1面32区78点。
其实将以前的编码转换为现在的编码也不难,只要将二进制的4位数字编码中前两位和后两位拆开,再各自减掉0x20就可以了。例如“あ”是0x2422,转换后得到0x04、0x02,将这两个数字转换为10进制就分别对应了区号和点号。“川”也一样,将0x406e拆开并各自减掉0x20,得到0x20和0x4e,因此是32区78点。
字符编码大致可分为下面几类。
01区~13区:非汉字
14区~15区:第三水准汉字
16区~47区:第一水准汉字
48区~84区:第二水准汉字
84区~94区:第三水准汉字4
4 有人可能会问,84区不是已经包含在第二水准汉字中了吗?这里再补充说明一下,根据定义,84区前面为第二水准汉字,后面为第三水准汉字。——译者注
这次我们为了节省容量,准备只将01区~47区装入nihongo.fnt中,这样的话就只需要47×94×32=141376字节,也就是之前的差不多一半大小,启动时间也应该不会很长了。如果大家觉得这样不好,想要把第二、第三水准汉字也全部显示出来的话,不要客气,欢迎大胆改造哦。6
5 在GB2312汉字标准中,字符的定位也是采用类似日文“点区面”的方式,不过GB2312中没有面的概念(或者可以说,GB2312的字符集只有1个面),而区和点我们称为“区位”,和日文一样,每个区包含94个位(即94个字符),例如“啊”字位于16区1位。GB2312中的字符也可以采用二进制编码的方式来表示,相对于日文JIS标准中将区和点的编号加上0x20的做法,GB2312中是将区和位的编号加上0xa0,例如“啊”字区位编码加上0xa0后为:0x10(16)+0xa0=0xb0,0x01(1)+0xa0=0xa1,因此“啊”字的二进制字符编码为0xb0a1。——译者注
在GB2312中,字符编码的分类如下:
01区~09区:非汉字
10区~15区:空白
16区~55区:一级汉字
56区~87区:二级汉字
88区~94区:空白
如果为了节省容量,我们可以只使用非汉字和一级汉字的部分,即01区~55区的部分,一共需要55×94×32=165440字节。
■■■■■
接下来我们需要考虑的就是字库的字模数据。即便我们只选用01区~47区,其中也包括了47×94=4418个字符。如果要一个一个字符去设计字模的话,那比编写一个操作系统还要花时间。因此这次我们还是和当初的半角字库一样,直接从笔者正在开发的OSASK中借用字模吧(OSASK的日文字库版权属于泊何水和圣人[Kiyoto])。
SASK中的字库文件为jpn16v00.fnt,大小为304KB。不过OSASK和“纸娃娃系统”一样,都是以安装在软盘上使用为前提而设计的,304KB对于软盘来说负担重了些,因此在OSASK中将这个文件进行了压缩,大小变成了56.7KB6。于是我们首先需要对字库文件进行解压缩(否则我们无法拿到里面的数据)。
6 jpn16v00.fnt分为两个版本,一个只包含第一水准汉字,另一个包含从第一到第三水准的全部汉字,56.7KB的是只包含第一水准汉字的版本,48区~94区的内容是空白的。
笔者编写的大多数工具程序中都内置了解压缩的功能,随便使用任何一个工具都可以完成解压缩的操作,这次我们以edimg为例。
提示符> edimg copy nocmp: from:jpn16v00.fnt to:jpn16v00.bin
(这里没有考虑文件路径,请大家根据需要自行加上路径)
好,这样我们就得到了304KB的jpn16v00.bin文件。
下面我们将01区~47区的字模数据提取出来,只要将jpn16v00.bin从开头算起的前141376字节提取出来就可以了,用二进制编辑器可以轻松搞定。
说起日文显示,我们还需要半角片假名的字库。可能有人会说,我从来不用半角片假名。不过,能显示总比不能显示要好吧,所以我们还需要提取半角片假名的字模数据。在jpn16v00.bin中已经包含了显示日文用的半角片假名字模,总共256个字符,位于04A000~04AFFF,共4096字节。
最终nihongo.fnt的内容如下。
000000~000FFF:显示日文用半角字模,共256个字符(4096字节)
001000~02383F:显示日文用全角字模,共4418个字符(141376字节)
至于提取数据的方法嘛,其实笔者就是用二进制编辑器复制粘贴的(笑)。虽然可能有更棒的工具来做这件事,不过笔者认为没必要在这种事情上面花太多心思。
(5分钟之后)完工啦,不错不错。7
7 由于作者开发的OSASK系统中并不包含中文字库,各位读者如果需要改造源代码以实现中文显示的支持,则需要获取一个符合GB2312标准的中文点阵字库文件(例如UCDOS中包含的HZK16),并提取前165440字节制作成一个仅包含一级汉字的子集。由于汉字显示不需要涉及半角片假名的问题,因此最终在“纸娃娃系统”中所使用的.fnt文件中000000~000FFF的256个半角字符部分,我们可以直接使用5.5节中生成的字模数据(即“纸娃娃系统”的内置英文字库)。综上所述,要实现中文显示,所需的.fnt文件结构可以是下面这样:
000000~000FFF:英文半角字模,共256个字符(4096字节),来自系统内置字库数据
001000~02963F:中文全角字模,共5170个字符(165440字节),来自HZK16或其他符合GB2312标准的汉字点阵字库
■■■■■
接下来,我们需要修改bootpack.c,使操作系统可以自动装载字库。
本次的bootpack.c节选
void HariMain(void){(中略)int *fat;unsigned char *nihongo;struct FILEINFO *finfo;extern char hankaku[4096];(中略)/*载入nihongo.fnt */nihongo = (unsigned char *) memman_alloc_4k(memman, 16 * 256 + 32 * 94 * 47);fat = (int *) memman_alloc_4k(memman, 4 * 2880);file_readfat(fat, (unsigned char *) (ADR_DISKIMG + 0x000200));finfo = file_search("nihongo.fnt", (struct FILEINFO *) (ADR_DISKIMG + 0x002600), 224);if (finfo != 0) {file_loadfile(finfo->clustno, finfo->size, nihongo, fat, (char *) (ADR_DISKIMG + 0x003e00));} else {for (i = 0; i < 16 * 256; i++) {nihongo[i] = hankaku[i]; /*没有字库,半角部分直接复制英文字库*/}for (i = 16 * 256; i < 16 * 256 + 32 * 94 * 47; i++) {nihongo[i] = 0xff; /*没有字库,全角部分以0xff填充*/}}*((int *) 0x0fe8) = (int) nihongo;memman_free_4k(memman, (int) fat, 4 * 2880);(中略)}
首先分配出用于存放nihongo.fnt内容的内存空间,然后寻找文件,如果找到的话则载入内存。如果没有找到字库文件,则只好用内置的半角字库代替日文半角字库,并用方块填充全角字库的部分。最后,将用于存放nihongo.fnt内容的内存地址写入0x0fe8作为记录。
■■■■■
下面我们该实现用日文字库来显示字符了。字符显示是由graphic.c中的putfonts8_asc来负责的,所以我们就先修改这里吧。
本次的bootpack.h节选
struct TASK {(中略)char langmode;};
本次的graphic.c节选
void putfonts8_asc(char *vram, int xsize, int x, int y, char c, unsigned char *s){extern char hankaku[4096]; /*这里没有修改*/struct TASK *task = task_now();char *nihongo = (char *) *((int *) 0x0fe8);if (task->langmode == 0) {for (; *s != 0x00; s++) { /*从这里起没有修改*/putfont8(vram, xsize, x, y, c, hankaku + *s * 16);x += 8;} /*到这里为止没有修改*/}if (task->langmode == 1) {for (; *s != 0x00; s++) {putfont8(vram, xsize, x, y, c, nihongo + *s * 16);x += 8;}}return; /*这里没有修改*/}
我们在struct TASK里添加了一个langmode(即language mode,语言模式)变量,用于指定一个任务是使用内置的英文字库还是使用nihongo.fnt的日文字库。通过在struct TASK中添加这个变量,我们可以对每个任务单独设置语言模式,例如为某个应用程序设置日文模式,而为另一个应用程序设置英文模式。
■■■■■
既然我们设计了这个语言模式的变量,那么就需要一个命令来对模式进行设定。
本次的console.c节选
void cons_runcmd(char *cmdline, struct CONSOLE *cons, int *fat, int memtotal){(中略)} else if (strncmp(cmdline, "langmode ", 9) == 0) {cmd_langmode(cons, cmdline);} else if (cmdline[0] != 0) {(中略)}void cmd_langmode(struct CONSOLE *cons, char *cmdline){struct TASK *task = task_now();unsigned char mode = cmdline[9] - '0';if (mode <= 1) {task->langmode = mode;} else {cons_putstr0(cons, "mode number error.\n");}cons_newline(cons);return;}
完工了,现在只要输入“langmode 0”就代表设定为英文模式,输入“langmode 1”就代表设定为日文模式。
■■■■■
不过,在命令行窗口启动时没有设定langmode,这有点不方便,我们来设定一个默认值。
本次的console.c节选
void console_task(struct SHEET *sheet, int memtotal){(中略)unsigned char *nihongo = (char *) *((int *) 0x0fe8);(中略)if (nihongo[4096] != 0xff) { /*是否载入了日文字库?*/task->langmode = 1;} else {task->langmode = 0;}(中略)}
这样一来,当成功载入日文字库时,默认值为日文模式,否则默认为英文模式。要想知道是否成功载入了日文字库,只要判断01区01点的内容就可以了。如果没有载入字库,这里应该是填充了0xff,如果载入了字库,那么由于01区01点所对应的字符是全角空格,因此这里应该是0x00。
到这,我们就差不多大功告成了,不过task_a的langmode还没设定,因此我们再稍微修改一下HariMain。
本次的bootpack.c节选
void HariMain(void){(中略)init_palette();shtctl = shtctl_init(memman, binfo->vram, binfo->scrnx, binfo->scrny);task_a = task_init(memman);fifo.task = task_a;task_run(task_a, 1, 2);*((int *) 0x0fe4) = (int) shtctl;task_a->langmode = 0; /*这里!*/(中略)}
这样task_a就设定为英文模式了。
■■■■■
下面我们可以开始编写用来测试的应用程序了,只是现在我们还无法显示全角字符,只能显示半角字符。不过即便如此,我们也可以测试出是否能成功载入nihongo.fnt(全角字符的显示在下一节实现)。
由于只能显示半角字符,因此我们来显示几个半角片假名“イロハニホヘト”(注:读作I RO HA HI HO HE TO,是日本平安时代诗歌《伊吕波歌》的第一句)吧。
iroha.c
#include "apilib.h"void HariMain(void){static char s[9] = { 0xb2, 0xdb, 0xca, 0xc6, 0xce, 0xcd, 0xc4, 0x0a, 0x00 };/*半角片假名イロハニホヘト的字符编码+换行+0 */api_putstr0(s);api_end();}
在这个程序中我们特地声明了一个s[]用来保存要显示字符串,有人可能会说,那为啥不直接写成下面这样呢?
api_putstr0(“イロハニホヘト\n”);
这样写的话在Windows中可能没问题,但在Linux中可能就不行了。准确地说,其实这并不是操作系统的问题,而是字符编码方式的问题。
说到底,字符串就是一串按顺序排列的字符编码,而对于半角片假名应该赋予怎样的编码,有着不同的标准。在Windows常用的“Shift-JIS”8编码中,半角的“イロハニホヘト”的字符编码和s[]中的值一模一样,但在Linux常用的“日文EUC”编码中,则变成了形如0x8e, 0xb2, 0x8e, 0xdb, 0x8e, 0xca, 0x8e, 0xc6, …这样的排列,即在每个半角片假名前都加上了一个0x8e。
8 其实“Shift-JIS“这个名称是不正确的,准确名称应该是“MS汉字编码“,不过反倒是“Shift-JIS“的使用最广泛。
最近出现了一些功能强大的文本编辑器,可以选择字符编码方式,也就是说,在Windows中也可以按EUC编码保存,而在Linux中也可以按Shift-JIS编码保存了,所以刚刚我们也说了,这并不完全是操作系统的问题。
因此,如果直接写成“MS Mincho\n”的话,根据字符编码方式的不同,最终形成的字符串(数值的排列)也会不同,所以我们需要用二进制数字逐个来写出字符的编码,这样一来,即便在Linux下make这个程序,也应该可以得到完全相同的可执行文件。
■■■■■
好了,我们来“make run”试试看。能不能成功呢?我们已经修改了Makefile,将nihongo.fnt加入到磁盘映像中了,因此默认的语言模式应该是日文模式。哦哦,显示出来了!
如果我们先执行“langmode 0”然后再运行iroha.hrb的话,就会显示出下面这样的乱码,这也验证了我们编写的程序成功运行了,撒花!
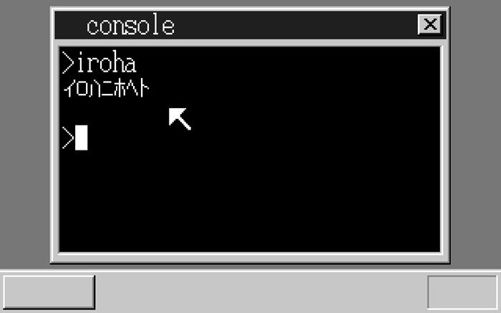 | 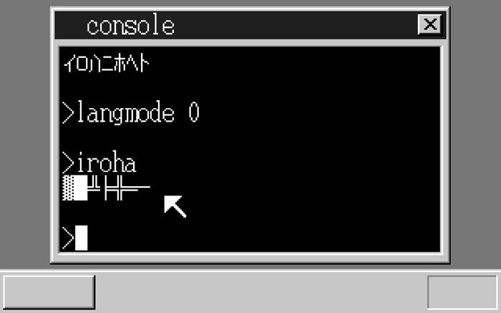 | |
| 成功显示出了半角片假名! | 在英文模式下显示出乱码 |
由于中文不存在像日文半角片假名这样的特殊字符,所以我们不需要考虑这个问题。不过,本节中提到的由于文字编码方式不同导致实际生成的字符编码数据不同的问题,在中文中也是存在的。例如简体中文的GB2312和繁体中文的BIG5就是两种不同的编码方式,相互之间不能兼容。本节中提到的“EUC”实际上是“Extended Unix Code”的缩写,是一种为了让中日韩文字能够兼容ASCII编码而提出的一种兼容编码方式,GB2312(以及后来的GB18030)都属于EUC方式,而Shift-JIS则不属于EUC方式。
