7 日文文字显示(3)(harib25g)
为了解决这个问题,我们先来写一个ipl20.nas替换原来的ipl10.nas,只要将最开头的地方修改一下就好了。
ipl20.nas节选
CYLS EQU 20 ; 要载入多少数据
我们只修改了这一行。哦,当然,要将Makefile中的“ipl10”也替换成“ipl20”哦。
我们再来“make run”一下,输入“type ipl20.nas”。哦,出来了,现在正常了!
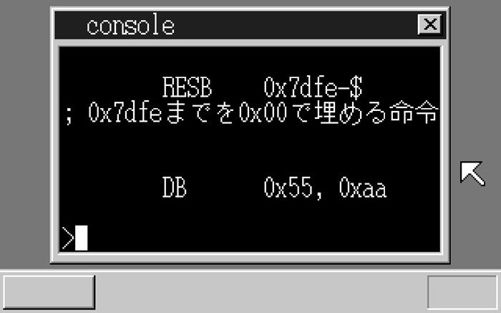
汉字也显示出来了!
好,下面我们来为Linux用户实现对日文EUC的支持吧。咦,已经到这个时间了?算了,不管了,人逢喜事精神爽,要做咱就做到底。
如果不考虑对半角片假名的支持,日文EUC比Shift-JIS要简单。EUC中半角片假名占用2个字节,但却是一个半角字符,字节数与字符宽度不匹配,而我们目前还没有考虑这种情况,所以要支持半角片假名就得做很多改动才行,太麻烦了,这次就算了吧,反正在EUC中也不怎么用半角片假名,应该没什么问题。
日文EUC中k和t的计算公式很简单。
- k = langbyte1 – 0xa1;
- t = *s – 0xa1;
怎么样,简单吧!第1个字节和第2个字节的范围都在0xa1~0xfe,虽然笔者现在已经开始犯困了,不过对付这么简单的问题还不是小菜一碟?看,三下五除二就搞定了。
本次的graphic.c节选
void putfonts8_asc(char *vram, int xsize, int x, int y, char c, unsigned char *s){(中略)if (task->langmode == 0) {(中略)}if (task->langmode == 1) {(中略)}if (task->langmode == 2) { /*从此开始*/for (; *s != 0x00; s++) {if (task->langbyte1 == 0) {if (0x81 <= *s && *s <= 0xfe) {task->langbyte1 = *s;} else {putfont8(vram, xsize, x, y, c, nihongo + *s * 16);}} else {k = task->langbyte1 - 0xa1;t = *s - 0xa1;task->langbyte1 = 0;font = nihongo + 256 * 16 + (k * 94 + t) * 32;putfont8(vram, xsize, x - 8, y, c, font ); /*左半部分*/putfont8(vram, xsize, x , y, c, font + 16); /*右半部分*/}x += 8;}} /*到此结束*/return;}
嗯,话说,putfonts8_asc这个函数名现在看来已经不合适了,因为它不仅支持ASCII,还能支持Shift-JIS和日文EUC。不过给函数改名实在太麻烦了,所以就先这样吧。
另外,langmode命令也需要修改一下,以便可以用它指定模式2,也就是说“langmode 2”代表日文EUC模式。
本次的console.c节选
void cmd_langmode(struct CONSOLE *cons, char *cmdline){struct TASK *task = task_now();unsigned char mode = cmdline[9] - '0';if (mode <= 2) { /*这里!*/task->langmode = mode;} else {cons_putstr0(cons, "mode number error.\n");}cons_newline(cons);return;}
■■■■■
好,我们来“make run”……先等等,在此之前,为了测试日文EUC我们需要一个用EUC编码保存的文本文件。嗯,那我们就先来做一个EUC编码的文本文件吧。
打开二进制编辑器BZ,选择“查看”→“字符编码”→“EUC”,然后在我们平常不怎么注意的,右边写着“0123456789ABCDEF”的地方点击一下,将光标移动过去,输入“日本語EUCで書いてみたよー”(这是用日文EUC写的哦)。虽然这样直接结束也可以,不过我们还是再加一个换行符上去吧。点击左侧区域最后的地方(000010行的+9列),将光标移动过去,然后输入0A。
将这些内容保存为euc.txt。这个文件是用EUC编码保存的,所以如果用Windows自带的记事本程序打开会显示出乱码,不过用Internet Explorer或者Firefox等程序打开的话(前提是选择了正确的字符编码方式)就可以正常显示。

保存为euc.txt的样子
接下来我们修改Makefile,来将euc.txt装入磁盘映像……好,完工了!我们来“make run”吧!
我们先在没有设定langmode的情况下type一下euc.txt看看。嗯,完全看不懂呢(笑)。因为在不设定langmode的情况下默认的语言模式是Shift-JIS。
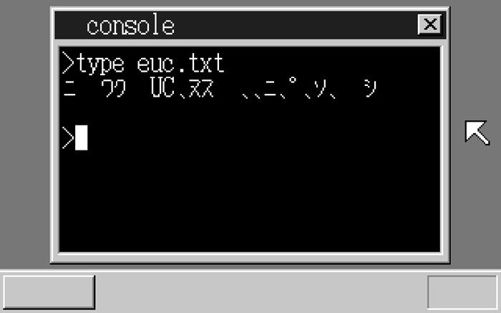
Shift-JIS模式下type的结果
这次我们先来执行“langmode 2”,然后再type试试看……哦哦,正常显示了!撒花!

日文EUC模式下type的结果
如果各位读者当中有人经常使用日文EUC的话,不妨在console_task中将设定语言模式默认值的部分修改一下,默认使用EUC就可以了。
我们前面已经提到过,中文GB2312编码采用的是EUC方式,因此中文字符二进制编码转换为区位码的公式和日文EUC是完全相同的,再加上中文里不需要涉及类似半角片假名的问题,因此通过这一节的内容,就应该可以完美地实现对中文显示的支持了。
要测试中文显示,我们可以用记事本或者其他文本编辑器编写一个包含中文的文本文件,然后用GB2312编码方式保存,再参照本节中的讲解将文本文件装入磁盘映像,用type命令就可以显示出来了。
■■■■■
虽然已经又困又累了,不过我们还剩下一个日文显示方面的问题没有修改,我们需要一个可以查询当前所使用的langmode的API。这个API要怎么用呢?比如可以这样:让画面上的文字提示信息可以在英文模式时显示成英文,在日文模式下显示成日文。
获取langmode
EDX=27
EAX=langmode(由操作系统返回)
我们来修改一下console.c,很简单。
本次的console.c节选
int *hrb_api(int edi, int esi, int ebp, int esp, int ebx, int edx, int ecx, int eax){(中略)} else if (edx == 27) {reg[7] = task->langmode;}return 0;}
我们还得编写apilib(其实不写也可以,但不写的话就无法从C语言调用了)。
api027.nas节选
_api_getlang: ; int api_getlang(void);MOV EDX,27INT 0x40RET
既然我们新增了API,最好还是写一个用来测试的应用程序,否则出了bug就麻烦了。
chklang.c
#include "apilib.h"void HariMain(void){int langmode = api_getlang();static char s1[23] = { /*日本語シフトJISモード(日文Shift-JIS模式)*/0x93, 0xfa, 0x96, 0x7b, 0x8c, 0xea, 0x83, 0x56, 0x83, 0x74, 0x83, 0x67,0x4a, 0x49, 0x53, 0x83, 0x82, 0x81, 0x5b, 0x83, 0x68, 0x0a, 0x00};static char s2[17] = { /*日本語EUCモード(日文EUC模式)*/0xc6, 0xfc, 0xcb, 0xdc, 0xb8, 0xec, 0x45, 0x55, 0x43, 0xa5, 0xe2, 0xa1,0xbc, 0xa5, 0xc9, 0x0a, 0x00};if (langmode == 0) {api_putstr0("English ASCII mode\n");}if (langmode == 1) {api_putstr0(s1);}if (langmode == 2) {api_putstr0(s2);}api_end();}
应该不用特地解释了吧,这里s1和s2没有直接写成字符串是为了在make时避免受到源代码字符编码方式的影响。
好,完工了,“make run”!咦?全角字符的显示有点不对劲啊!
嗯,这是怎么回事?不过移动一下窗口貌似就恢复正常了。
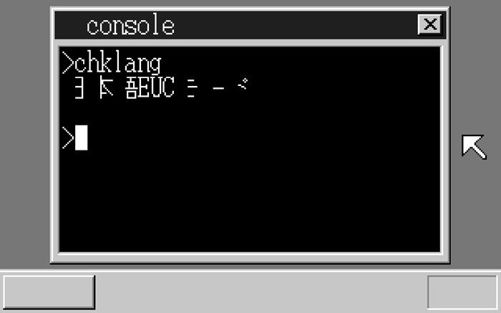 | 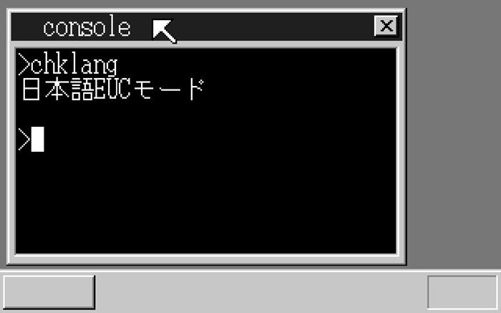 | |
| 只显示出右半部分 | 移动一下窗口就恢复正常了? |
实在是太困了,今天就到此为止吧。本来我们预计今天能完成操作系统核心部分的开发,不过现在遇到了个bug,所以明天还得在操作系统核心的编写上再花点时间。
