6 日文文字显示(2)(harib25f)
好啦,接下来我们该挑战全角字符的显示了。在全角字符显示方面,Shift-JIS和日文EUC的处理方法是不同的,我们先从Shift-JIS开始。
各种半角字符,包括字母、数字、符号、片假名等,加起来总的字符数也不是很多,用1个字节完全可以容纳,不过汉字就不行了,汉字需要使用2个字节来表示(在某些编码方式中,甚至会使用3个甚至更多的字节来表示)。
例如“あ”在Shift-JIS中的编码为0x82、0xa0两个字节。只要用文本编辑器输入一个“あ”并保存,再用二进制编辑器打开就能看到这个编码了(注:在中文系统下,需要用支持选择编码方式的文本编辑器,并选择用Shift-JIS编码保存)。下面我们来讲解一下如何将0x82、0xa0这两个字节的编码转换为区点的编号。
■■■■■
我们先来看第一个字节。如果这个字节为0x81,则代表01区或02区;0x82则代表03区或04区;0x83则代表05区或06区……我们把规则整理成下面这张表,顺便将0x00~0x7f也加进去了。 Shift-JIS的第一个字节
| 0x00 | 控制字符 | (中略) | |
| 0x01 | 控制字符 | 0xdd | 半角片假名(“ン”) |
| 0x02 | 控制字符 | 0xde | 半角片假名(“゚”) |
| (中略) | 0xdf | 半角片假名(“゙”) | |
| 0x1d | 控制字符 | 0xe0 | 全角字符(1面63区~64区) |
| 0x1e | 控制字符 | 0xe1 | 全角字符(1面65区~66区) |
| 0x1f | 控制字符 | 0xe2 | 全角字符(1面67区~68区) |
| 0x20 | 半角字符(空格) | (中略) | |
| 0x21 | 半角字符(“!”) | 0xed | 全角字符(1面89区~90区) |
| 0x22 | 半角字符(“””) | 0xee | 全角字符(1面91区~92区) |
| (中略) | 0xef | 全角字符(1面93区~94区) | |
| 0x7c | 半角字符(“|”) | 0xf0 | 全角字符(2面01区或08区) |
| 0x7d | 半角字符(“}”) | 0xf1 | 全角字符(2面03区~04区) |
| 0x7e | 半角字符(“~”) | 0xf2 | 全角字符(2面05区或12区) |
| 0x7f | 控制字符 | 0xf3 | 全角字符(2面13区~14区) |
| 0x80 | 不使用 | 0xf4 | 全角字符(2面15区或78区) |
| 0x81 | 全角字符(1面01区~02区) | 0xf5 | 全角字符(2面79区~80区) |
| 0x82 | 全角字符(1面03区~04区) | 0xf6 | 全角字符(2面81区~82区) |
| 0x83 | 全角字符(1面05区~06区) | 0xf7 | 全角字符(2面83区~84区) |
| (中略) | (中略) | ||
| 0x9d | 全角字符(1面57区~58区) | 0xfa | 全角字符(2面89区~90区) |
| 0x9e | 全角字符(1面59区~60区) | 0xfb | 全角字符(2面91区~92区) |
| 0x9f | 全角字符(1面61区~62区) | 0xfc | 全角字符(2面93区~94区) |
| 0xa0 | 不使用 | 0xfd | 不使用 |
| 0xa1 | 半角片假名(“。”) | 0xfe | 不使用 |
| 0xa2 | 半角片假名(“「”) | 0xff | 不使用 |
接下来是第二个字节,如下表。 Shift-JIS的第二个字节
| 0x00 | 不使用 | 0x81 | 全角字符(较小的区的65点) |
| 0x01 | 不使用 | 0x82 | 全角字符(较小的区的66点) |
| 0x02 | 不使用 | (中略) | |
| (中略) | 0x9c | 全角字符(较小的区的92点) | |
| 0x3d | 不使用 | 0x9d | 全角字符(较小的区的93点) |
| 0x3e | 不使用 | 0x9e | 全角字符(较小的区的94点) |
| 0x3f | 不使用 | 0x9f | 全角字符(较大的区的01点) |
| 0x40 | 全角字符(较小的区的01点) | 0xa0 | 全角字符(较大的区的02点) |
| 0x41 | 全角字符(较小的区的02点) | 0xa1 | 全角字符(较大的区的03点) |
| 0x42 | 全角字符(较小的区的03点) | (中略) | |
| (中略) | 0xfa | 全角字符(较大的区的92点) | |
| 0x7c | 全角字符(较小的区的61点) | 0xfb | 全角字符(较大的区的93点) |
| 0x7d | 全角字符(较小的区的62点) | 0xfc | 全角字符(较大的区的94点) |
| 0x7e | 全角字符(较小的区的63点) | 0xfd | 不使用 |
| 0x7f | 不使用 | 0xfe | 不使用 |
| 0x80 | 全角字符(较小的区的64点) | 0xff | 不使用 |
参照上面的两张表,我们就可以得到“あ”的编码0x82、0xa0对应04区02点。
知道了区点编号我们就可以计算出字模的内存地址,再显示出来也就很容易了。
■■■■■
我们来修改一下操作系统吧。
本次的graphic.c节选
void putfonts8_asc(char *vram, int xsize, int x, int y, char c, unsigned char *s){extern char hankaku[4096];struct TASK *task = task_now();char *nihongo = (char *) *((int *) 0x0fe8), *font; /*从此开始*/int k, t; /*到此结束*/if (task->langmode == 0) {for (; *s != 0x00; s++) {putfont8(vram, xsize, x, y, c, hankaku + *s * 16);x += 8;}}if (task->langmode == 1) {for (; *s != 0x00; s++) {if (task->langbyte1 == 0) { /*从此开始*/if ((0x81 <= *s && *s <= 0x9f) || (0xe0 <= *s && *s <= 0xfc)) {task->langbyte1 = *s;} else {putfont8(vram, xsize, x, y, c, nihongo + *s * 16);}} else {if (0x81 <= task->langbyte1 && task->langbyte1 <= 0x9f) {k = (task->langbyte1 - 0x81) * 2;} else {k = (task->langbyte1 - 0xe0) * 2 + 62;}if (0x40 <= *s && *s <= 0x7e) {t = *s - 0x40;} else if (0x80 <= *s && *s <= 0x9e) {t = *s - 0x80 + 63;} else {t = *s - 0x9f;k++;}task->langbyte1 = 0;font = nihongo + 256 * 16 + (k * 94 + t) * 32;putfont8(vram, xsize, x - 8, y, c, font ); /*左半部分*/putfont8(vram, xsize, x , y, c, font + 16); /*右半部分*/} /*到此结束*/x += 8;}}return;}
本次的bootpack.h节选
struct TASK {(中略)unsigned char langmode, langbyte1;};
这里的变量k用来存放区号,变量t用来存放点号,为了方便计算,我们存放的是减1之后的值。由于我们没有考虑第2面的字符,因此如果以后要支持第四水准汉字会比较麻烦,不过要支持第二和第三水准汉字还是比较容易的,只要修改载入nihongo.fnt的部分就可以了。
struct TASK中的langbyte1是当接收到全角字符时用来存放第1个字节内容的变量。当接收到半角字符,或者全角字符显示完成之后,该变量被置为0。
putfonts8_asc中每接收到1个字节就会执行x += 8;,当显示全角字符时,需要在接收到第2个字节之后,再往左回移8个像素并绘制字模的左半部分。
采用这种方式时,如果一开始langbyte1不置为0,显示就会出问题,因此我们还需要再修改一下console.c。
本次的console.c节选
void console_task(struct SHEET *sheet, int memtotal){(中略)if (nihongo[4096] != 0xff) { /*是否载入了日文字库?*/task->langmode = 1;} else {task->langmode = 0;}task->langbyte1 = 0; /*这里!*/(中略)}int cmd_app(struct CONSOLE *cons, int *fat, char *cmdline){(中略)if (finfo != 0) {/*找到文件的情况*/(中略)if (finfo->size >= 36 && strncmp(p + 4, "Hari", 4) == 0 && *p == 0x00) {(中略)start_app(0x1b, 0 * 8 + 4, esp, 1 * 8 + 4, &(task->tss.esp0));(中略)timer_cancelall(&task->fifo);memman_free_4k(memman, (int) q, segsiz);task->langbyte1 = 0; /*这里!*/} else {cons_putstr0(cons, ".hrb file format error.\n");}(中略)}(中略)}
对console_task所做的修改只是在决定langmode默认值时顺便将langbyte1置为0而已。
当程序出现bug或者强制结束时可能出现在显示全角字符第1个字节时停止的情况,而对cmd_app所做的修改就是为了应对这种情况。
不过换行还有一点问题,当字符串很长时,可能在全角字符的第1个字节处就遇到自动换行了,这样一来当收到第2个字节时,字模的左半部分就会画到命令行窗口外面去。所以我们在遇到第1个字节换行时,可以特意将cur_x再右移8个像素。
本次的console.c节选
void cons_newline(struct CONSOLE *cons){int x, y;struct SHEET *sheet = cons->sht;struct TASK *task = task_now(); /*这里!*/if (cons->cur_y < 28 + 112) {cons->cur_y += 16; /*到下一行*/} else {/*屏幕滚动*/(中略)}cons->cur_x = 8;if (task->langmode == 1 && task->langbyte1 != 0) { /*从此开始*/cons->cur_x += 8;} /*到此结束*/return;}
完工了,我们来“make run”试试看。虽然没有编写用于测试的应用程序,不过我们可以执行“type ipl10.nas”,如果显示出日文就算成功啦。……出来啦!
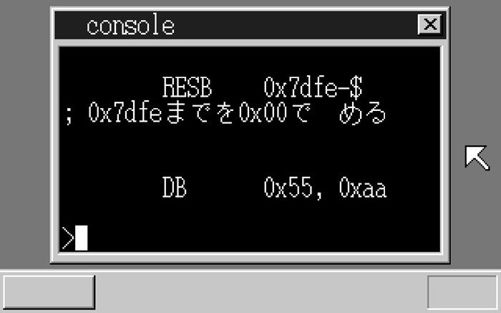
终于显示出日文了哦
不过现在高兴还太早了,仔细看看画面就发现有什么地方不对,为什么“埋”这个汉字没有显示出来呢?k和t的计算应该没有问题啊,嗯……
哦对了,一定是nihongo.fnt文件太大,用ipl10.nas无法全部载入。嗯,一定是这样!
