2 帮助发现bug(harib19b)
CPU的异常处理功能,除了可以保护操作系统免遭应用程序的破坏,还可以帮助我们在编写应用程序时及早发现bug。
我们来举个例子。
本次的bug1.c
void api_putchar(int c);void api_end(void);void HariMain(void){char a[100];a[10] = 'A'; /*这句当然没有问题*/api_putchar(a[10]);a[102] = 'B'; /*这句就有问题了*/api_putchar(a[102]);a[123] = 'C'; /*这句也有问题了*/api_putchar(a[123]);api_end();}
这明显是个有bug的程序,因为a是一个100字节的数组,“A”的赋值显然没有问题,肯定会显示出“A”这个字符,但“B”的赋值就不行,因为它已经超出数组范围了;“C”的赋值当然也是不行的。
把这个程序“make run”一下,结果如下……咦?
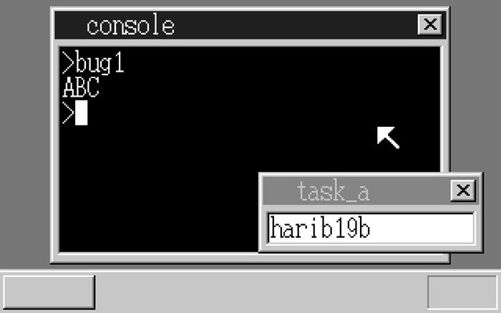
运行成功了
本来我们以为会产生异常,结果却没有出现。我们在真机环境下试试看。
在真机环境下运行了一下,结果电脑自动重启了。嗯,这可不妙啊,电脑自动重启应该是产生了没有设置过的异常所导致的。
哦对了,坏人刚刚擅自加上去的API已经删掉了哦,crack应用程序也已经玩腻了,所以一起都删除了。
■■■■■
由于a这个数组是保存在栈中的,因此这次可能产生了栈异常。我们需要一个函数来处理栈异常,栈异常的中断号为0x0c1。
1 栈异常的中断号为0x0c:可能大家会问,除此之外还有什么异常呢?我们在这里补充讲解一下吧。根据CPU说明书,从0x00到0x1f都是异常所使用的中断,因此,IRQ的中断号都是从0x20之后开始的。其他一些比较有用的异常有0x00号除零异常(当试图除以0时产生)和0x06号非法指令异常(当试图执行CPU无法理解的机器语言指令,例如当试图执行一段数据时,有可能会产生)等。
本次的naskfunc.nas节选
_asm_inthandler0c:STIPUSH ESPUSH DSPUSHADMOV EAX,ESPPUSH EAXMOV AX,SSMOV DS,AXMOV ES,AXCALL _inthandler0cCMP EAX,0JNE end_appPOP EAXPOPADPOP DSPOP ESADD ESP,4 ; 在INT 0x0c中也需要这句IRETD
然后,我们编写inthandler0c函数,只是将inthandler0d中的出错信息改了一下而已。
本次的console.c节选
int *inthandler0c(int *esp){struct CONSOLE *cons = (struct CONSOLE *) *((int *) 0x0fec);struct TASK *task = task_now();cons_putstr0(cons, "\nINT 0C :\n Stack Exception.\n");return &(task->tss.esp0); /*强制结束程序*/}
当然,在IDT中也需要登记一下。
本次的dsctbl.c节选
void init_gdtidt(void){(中略)/* IDT的设置*/set_gatedesc(idt + 0x0c, (int) asm_inthandler0c, 2 * 8, AR_INTGATE32); /*这里!*/set_gatedesc(idt + 0x0d, (int) asm_inthandler0d, 2 * 8, AR_INTGATE32);set_gatedesc(idt + 0x20, (int) asm_inthandler20, 2 * 8, AR_INTGATE32);set_gatedesc(idt + 0x21, (int) asm_inthandler21, 2 * 8, AR_INTGATE32);set_gatedesc(idt + 0x27, (int) asm_inthandler27, 2 * 8, AR_INTGATE32);set_gatedesc(idt + 0x2c, (int) asm_inthandler2c, 2 * 8, AR_INTGATE32);set_gatedesc(idt + 0x40, (int) asm_hrb_api, 2 * 8, AR_INTGATE32 + 0x60);return;}
我们来“make run”一下试试看。啊,果然QEMU对异常的模拟有问题,因此程序还是可以顺利运行的,看来只能在真机环境下测试了。真机环境下成功产生了异常。
在真机环境下,显示出“AB”之后才产生异常,也就是说,写入的“C”被判定为异常,而“B”却被放过去了。从这个例子可以看出,异常并不能发现所有的bug。不过,比起一个bug都发现不了来说,哪怕能发现一个bug也是非常有帮助的,请大家一定要好好利用哦。
可能有人会问,为什么“C”会被判定为异常而“B”就可以被放过去呢?下面我们就来简单讲一讲。
a[102]虽然超出了数组的边界,但却没有超出为应用程序分配的数据段的边界,因此虽然这是个bug,CPU也不会产生异常。另一方面,a[123]所在的地址已经超出了数据段的边界,因此CPU马上就发现并产生了异常。
其实,CPU产生异常的目的并不是去发现bug,而是为了保护操作系统,它的思路是:“这个程序试图访问自身所在数据段以外的内存地址,一定是想擅自改写操作系统或者其他应用程序所管理的内存空间,这种行为岂能放任不管?”因此,即便CPU不能帮我们发现所有的bug,也不可以责怪它哦。
■■■■■
要想让它帮忙发现bug的话,最好是能知道引发异常的指令的地址。这个功能很简单,我们来加上去。
本次的console.c节选
int *inthandler0c(int *esp){struct CONSOLE *cons = (struct CONSOLE *) *((int *) 0x0fec);struct TASK *task = task_now();char s[30]; /*这里!*/cons_putstr0(cons, "\nINT 0C :\n Stack Exception.\n");sprintf(s, "EIP = %08X\n", esp[11]); /*这里!*/cons_putstr0(cons, s); /*这里!*/return &(task->tss.esp0); /*强制结束程序*/}int *inthandler0d(int *esp){struct CONSOLE *cons = (struct CONSOLE *) *((int *) 0x0fec);struct TASK *task = task_now();char s[30]; /*这里!*/cons_putstr0(cons, "\nINT 0D :\n General Protected Exception.\n");sprintf(s, "EIP = %08X\n", esp[11]); /*这里!*/cons_putstr0(cons, s); /*这里!*/return &(task->tss.esp0); /*强制结束程序*/}
上面代码的功能是,将esp(即栈)的11号元素(即EIP)显示出来。
另外,如果想要得到产生异常时其他寄存器的值,只要按照下表显示相应的元素即可。
esp[ 0] : EDI
esp[ 1] : ESI esp[0~7]为_asm_inthandler中PUSHAD的结果
esp[ 2] : EBP
esp[ 4] : EBX
esp[ 5] : EDX
esp[ 6] : ECX
esp[ 7] : EAX
esp[ 8] : DS esp[8~9]为_asm_inthandler中PUSH的结果
esp[ 9] : ES
esp[10] : 错误编号(基本上是0,显示出来也没什么意思)
esp[11] : EIP
esp[12] : CS esp[10~15]为异常产生时CPU自动PUSH的结果
esp[13] : EFLAGS
esp[14] : ESP (应用程序用ESP)
esp[15] : SS (应用程序用SS)
■■■■■
赶紧在真机环境下测试一下,运行bug1.hrb显示“EIP = 00000042”,我们来看看bug1.map的内容:
0x00000024 : _HariMain0x00000052 : _api_putchar
看起来0x42这个地址是位于HariMain中。要查看得更详细的话,可以看一下bug1.lst文件:
11 00000000 _HariMain:
从这一行可以看出,在bug1.lst中,HariMain的地址暂且被当作是0(临时地址),而实际的地址要等到连接之后才能决定,因此nask是不知道的,只好先用.obj文件中的临时地址来生成.lst文件。连接后的HariMain实际地址记载于.map文件中,为0x24。
那么,0x42地址到底位于.lst文件的哪里呢?通过对比.map文件,我们发现.lst文件中的0x1e,就相当于EIP=0x42所指向的地址(因为0x24+0x1e=0x42)。
22 0000001E C6 45 0B 43 MOV BYTE [11+EBP],67
应该就是这里了,这正好就是将a[123]赋值为“C”的指令(“C”为0x43,即67)。
因此,我们可以确定,CPU真的是对这个bug做出了响应。
