4.1 分析可扩展性的历史
在20世纪初期,进行数据分析是一件非常非常困难的事情。如果要进行某些深入分析,例如,建立预测模型,则需要完全依靠人们手工进行各种统计运算。举个例子,为了构建一个线性回归模型,人们不得不手工计算矩阵并进行矩阵的转置运算,连矩阵参数估计的计算也需要手工进行。当时人们已经拥有了一些基础的计算辅助工具,但绝大部分计算过程还是需要依靠手工来完成。在那个时代,获得分析所需的数据是很困难的事情,但是使用这些数据更加困难。那个时代人们几乎没有任何形式的可扩展分析能力。
计算尺的出现让情况稍有好转,20世纪70年代出现的计算器使更大数据量的计算变得更容易了一些,但是那个时候的计算器可以处理的数据规模仍然十分有限。20世纪80年代进入主流市场的计算机,真正地把人们从繁琐的手工计算中彻底解脱了出来。然而,20世纪80年代之前出现的计算机只有极少数人可以接触到,而且这些计算机都极为昂贵,操作也相当困难。
几十年过去了,现在人们处理的数据已经远远超过了手工处理时代的数据规模。随着数据规模的快速增长,计算机处理数据的能力也在不断增强,人们已经不再需要进行手工计算了,但海量数据仍然给计算机与数据存储带来了巨大的挑战。
随着数据处理与分析技术的飞速发展,人们可以处理的数据规模也变得越来越大得“可怕”。十几年前,只有超大型企业或某些预算充足的政府部门才可以处理TB量级的数据。在2000年,只有那些最领先的公司才拥有TB量级的数据库,而今天只需要100美元就可以为你的个人计算机买一个1TB的硬盘。到了2012年,很多小型企业内部数据库的数据规模都超过了1TB,某些领先公司的数据库已经达到了PB量级的规模。仅仅过了十来年,数据规模就至少扩大了1000倍!
此外,随着新的大数据源的出现,数据规模将达到一个新的量级。有些大数据的数据源在仅仅几天或几周,甚至是几个小时内,就可以生成TB或PB量级的数据,数据处理的极限又将面临一次新的挑战。历史上人们驾驭了那些当时看起来很“可怕”的数据,随着时间的推移,这次大数据带来的海量数据也终将被再次驾驭。
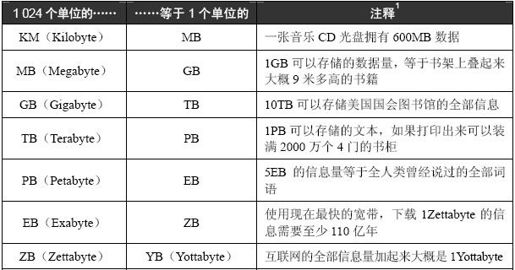
在这个时代,一个刚走进大学的一年级新生,他的计算机可能就拥有好几个PB的数据,他会在一些存储了Exabyte甚至是Zettabyte数据的系统上工作,他们希望这个系统能在几秒或者几分钟内给出计算结果,而不是几小时或几天。表4-1列出了目前人们使用的数据规模计量单位,以及随着数据规模扩大而新出现的计量单位。在历史上,第一个探索并成功突破数据极限的人获得了丰厚的回报,未来也一定会这样。
表4-1 数据规模的衡量单位
1 评论基于这个网站的信息:http://whatsabyte.com。
