7.7 样本VS全体
通常来说,抽取样本进行分析是惯例,关键在于能否获得足够多的样本数据来分析手头这个问题。当有大量数据时,获取足够的样本并不难。今天的系统都具有足够的可扩展性,直接针对全体数据进行分析也是可行的,抽取10%的样本顾客进行分析便不再是必需的,因为我们可以直接分析全体客户。在某些领域,比如临床试验,目前大多还是小样本数据,这一直是个问题,而这些领域是一些特例。然而,大多数情况下,抽样仍然是分析计划的重要组成部分,因此必须确保抽样的正确性。
下次在读报的时候,留意一下报纸里那些不变的调查,你会发现所有调查结果的底部都会声明一定的误差幅度,通常情况下是加减百分之三到五的范围。你也会看到调查所用随机样本的规模,通常情况下是800人~1200人。无论是什么问题和主题,这些误差幅度和样本规模通常都保持不变。要确保一定的误差幅度只需要大约1000个样本。
样本规模越大,误差幅度越小,越能肯定样本的观察结果接近于真实答案。大数据会带来大的样本规模,以至于简单的数据汇总就能够达到很高的统计显著性,剩下的一些误差幅度,已经不会对业务造成什么影响。
可能成百上千的网站都在探索研究多少人点击了A或B链接。也许,某网站发现点击A的人占2.5235%,点击B的人占2.5237%。初看起来好像差异很小,但是如果样本足够大,这0.0002%的区别也具有统计显著性。然而,这个差异还是太小了,虽然具有统计显著性,也没有太多价值。这不符合我们之前讨论过的业务重要程度与相关性准则。就像统计学里的这句谚语,“只有能带来差异的差异,才是真正的差异。”
在过去,分析人员一直强调要获取足够的样本,过小的样本会引起分析师对误差幅度的担忧。当一个样本很小时,误差会变得很大。在这种情况下,很多分析都将没有意义。到了今天,人们有必要确定没有使用过大的样本。虽然样本过大看起来是一个奇怪的概念,但这已经成为一种需要考虑的可能性了。
如果某个业务问题只要求分析20万名随机客户的样本以获得精确的市场需求预测,在这种情况下,只是因为可以做到就对全部2000万名客户进行分析,无疑是对时间和资源的浪费。在这种情况下使用抽样数据进行分析,完全可以发现具有统计显著性、业务重要程度较高且相关的分析结论。在某些情况下,如果必须是1%的差异,业务人员才会采取行动,那么就要确保样本数据足够大,大到1%的差异也具有统计显著性。使用大样本就能保证1%的差异也具有统计显著性,但同时也会带来大量额外的、无意义的数据处理工作。因此,要确保样本足够大又不要过大。驾驭大数据将需要从大量数据中提取精华部分进行分析。
有时候需要分析全部的数据。依据一些标准找到所有数据中的前N个,就是一个这样的常见例子。例如,某项分析需要找到前100个消费最多的顾客。随机取样无法得到想要的数据,它只能随机得到一部分顾客的信息。在这种情况下,拿到全部顾客的数据是必要的。在进行分析之前,就要决定是否需要抽样,样本应该有多大的规模。只要有可能,就应该尽量使用抽样数据。
另一个常见的误解是,一个单一样本可以用来分析不同的问题。市场部门可能只需要10%的顾客来进行分析,因此市场部门只需要从客户群中抽取10%的样本,这个样本数据对于其他部门则未必有效。下面我们来分析原因。
你需要全部的数据!
如果为了不同的问题抽取了不同的样本数据,最终,你会需要100%的数据。不要因为目光短浅而把某个分析主题暂时不需要的数据丢弃。抽样并不是反对收集并存储所有你能获得的数据。企业数据环境不是为了样本数据存在的,相反,样本数据来自于企业数据环境。
对于一家通信公司,10%的客户数据就可以满足客户关系处理(CRM)团队的分析需求,然而,销售部门需要分析不同区域的销售情况,他们需要抽取10%的区域,并获得这些区域100%的交易数据。因此,销售部门和客户关系处理团队的抽样群体是完全不同的。他们可能不会得到全部的客户信息,但是他们能够得到指定店铺的全部信息。同样的,一个产品经理可能需要10%有关商品交易的样本,这个样本可能不会包含全部的关于客户和商铺的交易信息。因此,这3个部门需要不同的样本。
重点是,每个问题都至少需要10%的样本数据,但不同问题的10%的样本数据各不相同。如图7-1所示,不同的样本被用来支持不同的问题,在某些情况下,可能需要100%的数据。因此所有数据都应该是可用的,即使某些数据从来都没有被使用过。
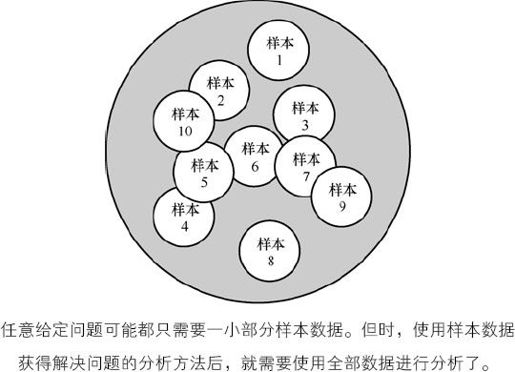
图7-1 不同的样本需要不同的数据
