2.计算复杂度
电子计算机从20世纪50年代开始在社会上发挥重要作用,人们需要某种方法来衡量要解决的不同问题的计算难度。第一批方法的建立源于科学家对人类思考和交流方式的描述。
1943年,心理学家沃伦·麦卡洛克和沃尔特·皮茨建立了一个描述脑活动的模型,名叫神经网(neural net)。20世纪50年代,逻辑学家斯蒂芬·克莱尼建立了图灵机的一个受限版本,叫有限自动机(finite automaton),并研究了能被其解决的问题的属性。有限自动机对于描述简单机器(如卖汽水的机器)的控制逻辑非常有用,但过多的限制使它无法表示更复杂的算法。
20世纪50年代,语言学家诺姆·乔姆斯基试图理解人类如何生成英语或其他语言的句子。他引入了如“上下文无关文法”(context-free grammar)等方法,可生成句子的解析树,如下图所示。
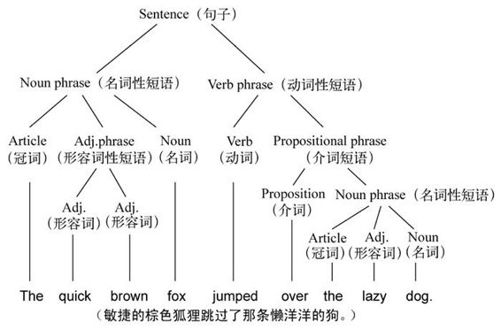
图5-2 解析树
上下文无关文法对人类语言句子的表述有一定合理成分,但不够完整。目前语言学界对哪种语法更适于表述语言——抑或这种语法究竟存在与否还存在争议。
而在描述和解析编程语言及XML等计算机生成的数据文件等方面,上下文无关文法十分好用。尽管如此,它和有限自动机一样,都不能表述我们对高效能计算的直观概念。
人们还引入了很多其他的模型,但这个领域的突破性进展发生在1962年,由纽约州斯克内克塔迪通用电气公司科研实验室的尤里斯·哈特马尼斯和理查德·斯特恩斯取得。他们想出一种绝妙的方式,来表示计算机程序解决问题的能力:看看随着问题描述的规模的扩大,计算机算法所需的运行时间和存储空间发生了多大的变化就可以了。两人在1965年发表的论文《论算法的计算复杂度》(On the Computational Complexity of Algorithms)推动了计算复杂度这个研究领域的诞生。因为这些工作,哈特马尼斯和斯特恩斯获得了1993年的图灵奖。
20世纪60年代,计算复杂度领域出现了两个不同的研究方向。其中一个是研究在给定的时间、存储空间和显式计算模型下,哪些问题能够被解决,而哪些不能。另一个研究方向的带头人是曼纽尔·布卢姆,他在麻省理工学院攻读博士学位期间的工作采取了一种非常抽象的方法,其研究结果不仅不依赖于任何特定的模型,甚至不依赖于特定种类的资源,如时间或存储空间。这两种方法都没有抓住高效能计算的真正本质。
