第 7 章 语音识别
在这一章,我们将介绍以下主题:
读取和绘制音频数据
将音频信号转换为频域
自定义参数生成音频信号
合成音乐
提取频域特征
创建隐马尔科夫模型
创建一个语音识别器
7.1 简介
语音识别是指识别和理解口语的过程。输入音频数据,语音识别器将处理这些数据,从中提取出有用的信息。语音识别有很多实际的应用,例如声音控制设备、将语音转换成单词、安全系统等。
自然中的声音信号多种多样。同一种语言中也有很多不同的语音。语音中有很多不同的元素,例如语言、情绪、语调、噪声、口音等,我们很难定义一组构成语音的规则。尽管语音有这么多变量,人类仍然可以很轻松地理解这些。现在,我们希望机器也能以同样的方式理解语音。
在过去的几十年里,研究者们研究了语音的各个方面,例如识别说话者、理解单词、识别口音、翻译语音等。在所有的这些任务中,自动语音识别成为很多研究者重点关注的方向。在这一章中,我们将学习如何构建一个语音识别器。
7.2 读取和绘制音频数据
本节将介绍如何读取音频文件并将该信号进行可视化展现。这是一个好的开始,可以让我们很好地理解音频信号的基本结构。在开始之前,需要理解音频文件是实际音频信号的数字化形式,实际的音频信号是复杂的连续波形。为了将其保存成数字化形式,需要对音频信号进行采样并将其转换成数字。例如,语音通常以44100 Hz的频率进行采样,这就意味着每秒钟信号被分解成 44 100份,然后这些抽样值被保存。换句话说,每隔1/44100 s都会存储一次值。如果采样率很高,用媒体播放器收听音频时,会感觉到信号是连续的。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npimport matplotlib.pyplot as pltfrom scipy.io import wavfile
(2) 使用wavfile包从input_read.wav中读取音频文件:
# 读取输入文件sampling_freq, audio = wavfile.read('input_read.wav')
(3) 打印这个信号的相关参数:
# 打印参数print '\nShape:', audio.shapeprint 'Datatype:', audio.dtypeprint 'Duration:', round(audio.shape[0] / float(sampling_freq), 3), 'seconds'
(4) 该音频信号被存储在一个16位有符号整型数据中。标准化这些值:
# 标准化数值audio = audio / (2.**15)
(5) 提取前30个值,并将其画出:
# 提取前30个值画图audio = audio[:30]
(6) X轴为时间轴。创建这个轴,并且X轴应该按照采样频率因子进行缩放:
# 建立时间轴x_values = np.arange(0, len(audio), 1) / float(sampling_freq)
(7) 将单位转换为秒:
# 将单位转换为秒x_values *= 1000
(8) 将其画出:
# 画出声音信号图形plt.plot(x_values, audio, color='black')plt.xlabel('Time (ms)')plt.ylabel('Amplitude')plt.title('Audio signal')plt.show()
(9) 全部代码已经包含在read_plot.py文件中。运行该代码,可以看到如图7-1所示的信号。
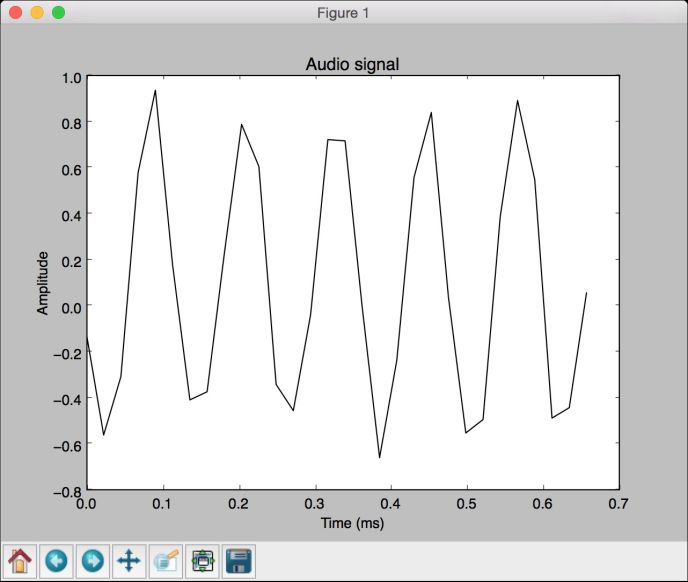
图 7-1
(10) 可以看到终端打印出如图7-2所示的结果。

图 7-2
7.3 将音频信号转换为频域
音频信号是不同频率、幅度和相位的正弦波的复杂混合。正弦波也称作正弦曲线。音频信号的频率内容中隐藏了很多信息。事实上,一个音频信号的性质由其频率内容决定。世界上的语音和音乐都是基于这个事实的。在进行接下来的学习之前,你需要了解一些傅里叶变换(Fourier transforms)的知识,可以在http://www.thefouriertransform.com中找到快速入门介绍。下面来学习如何将音频信号转换为频域。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npfrom scipy.io import wavfileimport matplotlib.pyplot as plt
(2) 读取input_freq.wav音频文件:
# 读取音频文件sampling_freq, audio = wavfile.read('input_freq.wav')
(3) 对信号进行标准化:
# 对信号进行标准化audio = audio / (2.**15)
(4) 音频信号就是一个NumPy数组,因此用以下代码提取其长度:
# 提取数组长度len_audio = len(audio)
(5) 接下来做傅里叶变换。傅里叶变换是关于中心点对称的,因此只需要转换信号的前半部分。我们的最终目标是提取功率信号,因此需要先将信号的值平方:
# 应用傅里叶变换transformed_signal = np.fft.fft(audio)half_length = np.ceil((len_audio + 1) 2.0)transformed_signal = abs(transformed_signal[0:half_length])transformed_signal = float(len_audio)transformed_signal **= 2
(6) 提取信号的长度:
# 提取转换信号的长度len_ts = len(transformed_signal)
(7) 根据信号的长度将信号乘以2:
# 将部分信号乘以2if len_audio % 2:transformed_signal[1:len_ts] = 2else:transformed_signal[1:len_ts-1] = 2
(8) 功率信号用下面的公式获得:
# 获取功率信号power = 10 * np.log10(transformed_signal)
(9) X轴是时间轴。接下来需要根据采样频率对其进行缩放,并将其转换成秒:
# 建立时间轴x_values = np.arange(0, half_length, 1) * (sampling_freq len_ audio) 1000.0
(10) 绘制该信号:
# 画图plt.figure()plt.plot(x_values, power, color='black')plt.xlabel('Freq (in kHz)')plt.ylabel('Power (in dB)')plt.show()
(11) 全部代码已经包含在freq_transform.py文件中。运行该代码,可以看到如图7-3所示的图像。
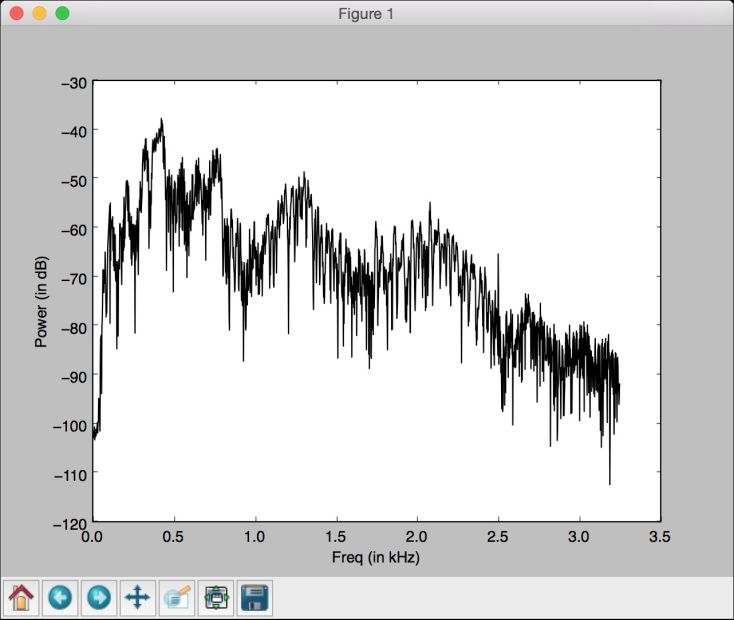
图 7-3
7.4 自定义参数生成音频信号
我们可以用NumPy生成音频信号。前面已经说过,音频信号是一些正弦波的复杂混合,下面用该原理生成自己的音频信号。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npimport matplotlib.pyplot as pltfrom scipy.io.wavfile import write
(2) 定义一个输出文件,用于存储生成的音频:
# 定义存储音频的输出文件output_file = 'output_generated.wav'
(3) 指定音频生成参数。我们希望生成一个3 s长度的信号,采样频率为44100 Hz,音频的频率为587 Hz。时间轴上的值将从-2×pi 到2×pi:
# 指定音频生成的参数duration = 3 # 单位秒sampling_freq = 44100 # 单位Hztone_freq = 587min_val = -2 np.pimax_val = 2 np.pi
(4) 生成时间轴和音频信号。音频信号是一个简单的正弦函数,其相关参数之前已做定义:
# 生成音频信号t = np.linspace(min_val, max_val, duration * sampling_freq)audio = np.sin(2 np.pi tone_freq * t)
(5) 为信号增加一些噪声:
# 增加噪声noise = 0.4 np.random.rand(duration sampling_freq)audio += noise
(6) 将这些值转换为16位整型数,然后将其保存:
# 转换为16位整型数scaling_factor = pow(2,15) - 1audio_normalized = audio / np.max(np.abs(audio))audio_scaled = np.int16(audio_normalized * scaling_factor)
(7) 将信号写入输出文件:
# 写入输出文件write(output_file, sampling_freq, audio_scaled)
(8) 用前100个值画出该信号:
# 提取前100个值audio = audio[:100]
(9) 生成时间轴:
# 生成时间轴x_values = np.arange(0, len(audio), 1) / float(sampling_freq)
(10) 将时间轴的单位转换为秒:
# 将时间轴的单位转换为秒x_values *= 1000
(11) 画出该信号:
# 画出音频信号图plt.plot(x_values, audio, color='black')plt.xlabel('Time (ms)')plt.ylabel('Amplitude')plt.title('Audio signal')plt.show()
(12) 全部代码已经包含在generate.py文件中。运行该代码,可以看到如图7-4所示的图像。
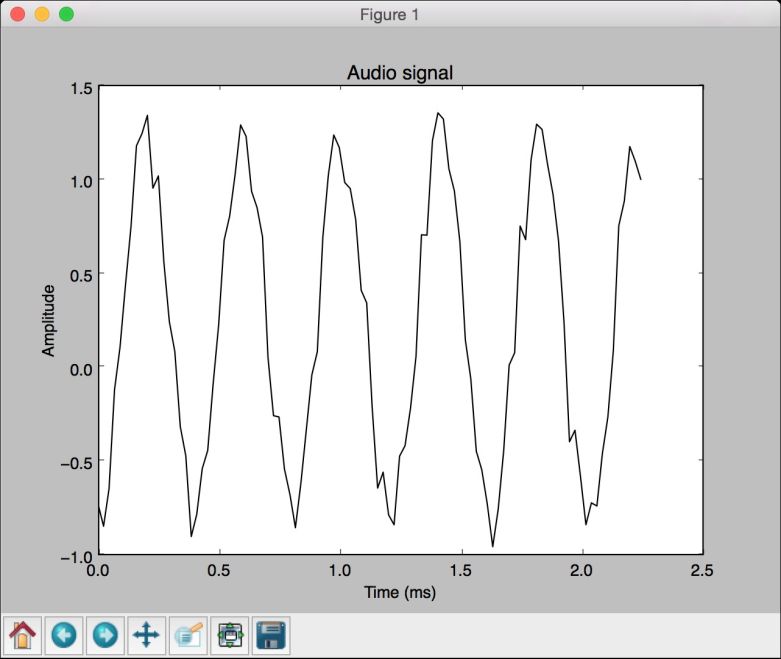
图 7-4
7.5 合成音乐
现在知道了如何生成音频,下面用同样的原理来合成一些音乐。http://www.phy.mtu.edu/~suits/notefreqs.html列举了各种音阶,例如A、G、D 等,以及它们相应的频率。下面将用它合成简单的音乐。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import jsonimport numpy as npfrom scipy.io.wavfile import writeimport matplotlib.pyplot as plt
(2) 定义一个函数,该函数基于输入参数合成音调:
# 定义合成音调def synthesizer(freq, duration, amp=1.0, sampling_freq=44100):
(3) 创建时间轴:
# 创建时间轴t = np.linspace(0, duration, duration * sampling_freq)
(4) 用输入参数构建音频示例,如幅度和频率:
# 构建音频信号audio = amp * np.sin(2 np.pi freq * t)return audio.astype(np.int16)
(5) 定义main函数。我们提供了文件名为tone_freq_map.json的JSON文件,该文件包括一些音阶以及它们的频率:
if __name__=='__main__':tone_map_file = 'tone_freq_map.json'
(6) 加载该文件:
#读取频率映射文件with open(tone_map_file, 'r') as f:tone_freq_map = json.loads(f.read())
(7) 假设想生成2秒的G 调:
# 设置生成G调的输入参数tone input_tone = 'G'duration = 2 # 单位秒amplitude = 10000sampling_freq = 44100 # 单位Hz
(8) 用以下参数调用该函数:
# 生成音阶synthesized_tone = synthesizer(tone_freq_map[input_tone], duration, amplitude, sampling_freq)
(9) 将生成信号写入输出文件:
# 写入输出文件write('output_tone.wav', sampling_freq, synthesized_tone)
(10) 用媒体播放器打开文件并试听,它确实是G 调。下面做一些更有趣的事情。生成一系列的音阶,让其有一些音乐的感觉。定义一个音阶及其持续时间(秒)的序列:
# 音阶及其持续时间tone_seq = [('D', 0.3), ('G', 0.6), ('C', 0.5), ('A', 0.3), ('Asharp', 0.7)]
(11) 迭代该序列并为它们调用合成器函数:
# 构建基于和弦序列的音频信号output = np.array([])for item in tone_seq:input_tone = item[0]duration = item[1]synthesized_tone = synthesizer(tone_freq_map[input_tone], duration, amplitude, sampling_freq)output = np.append(output, synthesized_tone, axis=0)
(12) 将生成信号写入输出文件:
# 写入输出文件write('output_tone_seq.wav', sampling_freq, output)
(13) 全部代码已经包含在synthesize_music.py文件中。用媒体播放器打开output_tone_seq.wav文件并试听,你就可以感受到音乐!
7.6 提取频域特征
前面讨论了如何将信号转换为频域。在多数的现代语音识别系统中,人们都会用到频域特征。将信号转换为频域之后,还需要将其转换成有用的形式。梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)可以解决这个问题。MFCC首先计算信号的功率谱,然后用滤波器组和离散余弦变换的组合来提取特征。如果需要快速入门,可以查看http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs。在进行接下来的学习之前,请确保你已经安装了python_speech_features包,安装指南可以参考http://python-speech-features.readthedocs.org/en/latest。接下来介绍如何提取MFCC特征。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npimport matplotlib.pyplot as pltfrom scipy.io import wavfilefrom features import mfcc, logfbank
(2) 读取input_freq.wav输入文件:
# 读取输入音频文件sampling_freq, audio = wavfile.read("input_freq.wav")
(3) 提取MFCC和过滤器组特征:
# 提取MFCC和过滤器组特征mfcc_features = mfcc(audio, sampling_freq)filterbank_features = logfbank(audio, sampling_freq)
(4) 打印参数,查看可生成多少个窗体:
# 打印参数print '\nMFCC:\nNumber of windows =', mfcc_features.shape[0]print 'Length of each feature =', mfcc_features.shape[1]print '\nFilter bank:\nNumber of windows =', filterbank_features. shape[0]print 'Length of each feature =', filterbank_features.shape[1]
(5) 将MFCC特征可视化。转换矩阵,使得时域是水平的:
# 画出特征图mfcc_features = mfcc_features.Tplt.matshow(mfcc_features)
plt.title('MFCC')
(6) 将滤波器组特征可视化。这里也需要转换矩阵,使得时域是水平的:
filterbank_features = filterbank_features.Tplt.matshow(filterbank_features)plt.title('Filter bank')plt.show()
(7) 全部代码已经包含在extract_freq_features.py文件中。运行该代码,可以得到如图7-5所示的MFCC特征图像。

图 7-5
(8) 滤波器组特征图像如图7-6所示。
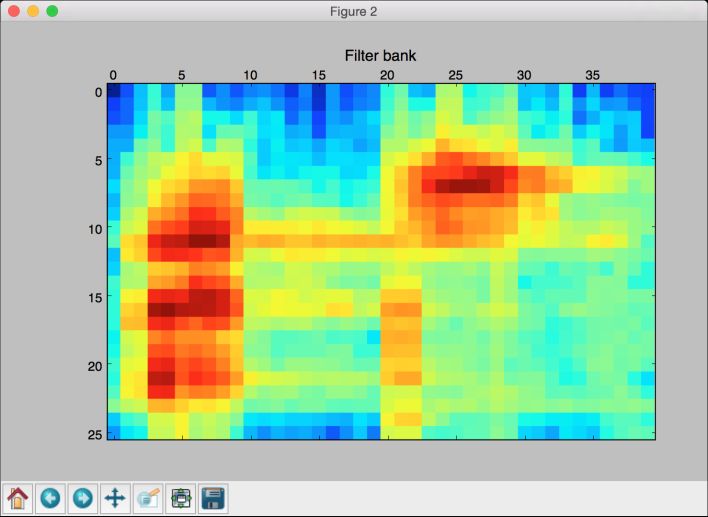
图 7-6
(9) 终端将输出如图7-7所示的结果。

图 7-7
7.7 创建隐马尔科夫模型
接下来可以讨论语音识别了,本例将用到隐马尔科夫模型(Hidden Markov Models,HMMs)来做语音识别。隐马尔科夫模型非常擅长建立时间序列数据模型。因为一个音频信号同时也是一个时间序列信号,因此隐马尔科夫模型也同样适用于音频信号的处理。假定输出是通过隐藏状态生成的,我们的目标是找到这些隐藏状态,以便对信号建模。你可以在https://www.robots.ox.ac.uk/~vgg/rg/slides/hmm.pdf查看更多关于隐马尔科夫模型的介绍。进行接下来的学习之前,请确保你已经安装了hmmlearn包,安装说明可查看http://hmmlearn.readthedocs.org/en/latest。接下来学习如何创建隐马尔科夫模型。
详细步骤
(1) 创建一个Python文件,定义一个类来创建隐马尔科夫模型:
# 创建类处理HMM相关过程class HMMTrainer(object):
(2) 初始化该类。下面将用到高斯隐马尔科夫模型(Gaussian HMMs)来对数据建模。参数n_components定义了隐藏状态的个数,参数cov_type定义了转移矩阵的协方差类型,参数n_iter定义了训练的迭代次数:
def __init__(self, model_name='GaussianHMM', n_components=4, cov_type='diag', n_iter=1000):
这些参数的选定取决于你的需求。只有正确地理解这些参数的含义,才能灵活地进行运用。
(3) 初始化变量:
self.model_name = model_nameself.n_components = n_componentsself.cov_type = cov_typeself.n_iter = n_iterself.models = []
(4) 用以下参数定义模型:
if self.model_name == 'GaussianHMM':self.model = hmm.GaussianHMM(n_components=self.n_components,covariance_type=self.cov_type, n_iter=self.n_iter)else:raise TypeError('Invalid model type')
(5) 输入数据是一个NumPy数组,数组的每个元素都是一个特征向量,每个特征向量都包含k 个维度:
# X是二维数组,其中每一行是13维def train(self, X):np.seterr(all='ignore')self.models.append(self.model.fit(X))
(6) 基于该模型定义一个提取分数的方法:
# 对输入数据运行模型def get_score(self, input_data):return self.model.score(input_data)
(7) 前面创建了一个类来处理隐马尔科夫模型的训练和预测,但是还需要一些数据来观察它的运行情况。下一节将创建一个语音识别器,全部代码包含在speech_recognizer.py文件中。
7.8 创建一个语音识别器
本节需要一个语音文件数据库来创建语音识别器,用到的数据库文件保存在https://code.google.com/archive/p/hmm-speech-recognition/downloads中。其中包含7个不同的单词,并且每个单词都有15个音频文件与之相关。这是一个较小的数据集,但是足够我们理解如何创建一个语音识别器并识别7个不同的单词。我们需要为每一类构建一个隐马尔科夫模型。如果想识别新的输入文件中的单词,需要对该文件运行所有的模型,并找出最佳分数的结果。下面将用到在前一节构建的隐马尔科夫类。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import osimport argparseimport numpy as npfrom scipy.io import wavfilefrom hmmlearn import hmmfrom features import mfcc
(2) 定义一个函数来解析命令行中的输入参数:
# 解析输入参数的函数def build_arg_parser():parser = argparse.ArgumentParser(description='Trains the HMM classifier')parser.add_argument("--input-folder", dest="input_folder", required=True,help="Input folder containing the audio files insubfolders")return parser
(3) 定义main函数,解析输入参数:
if __name__=='__main__':args = build_arg_parser().parse_args()input_folder = args.input_folder
(4) 初始化隐马尔科夫模型的变量:
hmm_models = []
(5) 解析包含所有数据库音频文件的输入路径:
# 解析输入路径for dirname in os.listdir(input_folder):
(6) 提取子文件夹的名称:
# 获取子文件夹名称subfolder = os.path.join(input_folder, dirname)if not os.path.isdir(subfolder):continue
(7) 子文件夹的名称即为该类的标记。用以下方式将其提取出来:
# 提取标记label = subfolder[subfolder.rfind('/') + 1:]
(8) 初始化用于训练的变量:
# 初始化变量X = np.array([])y_words = []
(9) 迭代每一个子文件夹中的音频文件:
# 迭代所有音频文件(分别保留一个进行测试)for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')][:-1]:
(10) 读取每个音频文件:
# 读取每个音频文件filepath = os.path.join(subfolder, filename)sampling_freq, audio = wavfile.read(filepath)
(11) 提取MFCC特征:
# 提取MFCC特征mfcc_features = mfcc(audio, sampling_freq)
(12) 将MFCC特征添加到X变量:
# 将MFCC特征添加到X变量if len(X) == 0:X = mfcc_featureselse:X = np.append(X, mfcc_features, axis=0)
(13) 同时添加标记信息:
# 添加标记y_words.append(label)
(14) 一旦提取完当前类所有文件的特征,就可以训练并保存隐马尔科夫模型了。因为隐马尔科夫模型是一个无监督学习的生成模型,所以并不需要利用标记针对每一类构建隐马尔科夫模型。假定每个类都将构建一个隐马尔科夫模型:
# 训练并保存HMM模型hmm_trainer = HMMTrainer()hmm_trainer.train(X)hmm_models.append((hmm_trainer, label))hmm_trainer = None
(15) 获取一个未被用于训练的测试文件列表:
# 测试文件input_files = ['data/pineapple/pineapple15.wav','data/orange/orange15.wav','data/apple/apple15.wav','data/kiwi/kiwi15.wav']
(16) 解析输入文件:
#为输入数据分类for input_file in input_files:
(17) 读取每个音频文件:
# 读取每个音频文件sampling_freq, audio = wavfile.read(input_file)
(18) 提取MFCC特征:
# 提取MFCC特征mfcc_features = mfcc(audio, sampling_freq)
(19) 定义两个变量,分别用于存放最大分数值和输出标记:
# 定义变量max_score = Noneoutput_label = None
(20) 迭代所有模型,并通过每个模型运行输入文件:
# 迭代HMM模型并选取得分最高的模型for item in hmm_models:hmm_model, label = item
(21) 提取分数,并保存最大分数值:
score = hmm_model.get_score(mfcc_features)if score > max_score:max_score = scoreoutput_label = label
(22) 打印真实的、预测的标记:
# 打印结果print "\nTrue:", input_file[input_file.find('')+1:input_ file.rfind('')]print "Predicted:", output_label
(23) 全部代码已经包含在speech_recognizer.py文件中。运行该代码,可以在终端看到如图7-8所示的显示结果。
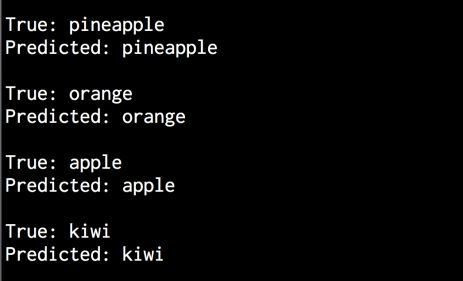
图 7-8
