第 11 章 并发和网络
“时间是大自然防止所有事情同时发生的一种方法。空间是防止所有事情都发生在我身上的方法。”
——关于时间的名言(http://en.wikiquote.org/wiki/Talk:Time)
到目前为止,你写过的大多数程序都是在一个地方(一台机器)一次运行一行(顺序执行)。但是,我们可以在多个地方(分布式计算或者网络)同时做很多事(并发)。这样做有很多好处。
- 性能
你的目标是让高速部件不间断运行,不用等待慢速部件。
- 鲁棒性
数量可以提高安全性,可以同时执行多个相同任务,这样就不用担心出现硬件和软件错误。
- 简化
最佳实践是把复杂任务分解成许多小任务,这样更容易创建、理解和修复。
- 通信
发送数据并接收新数据本身就是一件非常有趣的事。
我们从并发开始,先用第 10 章中提到的非网络技术——进程和线程——构建一个程序。之后会介绍其他方法,比如回调、绿色线程和协程。最后会使用网络技术,仍然是从并发技术开始,逐步扩展到其他方面。
在编写本书时,本章介绍的一些 Python 包还没有兼容 Python 3。大多数情况下的示例代码只能在 Python 2 的解释器中运行,这个解释器我们称之为
python2。
11.1 并发
Python 官网基于标准库(https://docs.python.org/3/library/concurrency.html)介绍了常见的并发技术。页面中提到了很多包和技术,本章会介绍其中最有用的部分。
在计算机中,如果你的程序在等待,通常是因为以下两个原因。
- I/O 限制
这个限制很常见。计算机的 CPU 速度非常快——比计算机内存快几百倍,比硬盘或者网络快几千倍。
- CPU 限制
在处理数字运算任务时,比如科学计算或者图形计算,很容易遇到这个限制。
以下是和并发相关的两个术语。
- 同步
一件事接着一件事发生,就像送葬队伍一样。
- 异步
任务是互相独立的,就像派对参与者从不同的车上下来一样。
当你要用简单的系统和任务来处理现实中的问题时,迟早需要处理并发。假设你有一个网站,必须给用户很快地返回静态和动态网页。一秒是可以接受的,但是如果展示或者交互需要很长时间,用户就会失去耐心。谷歌和亚马逊的测试显示,页面加载速度降低一点就会导致流量大幅下降。
但是,如何处理需要长时间执行的任务呢,比如上传文件、改变图片大小或者查询数据库?显然无法用同步的 Web 客户端代码解决这个问题,因为同步就必然会产生等待。
在一台电脑中,如果你想尽快处理多个任务,就需要让它们互相独立。慢任务不应该阻塞其他任务。
10.3 节介绍了如何用多进程实现单机的并发工作。如果你需要改变图片的大小,Web 服务器代码可以调用一个独立、专用的图片处理进程,可以异步地并发执行。这样可以通过增加处理进程来横向扩展你的应用。
问题的关键是如何让这些进程并发地执行。任何共享控制或者状态管理都会导致瓶颈。另一个更大的问题是如何处理错误,因为并发计算比常规计算更难,更容易出现错误,因此成功的概率更低。
那么到底应该如何处理这些复杂的问题呢?我们来看一种优秀的多任务管理方法:队列。
11.1.1 队列
队列有点像列表:从一头添加事物,从另一头取出事物。这种队列被称为 FIFO(先进先出)。
假设你正在洗盘子,如果需要完成全部工作,需要洗每一个盘子、烘干并放好。你有很多种方法来完成这个任务。或许你会先洗第一个盘子,烘干并把它放好,之后用同样的方法来处理第二个盘子,以此类推。此外,你也可以执行批量操作,先洗完所有的盘子,再烘干所有的盘子,最后把它们都放好。这样做需要你有足够大的水池和烘干机来放置每一步积累的所有盘子。这些都是同步方法——一个工人,一次做一件事。
还有一种方法是再找一个或者两个帮手。如果你是洗盘子的人,可以把洗好的盘子递给烘干盘子的人,他再把烘干的盘子递给放置盘子的人。所有人都在自己的位置工作,这样会比你一个人要快很多。
然而,如果你洗盘子的速度比下一个人烘干的速度快怎么办?要么把湿盘子扔在地上,要么把它们堆在你和下一个人之间,或者一直闲着直到下一个人处理完之前的盘子。如果最后一个人比第二个人还慢,那第二个人要么把盘子扔在地上,要么把它们堆在两个人之间,要么就闲着。你有很多个工人,但总体来说,任务仍然是同步完成的,处理速度和最慢的工人速度是一样的。
俗话说:人多好办事(我总觉得这句话来自阿们宗派,因为它总会让我想到粮仓建筑)。增加工人可以更快地搭建粮仓或者洗盘子,前提是使用队列。
通常来说,队列用来传递消息,消息可以是任意类型的信息。在本例中,我们用队列来管理分布式任务,这种队列也称为工作队列或者任务队列。水池中的每个盘子都会发给一个闲置的洗盘子的人,他会洗盘子并把盘子传给第一个闲置的烘干盘子的人,他会烘干盘子并把盘子传给第一个闲置的放盘子的人。这个过程可以是同步的(工人等着处理盘子,处理完等着把盘子给下一个人),也可以是异步的(盘子堆在两个工人中间)。只要你有足够多的工人并且他们都能认真工作,完成速度会很快。
11.1.2 进程
可以用很多方法来实现队列。对单机来说,标准库中的 multiprocessing 模块(参见 10.3 节)有一个 Queue 函数。接下来模拟一个洗盘子的人和多个烘干进程(不用担心,之后会有人把这些盘子放好),我们使用一个中间队列 dish_queue。把下面的代码保存为 dishes.py:
import multiprocessing as mpdef washer(dishes, output):for dish in dishes:print('Washing', dish, 'dish')output.put(dish)def dryer(input):while True:dish = input.get()print('Drying', dish, 'dish')input.task_done()dish_queue = mp.JoinableQueue()dryer_proc = mp.Process(target=dryer, args=(dish_queue,))dryer_proc.daemon = Truedryer_proc.start()dishes = ['salad', 'bread', 'entree', 'dessert']washer(dishes, dish_queue)dish_queue.join()
运行这个新程序:
$ python dishes.pyWashing salad dishWashing bread dishWashing entree dishWashing dessert dishDrying salad dishDrying bread dishDrying entree dishDrying dessert dish
这个队列看起来很像一个简单的 Python 迭代器,会生成一系列盘子。这段代码实际上会启动几个独立的进程,洗盘子的人和烘干盘子的人会用它们来进行通信。我使用 JoinableQueue 和最后的 join() 方法让洗盘子的人知道,所有的盘子都已经烘干。multiprocessing 模块还有其他类型的队列,更多实例请参考文档(https://docs.python.org/3/library/multiprocessing.html)。
11.1.3 线程
线程运行在进程内部,可以访问进程的所有内容,有点像多重人格。multiprocessing 模块有一个兄弟模块 threading,后者用线程来代替进程(实际上,multiprocessing 是在 threading 之后设计出来的,基于进程来完成各种任务)。我们使用线程来重写一遍上面的进程示例:
import threadingdef do_this(what):whoami(what)def whoami(what):print("Thread %s says: %s" % (threading.current_thread(), what))if __name__ == "__main__":whoami("I'm the main program")for n in range(4):p = threading.Thread(target=do_this,args=("I'm function %s" % n,))p.start()
运行后得到以下输出:
Thread <_MainThread(MainThread, started 140735207346960)> says: I'm the main programThread <Thread(Thread-1, started 4326629376)> says: I'm function 0Thread <Thread(Thread-2, started 4342157312)> says: I'm function 1Thread <Thread(Thread-3, started 4347412480)> says: I'm function 2Thread <Thread(Thread-4, started 4342157312)> says: I'm function 3
可以使用线程来重写上面的盘子示例:
import threading, queueimport timedef washer(dishes, dish_queue):for dish in dishes:print ("Washing", dish)time.sleep(5)dish_queue.put(dish)def dryer(dish_queue):while True:dish = dish_queue.get()print ("Drying", dish)time.sleep(10)dish_queue.task_done()dish_queue = queue.Queue()for n in range(2):dryer_thread = threading.Thread(target=dryer, args=(dish_queue,))dryer_thread.start()dishes = ['salad', 'bread', 'entree', 'desert']washer(dishes, dish_queue)dish_queue.join()
multiprocessing 和 threading 的区别之一就是 threading 没有 terminate() 函数。很难终止一个正在运行的线程,因为这可能会引起代码和时空连续性上的各种问题。
线程可能会很危险。就像 C 和 C++ 这类语言中的手动内存管理一样,线程可能会引起很难寻找和处理的 bug。要使用线程,程序中的所有代码——以及程序使用的所有外部库中的代码——必须是线程安全的。在之前的示例代码中,线程之间没有共享任何全局变量,因此可以在没有副作用的情况下独立运行。
假设你是一个幽灵屋中的超自然现象调查员,幽灵在大厅中漫游,但是它们互相之间并不能感知到对方。此外,幽灵可以在任意时间浏览、添加、删除或者移动房间中的任意物品。
你一边看着令人惊讶的仪表读数,一边穿过整个房间。突然,你发现几秒钟之前刚看过的烛台不见了。
房间中的物品就像程序中的变量,幽灵是进程(房间)中的线程。如果幽灵只会浏览房间中的物品,就没有任何问题。就像线程只会读取常量或者变量中的值,但是不会修改它们。
然而,有些看不见的东西会抓住你的手电筒,往你的脖子上吹冷风,在大理石楼梯上一步一步地走,或者点燃壁炉。真正精明的幽灵甚至会在你看不到的房间中捣乱。
尽管你有很高端的设备,要找出是谁在什么时候做了什么改动仍然非常困难。
如果使用进程来代替线程,那就像有很多个房子但是每个房子里只有一个(活)人。如果你把白兰地放在壁炉前,一个小时后它还会在那儿。或许会蒸发一些,但是位置不变。
没有全局变量时,线程是非常有用并且安全的。通常来说,如果需要等待 I/O 操作完成,那么使用线程可以节省很多时间。在这种情况下,线程不会因为数据打架,因为每个线程使用的是完全独立的变量。
但是线程有时候确实需要修改全局变量。实际上,使用多线程的一个常见目的就是把需要处理的数据进行划分,这就不可避免地需要修改数据。
常见的安全共享数据的方法是让线程在修改变量之前加软件锁,这样在进行修改时其他线程都会等待。这就像在有幽灵的房子中有一个抓幽灵敢死队帮你看门。需要注意的是,千万别忘了解锁。此外,锁可以嵌套,就像你还有另一个抓幽灵敢死队来看同一个房间或者同一个房子。锁的用法非常传统但是要想用对非常困难。
总而言之,对于 Python,建议如下:
使用线程来解决 I/O 限制问题;
使用进程、网络或者事件(下一节会介绍)来处理 CPU 限制问题。
11.1.4 绿色线程和gevent
如你所见,开发者通常会把程序中运行速度慢的部分划分为多个线程或者进程从而加快速度。Apache Web 服务器就是一个典型的例子。
另一种方法是基于事件编程。一个基于事件的程序会运行一个核心事件循环,分配所有任务,然后重复这个循环。nginx Web 服务器就是基于事件的设计,通常来说比 Apache 快。
gevent 就是一个基于事件的很棒的库:你只需要编写普通的代码,gevent 会神奇地把它们转换成协程。协程就像可以互相通信的生成器,它们会记录自己的位置。gevent 可以修改许多 Python 的标准对象,比如 socket,从而使用它自己的机制来代替阻塞。协程无法处理 C 写成的 Python 扩展代码,比如一些数据库驱动程序。
gevent还不能完全兼容 Python 3,因此下面的示例代码使用的是 Python 2 的工具pip2和python2。
可以使用 Python 2 版的 pip 来安装 gevent:
$ pip2 install gevent
下面是 gevent 官网示例代码(http://www.gevent.org/)的一个变体。11.2.7 节会介绍 socket 模块的 gethostbyname() 函数。这个函数是同步的,所以当它在全世界的名称服务器中寻找地址时,你必须等待(可能要好几秒)。但是,你可以使用 gevent 版本的代码来同时查询多个网站的地址。把下面的代码保存为 gevent_test.py:
import geventfrom gevent import sockethosts = ['www.crappytaxidermy.com', 'www.walterpottertaxidermy.com','www.antique-taxidermy.com']jobs = [gevent.spawn(gevent.socket.gethostbyname, host) for host in hosts]gevent.joinall(jobs, timeout=5)for job in jobs:print(job.value)
这段代码中有一个只有一行的 for 循环。每个主机名都会被提交到一个 gethostbyname() 调用中,但是这些调用可以异步执行,因为使用的是 gevent 版本的 gethostbyname()。
使用下面的命令来用 Python 2 运行 gevent_test.py:
$ python2 gevent_test.py66.6.44.474.125.142.12178.136.12.50
gevent.spawn() 会为每个 gevent.socket.gethostbynome(url) 创建一个绿色线程(也叫微线程)。
绿色线程和普通线程的区别是前者不会阻塞。如果遇到会阻塞普通线程的情况,gevent 会把控制权切换到另一个绿色线程。
gevent.joinall() 方法会等待所有的任务完成。最后,我们会输出获得的所有 IP 地址。
除了使用 gevent 版本的 socket 之外,你也可以使用猴子补丁(monkey-patching)函数。这个函数会修改标准模块,比如 socket,直接让它们使用绿色线程而不是调用 gevent 版本。如果想在整个程序中应用 gevent,这种方法非常有用,即使那些你无法直接接触到的代码也会被改变。
在程序的开头,添加下面的代码:
from gevent import monkeymonkey.patch_socket()
这会把程序中所有的普通 socket 都修改成 gevent 版本,即使是标准库也不例外。再提醒一次,这个改动只对 Python 代码有效,对 C 写成的库无效。
另一个函数会给更多的标准库模块打上补丁:
from gevent import monkeymonkey.patch_all()
在程序开头加上这段代码可以让你的程序充分利用 gevent 带来的速度提升。
把下面的程序保存为 gevent_monkey.py:
import geventfrom gevent import monkey; monkey.patch_all()import sockethosts = ['www.crappytaxidermy.com', 'www.walterpottertaxidermy.com','www.antique-taxidermy.com']jobs = [gevent.spawn(socket.gethostbyname, host) for host in hosts]gevent.joinall(jobs, timeout=5)for job in jobs:print(job.value)
再使用 Python 2 运行程序:
$ python2 gevent_monkey.py66.6.44.474.125.192.12178.136.12.50
使用 gevent 还有一个潜在的危险。对于基于事件的系统来说,执行的每段代码都应该尽可能快。尽管不会阻塞,执行复杂任务的代码还是会很慢。
猴子补丁的理念对于很多人来说并不容易接受。但是,很多大型网站(比如 Pinterest)都在使用 gevent,对网站来说有明显的加速作用。就像一瓶外表精美的药丸一样,要用正确的方式使用 gevent。
tornado(http://www.tornadoweb.org/en/stable/)和gunicorn(http://gunicorn.org/)。它们都使用了底层事件处理和高速 Web 服务器。如果你想使用传统的 Web 服务器(比如 Apache)来构建高速网站,这两个框架非常值得一看。
11.1.5 twisted
twisted(http://twistedmatrix.com/trac/)是一个异步事件驱动的网络框架。你可以把函数关联到事件(比如数据接收或者连接关闭)上,当事件发生时这些函数会被调用。这种设计被称为回调(callback),如果你以前用过 JavaScript,那一定不会陌生。如果是第一次见到回调,可能会觉得它有点过时。对于有些开发者来说,基于回调的代码在应用规模变大之后会很难维护。
和 gevent 一样,twisted 还没有兼容 Python 3。本节会使用 Python 2 的安装器和解释器。使用下面的命令来安装 twisted:
$ pip2 install twisted
twisted 很大,支持很多基于 TCP 和 UDP 的互联网协议。出于教学目的,我们会展示一个简单的敲门服务器和客户端,由 twisted 示例(http://twistedmatrix.com/documents/current/core/examples/)修改而来。首先来看服务器,把代码保存到 knock_server.py(注意 Python 2 中 print() 的语法):
from twisted.internet import protocol, reactorclass Knock(protocol.Protocol):def dataReceived(self, data):print 'Client:', dataif data.startswith("Knock knock"):response = "Who's there?"else:response = data + " who?"print 'Server:', responseself.transport.write(response)class KnockFactory(protocol.Factory):def buildProtocol(self, addr):return Knock()reactor.listenTCP(8000, KnockFactory())reactor.run()
现在看看服务器的忠实伙伴,knock_client.py:
from twisted.internet import reactor, protocolclass KnockClient(protocol.Protocol):def connectionMade(self):self.transport.write("Knock knock")def dataReceived(self, data):if data.startswith("Who's there?"):response = "Disappearing client"self.transport.write(response)else:self.transport.loseConnection()reactor.stop()class KnockFactory(protocol.ClientFactory):protocol = KnockClientdef main():f = KnockFactory()reactor.connectTCP("localhost", 8000, f)reactor.run()if __name__ == '__main__':main()
先启动服务器:
$ python2 knock_server.py
然后启动客户端:
$ python2 knock_client.py
服务器和客户端会交换信息,服务器打印以下对话内容:
Client: Knock knockServer: Who's there?Client: Disappearing clientServer: Disappearing client who?
之后,我们的魔术师客户端结束了,只留服务器还在不断等待。
如果想了解更多关于 twisted 的内容,可以试试官方文档中的其他示例。
11.1.6 asyncio
最近,吉多 · 范 · 罗苏姆(还记得他是谁吗?)参与处理 Python 的并发问题。许多包有自己的事件循环,每种事件循环都想成为标准。他该如何调停回调、绿色线程以及其他并发方法呢?经过许多讨论和交流,他发布了异步 IO 支持重新启动:“asyncio”模块(http://legacy.python.org/dev/peps/pep-3156/),代号 Tulip。asyncio 模块在 Python 3.4 中首次出现。目前,它提供了一种通用的事件循环,可以兼容 twisted、gevent 和其他异步方法。目标是提供一种标准、简洁、高性能的异步 API。期待它在未来的 Python 发布版中不断发展。
11.1.7 Redis
我们之前的洗盘子示例代码,无论使用的是进程还是线程,都运行在一台机器上。下面我们使用另一种方法来实现队列,让它可以既支持单机又支持网络。有时候用了进程和线程,单机仍然无法满足需求。本章的目的就是帮助你从一个盒子(单机)过渡到多个并发的盒子。
要运行本章的示例,需要安装 Redis 服务器和它的 Python 模块。安装方法参见 8.5.3 节。第 8 章中,Redis 的角色是数据库,而这里指的是它的并发特性。
可以使用 Redis 列表来快速创建一个队列。Redis 服务器部署在一台机器上;客户端可以部署在同一台机器上也可以部署在不同机器上,通过网络通信。无论是哪种情况,客户端都是通过使用 TCP 和服务器通信,因此它们是网络化的。一个或多个生产者客户端向列表的一端压入消息,一个或多个工人客户端通过阻塞弹出操作从列表中获得需要洗的盘子。如果列表为空,它们就会闲置。如果有一条消息,第一个空闲工人就会去处理。
和之前的基于进程和线程的示例一样,redis_washer.py 会生成一个盘子序列:
import redisconn = redis.Redis()print('Washer is starting')dishes = ['salad', 'bread', 'entree', 'dessert']for dish in dishes:msg = dish.encode('utf-8')conn.rpush('dishes', msg)print('Washed', num)conn.rpush('dishes', 'quit')print('Washer is done')
循环会生成四个包含盘子名称的消息,最后一条消息是“退出”(quit)。程序会把所有消息都添加到 Redis 服务器上的 dishes 列表中,就像添加到 Python 列表一样。
当第一个盘子就绪之后,redis_dryer.py 就开始工作了:
import redisconn = redis.Redis()print('Dryer is starting')while True:msg = conn.blpop('dishes')if not msg:breakval = msg[1].decode('utf-8')if val == 'quit':breakprint('Dried', val)print('Dishes are dried')
这段代码会等待第一个令牌是 dishes 的消息,并打印出烘干的盘子。如果遇到“退出”消息就终止循环。
启动烘干工人,然后启动清洗工人。在命令结尾加上 &,让第一个程序在后台运行;它会一直运行下去,但是不会监听键盘。尽管第二行的输出稍有不同,但是这个技巧在 Linux、OS X 和 Windows 上都有效。在本例中(OS X),第二行输出的是和后台烘干进程相关的信息。接着,我们正常(在前台)启动清洗进程。你可以看到两个进程混在一起的输出:
$ python redis_dryer.py &[2] 81691Dryer is starting$ python redis_washer.pyWasher is startingWashed saladDried saladWashed breadDried breadWashed entreeDried entreeWashed dessertWasher is doneDried dessertDishes are dried[2]+ Done python redis_dryer.py
只要盘子 ID 从清洗进程到达 Redis,我们勤劳的烘干进程就会取出它们。每个盘子 ID 都是一个数字,除了最后的哨兵值,它是字符串 'quit'。当烘干进程读取到盘子 ID quit 就会退出,后台进程的信息会打印到终端(具体内容在不同系统中同样有差别)。你可以使用一个哨兵(或者说一个非法值)在数据流中表示一些特殊的意义——本例的意义是完毕。如果不这样做,需要添加一些编程逻辑,如下所示:
提前设定好盘子的最大值,这也是一种哨兵;
进行特殊的带外(不在数据流中)进程间通信;
一定时间没有新数据就退出。
再进行一些最终的修改:
创建多个
dryer进程;除了等待哨兵,给每个烘干进程添加一个超时时间。
新的 redis_dryer2.py:
def dryer():import redisimport osimport timeconn = redis.Redis()pid = os.getpid()timeout = 20print('Dryer process %s is starting' % pid)while True:msg = conn.blpop('dishes', timeout)if not msg:breakval = msg[1].decode('utf-8')if val == 'quit':breakprint('%s: dried %s' % (pid, val))time.sleep(0.1)print('Dryer process %s is done' % pid)import multiprocessingDRYERS=3for num in range(DRYERS):p = multiprocessing.Process(target=dryer)p.start()
在后台启动烘干进程,接着在前台启动清洗进程:
$ python redis_dryer2.py &Dryer process 44447 is startingDryer process 44448 is startingDryer process 44446 is starting$ python redis_washer.pyWasher is startingWashed salad44447: dried saladWashed bread44448: dried breadWashed entree44446: dried entreeWashed dessertWasher is done44447: dried dessert
一个烘干进程读取 quit ID 并退出:
Dryer process 44448 is done
20 秒后,其他烘干进程的 blpop 调用返回 None,表示超时,所以它们打印出最后一句话并退出:
Dryer process 44447 is doneDryer process 44446 is done
最后一个烘干子进程退出后,主烘干程序退出:
[1]+ Done python redis_dryer2.py
11.1.8 队列之上
加入的功能越多,流水线就越有可能出问题。如果需要给一个宴会洗盘子,工人数量是否足够呢?如果烘干工人喝多了怎么办?如果水槽堵了怎么办?好担心啊!
如何应对这一切呢?幸运的是,有三种技术可供你使用。
- 触发并忘记
只传递内容,并不关心结果,即使没人处理。这就是“把盘子扔地上”方法。
- 请求 - 响应
对于每一个盘子,流水线上的清洗工人需要收到烘干工人的确认,烘干工人需要收到放置工人的确认。
- 背压或者节流
适用于上游工人速度比下游工人快的情况。
在真实系统中,你必须保证工人的速度能够满足需求,否则就会听到盘子摔碎的声音。你可以把新任务添加到一个等待列表中,一些工人进程会从中弹出最后一个消息并把它添加到工作列表中。消息处理完成后会从工作列表中移除并被添加到完成列表。这样就可以知道哪些任务失败或者占用了太长的时间。你可以自己使用 Redis 来完成这些功能,或者使用其他人已经写好并通过测试的系统。以下有一些基于 Python 的队列包添加了这种额外的控制层(有些使用的是 Redis)。
celery(http://www.celeryproject.org/)
这个包非常值得一看。它可以同步或者异步执行分布式任务,使用了我们之前介绍的方法:multiprocessing、gevent 等。
这个包基于 Redis 构建,可以创建任务队列并实现发布 - 订阅(下一节会介绍)。
这是一个处理任务队列的 Python 库,同样基于 Redis。
- Queues(http://queues.io/)
这个网站介绍了队列化软件,其中有些是基于 Python 开发的。
11.2 网络
在讨论并发时,主要讨论的是时间:单机解决方案(进程、线程和绿色线程)。还简单介绍了网络化的解决方案(Redis、ZeroMQ)。现在,我们来单独介绍一下网络化,也就是跨空间的分布式计算。
11.2.1 模式
你可以使用一些基础的模式来搭建网络化应用。
最常见的模式是请求 - 响应,也被称为客户端 - 服务器。这个模式是同步的:用户会一直等待服务器的响应。在本书中,你已经看过了很多“请求 - 响应”的示例。你的 Web 浏览器也是一个客户端,向 Web 服务器发起一个 HTTP 请求并等待响应。
另一种常见的模式是推送或者扇出:你把数据发送到一个进程池中,空闲的工作进程会进行处理。一个典型的例子是有负载均衡的 Web 服务器。
和推送相反的是拉取或者扇入:你从一个或多个源接收数据。一个典型的例子是记录器,它会从多个进程接收文本信息并把它们写入一个日志文件。
还有一个和收音机或者电视广播很像的模式:发布 - 订阅。这个模式中,会有发送数据的发布者。在简单的发布 - 订阅系统中,所有的订阅者都会收到一份副本。更常见的情况是,订阅者只关心特定类型的数据(通常被称为话题),发布者只会发送这些数据。因此,和推送模式不同,可能会有超过一个订阅者收到数据。如果一个话题没有订阅者,相关的数据会被忽略。
11.2.2 发布-订阅模型
发布 - 订阅并不是队列,而是广播。一个或多个进程发布信息,每个订阅进程声明自己感兴趣的消息类型,然后每个消息都会被复制一份发给感兴趣的订阅进程。因此,一个消息可能只被处理一次,也可能多于一次,还可能完全不被处理。每个发布者只负责广播,并不知道谁(如果有人的话)在监听。
1. Redis
你可以使用 Redis 来快速搭建一个发布 - 订阅系统。发布者会发出包含话题和值的消息,订阅者会声明它们对什么话题感兴趣。
下面是发布者,redis_pub.py:
import redisimport randomconn = redis.Redis()cats = ['siamese', 'persian', 'maine coon', 'norwegian forest']hats = ['stovepipe', 'bowler', 'tam-o-shanter', 'fedora']for msg in range(10):cat = random.choice(cats)hat = random.choice(hats)print('Publish: %s wears a %s' % (cat, hat))conn.publish(cat, hat)
每个话题是猫的一个品种,每个消息的值是帽子的一种类型。
下面是一个订阅者,redis_sub.py:
import redisconn = redis.Redis()topics = ['maine coon', 'persian']sub = conn.pubsub()sub.subscribe(topics)for msg in sub.listen():if msg['type'] == 'message':cat = msg['channel']hat = msg['data']print('Subscribe: %s wears a %s' % (cat, hat))
订阅者只会展示猫的品种为 'maine coon' 或者 'persian' 的消息。listen() 方法会返回一个字典,如果它的类型是 'message',那就是由发布者发出的消息。'channel' 键是话题(猫),'data' 键包含消息的值(帽子)。
如果你先启动发布者,这时没有订阅者,就像把一个哑剧演员扔到树林里一样(他会发出声音吗?),因此要先启动订阅者:
$ python redis_sub.py
接着启动发布者,它会发送 10 个消息,然后退出:
$ python redis_pub.pyPublish: maine coon wears a stovepipePublish: norwegian forest wears a stovepipePublish: norwegian forest wears a tam-o-shanterPublish: maine coon wears a bowlerPublish: siamese wears a stovepipePublish: norwegian forest wears a tam-o-shanterPublish: maine coon wears a bowlerPublish: persian wears a bowlerPublish: norwegian forest wears a bowlerPublish: maine coon wears a stovepipe
订阅者只关心两类猫:
$ python redis_sub.pySubscribe: maine coon wears a stovepipeSubscribe: maine coon wears a bowlerSubscribe: maine coon wears a bowlerSubscribe: persian wears a bowlerSubscribe: maine coon wears a stovepipe
我们并没有让订阅者退出,因此它会一直等待消息。如果重新启动一个发布者,那订阅者会继续抓取消息并输出。
可以使用任意数量的订阅者(和发布者)。如果一个消息没有订阅者,那它会从 Redis 服务器中消失。然而,如果有订阅者,消息会停留在服务器中,直到所有的订阅者都获取完毕。
2. ZeroMQ
还记得之前介绍过 ZeroMQ 的 PUB 和 SUB 套接字吗?终于轮到它们大显身手了。ZeroMQ 没有核心服务器,因此每个发布者都会发送给所有订阅者。我们来使用 ZeroMQ 重写一下上面的猫 - 帽子示例。发布者为 zmq_pub.py,内容如下所示:
import zmqimport randomimport timehost = '*'port = 6789ctx = zmq.Context()pub = ctx.socket(zmq.PUB)pub.bind('tcp://%s:%s' % (host, port))cats = ['siamese', 'persian', 'maine coon', 'norwegian forest']hats = ['stovepipe', 'bowler', 'tam-o-shanter', 'fedora']time.sleep(1)for msg in range(10):cat = random.choice(cats)cat_bytes = cat.encode('utf-8')hat = random.choice(hats)hat_bytes = hat.encode('utf-8')print('Publish: %s wears a %s' % (cat, hat))pub.send_multipart([cat_bytes, hat_bytes])
注意代码是如何用 UTF-8 来编码话题和值字符串的。
下面是订阅者 zmq_sub.py:
import zmqhost = '127.0.0.1'port = 6789ctx = zmq.Context()sub = ctx.socket(zmq.SUB)sub.connect('tcp://%s:%s' % (host, port))topics = ['maine coon', 'persian']for topic in topics:sub.setsockopt(zmq.SUBSCRIBE, topic.encode('utf-8'))while True:cat_bytes, hat_bytes = sub.recv_multipart()cat = cat_bytes.decode('utf-8')hat = hat_bytes.decode('utf-8')print('Subscribe: %s wears a %s' % (cat, hat))
在这段代码中,我们订阅了两个不同的比特值:用 UTF-8 编码的 topics 中的两个字符串。
b'',否则什么消息都得不到。
注意,我们在发布者中调用了 send_multipart(),在订阅者中调用了 recv_multipart()。这样就可以收到消息的多个部分并使用第一部分来判断话题是否匹配。也可以选择使用一个字符串或者比特字符串来发送话题和消息值,但是把猫和帽子分开发送会更加清晰。
启动订阅者:
$ python zmq_sub.py
启动发布者,它会立刻发送 10 条消息并退出:
$ python zmq_pub.pyPublish: norwegian forest wears a stovepipePublish: siamese wears a bowlerPublish: persian wears a stovepipePublish: norwegian forest wears a fedoraPublish: maine coon wears a tam-o-shanterPublish: maine coon wears a stovepipePublish: persian wears a stovepipePublish: norwegian forest wears a fedoraPublish: norwegian forest wears a bowlerPublish: maine coon wears a bowler
订阅者打印出它想要的内容:
Subscribe: persian wears a stovepipeSubscribe: maine coon wears a tam-o-shanterSubscribe: maine coon wears a stovepipeSubscribe: persian wears a stovepipeSubscribe: maine coon wears a bowler
3. 其他发布-订阅工具
你可能会对 Python 的其他发布 - 订阅工具感兴趣。
- RabbitMQ
这是一个非常著名的消息发送器。pika 是它的 Python API。详情参见 pika 文档(http://pika.readthedocs.org/)和发布 - 订阅教程(http://www.rabbitmq.com/tutorials/tutorial-three-python.html)。
pypi.python.org
在右上角的搜索框内输入 pubsub 来寻找类似 pypubsub(http://pubsub.sourceforge.net/)这样的 Python 包。
pubsubhubbub
这个读起来非常顺口的协议(https://code.google.com/p/pubsubhubbub/)允许订阅者注册对应发布者的回调函数。
11.2.3 TCP/IP
我们一直处在网络的世界中,理所当然地认为底层的一切都可以正常工作。现在,我们来真正地深入底层,看看那些维持系统运转的东西到底是什么样。
因特网是基于规则的,这些规则定义了如何创建连接、交换数据、终止连接、处理超时等。这些规则被称为协议,它们分布在不同的层中。分层的目的是兼容多种实现方法。你可以在某一层中做任何想做的事,只要遵循上一层和下一层的约定就行。
最底层处理的是电信号,其余层都基于下面的层构建而成。在大约中间的位置是 IP(因特网协议)层,这层规定了网络位置和地址的映射方法以及数据包(块)的传输方式。IP 层的上一层有两个协议描述了如何在两个位置之间移动比特。
- UDP(用户数据报协议)
这个协议被用来进行少量数据交换。一个数据报是一次发送的很少信息,就像明信片上的一个音符一样。
- TCP(传输控制协议)
这个协议被用来进行长时间的连接。它会发送比特流并确保它们都能按序到达并且不会重复。
UDP 信息并不需要确认,因此你永远无法确认它是否到达目的地。如果你想讲一个 UDP 笑话:
Here's a UDP joke. Get it?(这是一个UDP笑话,你笑了吗?)
TCP 会在发送者和接收者之间通过秘密握手建立有保障的连接。下面是一个 TCP 笑话:
Do you want to hear a TCP joke?(你想听一个TCP笑话吗?)Yes, I want to hear a TCP joke.(是的,我想听一个TCP笑话。)Okay, I'll tell you a TCP joke.(好的,我会告诉你一个TCP笑话。)Okay, I'll hear a TCP joke.(好的,我会听到一个TCP笑话。)Okay, I'll send you a TCP joke now.(好的,我现在要发给你一个TCP笑话。)Okay, I'll receive the TCP joke now.(好的,我现在会收到一个TCP笑话。)... (and so on)(下面省略)
你的本地机器 IP 地址一直是 127.0.0.1,名称一直是 localhost。你可能听过它的另一个名字环回接口。如果连接到因特网,那你的机器还会有一个公共 IP。如果使用的是家用计算机,那它一般会接到调制解调器或者路由器上。你甚至可以在同一台机器的两个进程之间使用因特网协议。
在因特网上,我们接触到的大多数事物——Web、数据库服务器,等等——都是基于 IP 协议上的 TCP 协议运行的。简单起见,写为 TCP/IP。下面先来看一些基本的因特网服务,然后会了解一些常用的网络化模式。
11.2.4 套接字
我们一直把这个话题留到现在才讲,是因为即使你不知道所有的底层细节也可以使用高层的因特网。但是,如果你想知道底层的工作原理,那就读读这节吧。
最底层的网络编程使用的是套接字,源于 C 语言和 Unix 操作系统。套接字层的编程是非常繁琐的。使用类似 ZeroMQ 的库会简单很多,但是了解一下底层的工作原理还是非常有用的。举例来说,网络发生错误时出现的错误信息通常是和套接字相关的。
我们来编写一个非常简单的客户端 - 服务器通信示例。客户端发送一个包含字符串的 UDP 数据报给服务器,服务器会返回一个包含字符串的数据包。服务器需要监听特定的地址和端口——就像邮局和邮筒一样。客户端需要知道这两个值才能发送、接收和响应消息。
在下面的客户端和服务器代码中,address 是一个(地址,端口)元组。address 是一个字符串,可以是名称或者 IP 地址。当你的程序和同一台机器上的另一个程序通信时,可以使用名称 'localhost' 或者等价的地址 '127.0.0.1'。
首先从一个进程给另一个进程发送一些数据,让后者返回一些数据。第一个程序是客户端,第二个程序是服务器。在这两个程序中,我们都会打印出时间并打开一个套接字。服务器会监听它套接字上的连接,客户端会向它的套接字写入数据,套接字会发送一个消息给服务器。
下面是第一个程序,udp_server.py:
from datetime import datetimeimport socketserver_address = ('localhost', 6789)max_size = 4096print('Starting the server at', datetime.now())print('Waiting for a client to call.')server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)server.bind(server_address)data, client = server.recvfrom(max_size)print('At', datetime.now(), client, 'said', data)server.sendto(b'Are you talking to me?', client)server.close()
服务器必须用 socket 包中的两个方法来建立网络连接。第一个方法是 socket.socket,它会创建一个套接字。第二个方法 bind 会绑定(监听到达这个 IP 地址和端口的所有数据)到这个套接字上。AF_INET 表示要创建一个因特网(IP)套接字。(还有其他类型的 Unix 域套接字,不过那些只能在本地运行。)SOCK_DGRAM 表示我们要发送和接收数据报,换句话说,我们要使用 UDP。
之后,服务器会等待数据报到达(recvfrom)。收到数据报后,服务器会被唤醒并获取数据和客户端的信息。client 变量包含客户端的地址和端口,用于给客户端发送数据。接着,服务器发送一个响应并关闭连接。
下面,我们来看看 udp_client.py:
import socketfrom datetime import datetimeserver_address = ('localhost', 6789)max_size = 4096print('Starting the client at', datetime.now())client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)client.sendto(b'Hey!', server_address)data, server = client.recvfrom(max_size)print('At', datetime.now(), server, 'said', data)client.close()
客户端的许多方法和服务器一样(除了 bind())。客户端先发送数据,然后接收数据,而服务器恰好相反。
先在一个窗口中启动服务器。它会打印出欢迎信息,然后一直沉默,直到客户端发送数据:
$ python udp_server.pyStarting the server at 2014-02-05 21:17:41.945649Waiting for a client to call.
接着在另一个窗口中启动客户端。它会打印出欢迎信息并向服务器发送数据,打印出响应并退出:
$ python udp_client.pyStarting the client at 2014-02-05 21:24:56.509682At 2014-02-05 21:24:56.518670 ('127.0.0.1', 6789) said b'Are you talking to me?'
最后,服务器会打印类似下面的内容并退出:
At 2014-02-05 21:24:56.518473 ('127.0.0.1', 56267) said b'Hey!'
客户端需要知道服务器的地址和端口号,但是并不需要指定自己的端口号。它的端口号由系统自动分配——在本例中是 56267。
由于 UDP 不可靠,我们准备使用 TCP(传输控制协议)。TCP 用来进行长时间连接,比如 Web。TCP 按照发送的顺序传输数据。如果出现任何问题,它会尝试重新传输。我们尝试一下使用 TCP 在客户端和服务器之间传输一些包。
tcp_client.py 和之前的 UDP 客户端有点像,只向服务器发送一个字符串,但是在调用套接字时有一些区别,如下所示:
import socketfrom datetime import datetimeaddress = ('localhost', 6789)max_size = 1000print('Starting the client at', datetime.now())client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)client.connect(address)client.sendall(b'Hey!')data = client.recv(max_size)print('At', datetime.now(), 'someone replied', data)client.close()
我们把 SOCK_DGRAM 换成了 SOCK_STREAM,指定使用流协议 TCP。还使用 connect() 来建立流。使用 UDP 时不需要这么做,因为每个数据报都是直接暴露在互联网中。
tcp_server.py 和 UDP 版本也有一些区别:
from datetime import datetimeimport socketaddress = ('localhost', 6789)max_size = 1000print('Starting the server at', datetime.now())print('Waiting for a client to call.')server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)server.bind(address)server.listen(5)client, addr = server.accept()data = client.recv(max_size)print('At', datetime.now(), client, 'said', data)client.sendall(b'Are you talking to me?')client.close()server.close()
server.listen(5) 的意思是最多可以和 5 个客户端连接,超过 5 个就会拒绝。server.accept() 接收第一个到达的消息,client.recv(1000) 指定最大的可接收消息长度为 1000 字节。
和之前一样,先启动服务器再启动客户端,然后看看会发生什么。首先是服务器:
$ python tcp_server.pyStarting the server at 2014-02-06 22:45:13.306971Waiting for a client to call.At 2014-02-06 22:45:16.048865 <socket.socket object, fd=6, family=2, type=1,proto=0> said b'Hey!'
接着是客户端。它会给服务器发送消息、接收响应并退出:
$ python tcp_client.pyStarting the client at 2014-02-06 22:45:16.038642At 2014-02-06 22:45:16.049078 someone replied b'Are you talking to me?'
服务器会收集消息、打印出来、发送响应然后退出:
At 2014-02-06 22:45:16.048865 <socket.socket object, fd=6, family=2, type=1,proto=0> said b'Hey!'
可以看到,TCP 服务器使用 client.sendall() 发送响应,之前的 UDP 服务器使用的是 client.sendto()。TCP 会维持多个客户端 - 服务器套接字并保存客户端的 IP 地址。
这看起来并不坏,但是如果你试着编写更复杂的代码,那就会体会到套接字有多难写。下面是一些需要处理的问题。
UDP 可以发送消息,但是消息的大小有限制,而且不能保证消息到达目的地。
TCP 发送字节流,不是消息。你不知道每次调用时系统会发送或者接收多少字节。
如果要用 TCP 传输完整的消息,需要一些额外的信息来把片段拼凑成整个消息:固定的消息大小(字节)、整个消息的大小或者一些特殊的哨兵字符。
由于消息是字节,不是 Unicode 文本字符串,你需要使用 Python 的
bytes类型。更多内容参见第 7 章。
看完这些之后,如果你还对套接字编程感兴趣,可以看看 Python 套接字编程教程(https://docs.python.org/3/howto/sockets.html)。
11.2.5 ZeroMQ
我们已经看过如何用 ZeroMQ 套接字创建发布 - 订阅模型。ZeroMQ 是一个库,有时候也被称为打了激素的套接字(sockets on steroids),ZeroMQ 套接字实现了很多你需要但是普通套接字没有的功能:
传输完整的消息
重连
当发送方和接收方的时间不同步时缓存数据
这个在线教程(http://zguide.zeromq.org/)写得很好,是我见过的最好的讲解网络化模型的教程。印刷版(ZeroMQ: Messaging for Many Applications,Pieter Hintjens 著,O'Reilly 出版社)中的代码风格很好,封面上还有一条大鱼。印刷版中的示例都是用 C 语言写成的,但是在线版可以选择很多种语言,比如 Python 版示例(https://github.com/imatix/zguide/tree/master/examples/Python)。本章会介绍一些 Python 写成的简单的 ZeroMQ 示例。
ZeroMQ 就像乐高积木,我们都知道用很少的乐高积木就能搭建出很多东西。在本例中,你可以用很少几个套接字类型和模式来构建网络。下面这些“乐高积木块”是 ZeroMQ 的套接字类型,看起来很像之前说过的网络模型:
REQ(同步请求)
REP(同步响应)
DEALER(异步请求)
ROUTER(异步响应)
PUB(发布)
SUB(订阅)
PUSH(扇出)
PULL(扇入)
在动手尝试之前,需要先安装 Python 的 ZeroMQ 库:
$ pip install pyzmq
最简单的模式是一个请求 - 响应对。这是同步的:一个套接字发送请求,另一个发送响应。首先是发送响应的代码(服务器),zmq_server.py:
import zmqhost = '127.0.0.1'port = 6789context = zmq.Context()server = context.socket(zmq.REP)server.bind("tcp://%s:%s" % (host, port))while True:# 等待客户端的下一个请求request_bytes = server.recv()request_str = request_bytes.decode('utf-8')print("That voice in my head says: %s" % request_str)reply_str = "Stop saying: %s" % request_strreply_bytes = bytes(reply_str, 'utf-8')server.send(reply_bytes)
创建一个 Context 对象:这是一个能够保存状态的 ZeroMQ 对象。接着创建一个 REP(用于响应)类型的 ZeroMQ 套接字。调用 bind(),让它监听特定的 IP 地址和端口。注意,地址和端口用字符串 'tcp://localhost:6789' 来指定,并不是普通套接字中的元组。
这个示例代码会从一个发送者接收请求并发送响应。消息可以非常长——ZeroMQ 会处理这些细节。
下面是对应的请求代码(客户端),zmq_client.py。它的类型是 REQ(用于请求),而且调用的是 connect(),不是 bind():
import zmqhost = '127.0.0.1'port = 6789context = zmq.Context()client = context.socket(zmq.REQ)client.connect("tcp://%s:%s" % (host, port))for num in range(1, 6):request_str = "message #%s" % numrequest_bytes = request_str.encode('utf-8')client.send(request_bytes)reply_bytes = client.recv()reply_str = reply_bytes.decode('utf-8')print("Sent %s, received %s" % (request_str, reply_str))
现在是时候启动它们了。和普通套接字不同的一点是,你可以用任何顺序启动服务器和客户端。在后台的一个窗口中启动服务器:
$ python zmq_server.py &
然后在同一个窗口中启动客户端:
$ python zmq_client.py
你会看到客户端和服务器交替输出如下所示的内容:
That voice in my head says 'message #1'Sent 'message #1', received 'Stop saying message #1'That voice in my head says 'message #2'Sent 'message #2', received 'Stop saying message #2'That voice in my head says 'message #3'Sent 'message #3', received 'Stop saying message #3'That voice in my head says 'message #4'Sent 'message #4', received 'Stop saying message #4'That voice in my head says 'message #5'Sent 'message #5', received 'Stop saying message #5'
客户端发送完第五条消息之后就退出了,但是我们并没有让服务器退出,所以它一直在等待消息。如果再次运行客户端,它会打印出相同的五行,服务器也会打印出这五行。如果不终止 zmq_server.py 进程并且再次运行它,那 Python 会抱怨说地址已经被使用:
$ python zmq_server.py &[2] 356Traceback (most recent call last):File "zmq_server.py", line 7, in <module>server.bind("tcp://%s:%s" % (host, port))File "socket.pyx", line 444, in zmq.backend.cython.socket.Socket.bind(zmq/backend/cython/socket.c:4076)File "checkrc.pxd", line 21, in zmq.backend.cython.checkrc._check_rc(zmq/backend/cython/socket.c:6032)zmq.error.ZMQError: Address already in use
消息需要用字节字符串形式发送,所以需要把示例中的字符串用 UTF-8 格式编码。你可以发送任意类型的消息,只要把它转换成 bytes 就行。我们的消息是简单的文本字符串,所以 encode() 和 decode() 可以实现文本字符串和字节字符串的转换。如果你的消息包含其他数据类型,可以使用类似 MessagePack(http://msgpack.org/)的库来处理。
由于任何数量的 REQ 客户端都可以 connect() 到一个 REP 服务器,即使是基础的请求 - 响应模式也可以实现一些有趣的通信模式。服务器是同步的,一次只能处理一个请求,但是并不会丢弃这段时间到达的其他请求。ZeroMQ 会在触发某些限制之前一直缓存这些消息,直到它们被处理;这就是 ZeroMQ 中 Q 的意思。Q 表示队列(Queue),M 表示消息(Message),Zero 表示不需要任何消息分发者。
虽然 ZeroMQ 不需要任何核心分发者(中间人),但是如果需要,你可以搭建一个。举例来说,可以使用 DEALER 和 ROUTER 套接字异步连接到多个源和 / 或目标。
多个 REQ 套接字可以连接到一个 ROUTER 上,后者会把请求传递给 DEALER,DEALER 又会传递给和它连接的所有 REP 套接字(图 11-1)。就像很多浏览器连接到一个代理服务器,后者连接到一个 Web 服务器群。你可以根据需要添加任意数量的客户端和服务器。
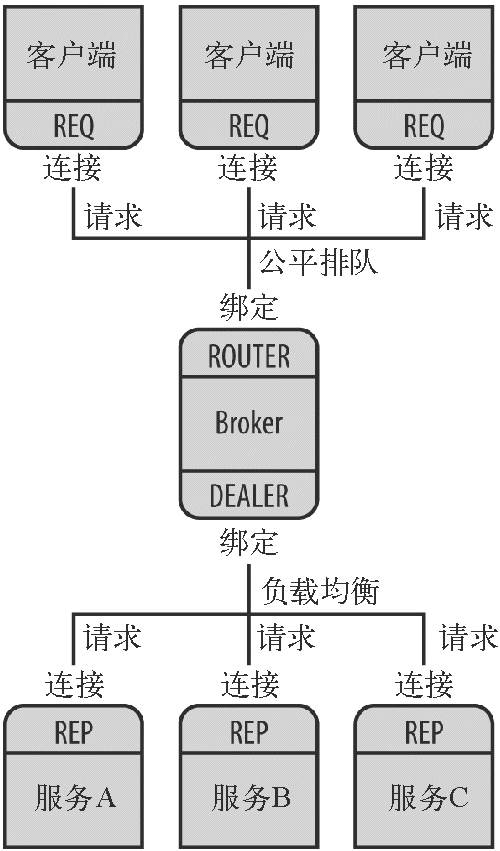
图 11-1:使用一个分发者连接多个客户端和服务器
REQ 套接字只能和 ROUTER 套接字连接;DEALER 可以和后面的多个 REP 套接字连接。ZeroMQ 会处理具体的细节部分,确保请求的负载均衡并把响应发送给正确的目标。
另一种网络化模式被称为通风口,使用 PUSH 套接字来发送异步任务,使用 PULL 套接字来收集结果。
最后一个需要介绍的 ZeroMQ 特性是它可以实现扩展和收缩,只要改变创建的套接字连接类型即可:
tcp适用于单机或者分布式的进程间通信ipc适用于单机的进程间通信inproc适用于单个进程内线程间通信
最后的 inproc 是一种线程间无锁的数据传输方式,可以替代 11.1.3 节中的 threading 示例。
使用 ZeroMQ 之后,你应该再也不会想写原始的套接字代码了。
11.2.6 scapy
有时候你需要深入网络流中处理字节。你可能想要调试 Web API 或者追踪一些安全问题。scapy 库是一个优秀的 Python 数据包分析工具,比编写和调试 C 程序简单很多。实际上,它是一门简单的用来构建和分析数据包的语言。
我本来计划在这里展示一些示例代码,但是由于以下两点原因改变了想法。
scapy还不兼容 Python 3。这个问题之前我们也遇到过,当时是使用pip2和python2来解决,但是……在我看来,
scapy的安装教程(http://www.secdev.org/projects/scapy/portability.html)对 于一本入门级的书来说太复杂了。
如果你愿意,可以看看文档(http://www.secdev.org/projects/scapy/doc/)中的示例代码。这些代码可能会让你有勇气在机器上安装 scapy。
最后,不要把 scapy 和 scrapy 搞混,后者在 9.3.4 节有介绍。
11.2.7 网络服务
Python 有许多网络工具。下面的内容会介绍如何用自动化的方式实现那些最流行的网络服务。官方的完整文档(https://docs.python.org/3/library/internet.html)可以在线查看。
1. 域名系统
计算机有类似 85.2.101.94 的数字 IP 地址,但是相比数字,我们更容易记住名称。域名系统(DNS)是一个非常重要的网络服务,通过一个分布式的数据库实现 IP 地址和名称的转换。当你使用 Web 浏览器并且看到类似“查找主机”的消息时,那可能就是网络连接中断了,第一种可能就是 DNS 错误。
在底层 socket 模块中有一些 DNS 函数。gethostbyname() 会返回一个域名的 IP 地址、扩展版本 gethostbyname_ex() 会返回名称、一个可选名称列表和一个地址列表:
>>> import socket>>> socket.gethostbyname('www.crappytaxidermy.com')'66.6.44.4'>>> socket.gethostbyname_ex('www.crappytaxidermy.com')('crappytaxidermy.com', ['www.crappytaxidermy.com'], ['66.6.44.4'])
getaddrinfo() 方法会查找 IP 地址,不过它返回的信息很全,可以用于创建套接字连接:
>>> socket.getaddrinfo('www.crappytaxidermy.com', 80)[(2, 2, 17, '', ('66.6.44.4', 80)), (2, 1, 6, '', ('66.6.44.4', 80))]
上面的调用会返回两个元组,第一个用于 UDP,第二个用于 TCP(2, 1, 6 中的 6 表示的就是 TCP)。
你可以只获取 TCP 或者 UDP 信息:
>>> socket.getaddrinfo('www.crappytaxidermy.com', 80, socket.AF_INET,socket.SOCK_STREAM)[(2, 1, 6, '', ('66.6.44.4', 80))]
有些 TCP 和 UDP 端口号(http://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers)是 IANA 为特定服务保留的,每个端口号关联一个服务名。举例来说,HTTP 的名称是 http,关联到 TCP 端口 80。
下面的函数可以实现服务名和端口号的转换:
>>> import socket>>> socket.getservbyname('http')80>>> socket.getservbyport(80)'http'
2. Python的Email模块
标准库中有以下这些 Email 模块:
smtplib使用简单邮件传输协议(SMTP)发送邮件;email用来创建和解析邮件;poplib可以使用邮递协议(POP3)来读取邮件;imaplib可以使用因特网消息访问协议(IMAP)来读取邮件。 官方文档包含这些库对应的示例代码(https://docs.python.org/3/library/email-examples.html)。
如果你想编写自己的 Python SMTP 服务器,可以试试 smtpd(https://docs.python.org/3/library/smtpd.html)。
Lamson(http://Lamsonproject.org/)是一个纯 Python 的 SMTP 服务器,可以在数据库中存储邮件,甚至可以过滤垃圾邮件。
3. 其他协议
标准的 ftplib 模块(https://docs.python.org/3/library/ftplib.html)可以使用文件传输协议(FTP)来发送字节。虽然这是一个很古老的协议,但它的表现仍然非常优秀。
本书已经介绍了很多标准库中的模块,不过还是推荐你阅读一下标准库文档中的网络协议(https://docs.python.org/3/library/internet.html)部分。
11.2.8 Web服务和API
信息提供商都有网站,但是这些网站的目标是普通用户,并不是自动化。如果数据只展示在网页上,那想要获取并结构化这些数据的人就必须编写爬虫(参见 9.3.4 节),在页面格式改变时还必须更新爬虫。这是一件很麻烦的事。但是如果一个网站提供数据 API,那对于客户端程序来说,数据的获取就会变得非常直观。相比网页布局,API 很少改变,因此客户端也不需要经常重写。一个快速、整洁的数据通道可以大大简化混搭程序的编写难度——这些程序虽然不具备前瞻性,但是可能非常有用并且能带来利润。
通常来说,最简单的 API 是一个 Web 接口,可以提供类似 JSON 或者 XML 的结构化数据,而不是纯文本或者 HTML。API 既可以做得非常简单也可以是一套成熟的 RESTful API(9.3.2 节有具体定义),后者可以更好地处理那些不安分的字节 1。
1英语“不安分”是 restless,正好和 RESTful 对应。——译者注
在本书的最开始,你就看过一个 Web API:它从 YouTube 上获取最流行的视频。在看过 Web 请求、JSON、字典、元组和切片之后,这个例子应该已经很容易理解了:
import requestsurl = "https://gdata.youtube.com/feeds/api/standardfeeds/top_rated?alt=json"response = requests.get(url)data = response.json()for video in data['feed']['entry'][0:6]:print(video['title']['$t'])
在挖掘知名社交媒体网站,比如 Twitter、Facebook 和 LinkedIn 时,API 非常有用。这些网站都提供可以免费使用的 API,但是它们要求你注册来获得一个 key(一个很长的文本字符串,有时也被称为 token),使用这个 key 来访问 API。网站可以通过 key 来判断是谁在获取数据,也可以用它来限制请求频率。在 YouTube 这个例子中,进行搜索不需要 API key,但是如果要更新 YouTube 上的数据,那就必须使用 key。
下面是一些有趣的服务 API:
Facebook(https://developers.facebook.com/tools/)
Weather Underground(http://www.wunderground.com/weather/api/)
你可以在附录 B 中看到地图 API 示例,附录 C 中还有其他示例。
11.2.9 远程处理
本书中的很多示例都是介绍如何在同一台机器上调用 Python 代码,通常还是在同一个进程中。但是 Python 的能力远不止这些,你可以调用其他机器上的代码,就像它们在本地一样。在高级设置中,如果你用完了单机的空间,可以扩展到其他机器。通过网络连接的一组计算机可以让你操作更多进程和 / 或线程。
1. 远程过程调用
远程过程调用(RPC)看起来和普通的函数一样,但其实运行在通过网络连接的远程机器上。RESTful API 需要通过 URL 编码参数或者请求体来调用,但是 RPC 函数是在你自己的机器上调用。下面是 RPC 客户端的工作原理:
(1) 把你的函数参数转换成比特(有时候被称为编组、序列化或者编码);
(2) 把编码后的字节发送给远程机器。
下面是远程机器的工作原理:
(1) 接收编码后的请求字节;
(2) 接收完毕后,RPC 客户端会把字节解码成原始的数据结构(或者等价的东西,如果两台机器的硬件和软件有差别);
(3) 客户端找到本地目标函数并用解码后的数据调用它;
(4) 客户端编码函数执行结果;
(5) 客户端把编码后的字节发送给调用者。
最后,发起请求的机器把字节解码成返回值。
RPC 是一种非常流行的技术,有很多种实现方式。在服务端,你可以启动一个服务器程序,把它和一些字节传输和编码 / 解码方法连接起来,定义一些访问函数并宣布你的 RPC 开始正常运转。客户端可以连接到服务器并通过 RPC 调用服务器的函数。
标准库中包含一种 RPC 实现,xmlrpc,使用 XML 作为传输格式。你在服务器上定义并注册函数,客户端使用类似导入的方式来调用它们。首先来看文件 xmlrpc_server.py:
from xmlrpc.server import SimpleXMLRPCServerdef double(num):return num * 2server = SimpleXMLRPCServer(("localhost", 6789))server.register_function(double, "double")server.serve_forever()
我们在服务器上提供了 double() 函数,它接收一个数字参数并返回这个数字乘以 2 的结果。服务器在一个地址和端口上启动。我们需要注册函数,这样它才能让客户端通过 RPC 调用。最后,启动服务器并等待。
接着,和你想的一样,xmlrpc_client.py:
import xmlrpc.clientproxy = xmlrpc.client.ServerProxy("http://localhost:6789/")num = 7result = proxy.double(num)print("Double %s is %s" % (num, result))
客户端通过 ServerProxy() 和服务器连接。接着它会调用 proxy.double()。这个函数是哪儿来的?实际上,它是由服务器动态生成的。RPC 机制会截获这个函数名并在远程服务器上调用它。
下面来看一下效果,先启动服务器:
$ python xmlrpc_server.py
接着启动客户端:
$ python xmlrpc_client.pyDouble 7 is 14
服务器会打印出如下内容:
127.0.0.1 - - [13/Feb/2014 20:16:23] "POST HTTP1.1" 200 -
常用的传输方式是 HTTP 和 ZeroMQ。除了 XML 外,JSON、Protocol Buffers 和 MessagePack 也是常用的编码方式。有许多基于 JSON 的 Python RPC 包,但是它们要么不支持 Python 3,要么太难用。这里我们使用 MessagePack 自己的 Python RPC 实现(https://github.com/msgpackrpc/msgpackrpc-python)。下面是安装方法:
$ pip install msgpackrpc-python
这条命令还会安装 tornado,这是一个基于事件的 Python Web 服务器,会被这个库用于传输数据。按照惯例,先是服务器的代码(msgpack_server.py):
from msgpackrpc import Server, Addressclass Services():def double(self, num):return num * 2server = Server(Services())server.listen(Address("localhost", 6789))server.start()
Services 类把它的方法暴露为 RPC 服务。下面是客户端 msgpack_client.py:
from msgpackrpc import Client, Addressclient = Client(Address("localhost", 6789))num = 8result = client.call('double', num)print("Double %s is %s" % (num, result))
依照惯例,先启动服务器再启动客户端:
$ python msgpack_server.py$ python msgpack_client.pyDouble 8 is 16
2. fabric
fabric 包可以运行远程或者本地命令、上传或者下载文件、用 sudo 权限运行命令。这个包使用安全 Shell(SSH:加密文本协议,基本上已经代替了 telnet)来运行远程程序。你需要把(Python)函数写入一个 fabric 文件并声明它们应该在远程还是本地执行。之后,使用时需要用 fabric 程序(名字是 fab,但是并不是向披头士或者洗涤灵致敬)来运行,需要指定目标远程机器和目标函数。它比 RPC 简单很多。
fabric的作者正在合并一些和 Python 3 相关的改动。如果完成修改,那下面的例子可以正常运行。不过,在那之前还是需要使用 Python 2 来运行。
首先,用下面的命令安装 fabric:
$ pip2 install fabric
可以不使用 SSH,直接用 fabric 运行本地 Python 代码。把下面的代码保存为 fab1.py:
def iso():from datetime import dateprint(date.today().isoformat())
接着,输入下面的命令来运行:
$ fab -f fab1.py -H localhost iso[localhost] Executing task 'iso'2014-02-22Done.
-f fab1.py 选项指定使用 fabric 文件 fab1.py,而不是默认的 fabfile.py。-H localhost 选项指定运行本地的命令。最后,iso 是 fab 文件中要运行的函数名。它的工作原理和之前的 RPC 有点像。具体的选项参见官方文档(http://docs.fabfile.org/)。
要在本地或者远程运行外部程序,机器必须运行 SSH 服务器。在 Unix 类系统中,服务器是 sshd;service sshd status 可以检查服务器是否启动,如果需要,可以使用 service sshd start 来启动它。在 Mac 中,打开“系统偏好设置”,点击“共享”,然后勾选“远程登录”。Windows 没有内置的 SSH 支持,建议安装 putty(http://www.chiark.greenend.org.uk/~sgtatham/putty/)。
我们还是使用了函数名 iso,但这次使用 local() 来运行命令。下面是代码和输出:
from fabric.api import localdef iso():local('date -u')$ fab -f fab2.py -H localhost iso[localhost] Executing task 'iso'[localhost] local: date -uSun Feb 23 05:22:33 UTC 2014Done.Disconnecting from localhost... done.
local() 对应的远程方法是 run()。下面是 fab3.py:
from fabric.api import rundef iso():run('date -u')
fabric 在遇到 run() 时会使用 SSH 连接命令行中用 -H 指定的主机。如果你有本地网络并且可以使用 SSH 连接一个主机,那可以在 -H 之后加上那个主机名(就像下面的示例一样)。如果没有这样的主机,那就使用 localhost,fabric 会像访问远程机器一样访问它,这在测试时很有用。本例还是使用 localhost:
$ fab -f fab3.py -H localhost iso[localhost] Executing task 'iso'[localhost] run: date -u[localhost] Login password for 'yourname':[localhost] out: Sun Feb 23 05:26:05 UTC 2014[localhost] out:Done.Disconnecting from localhost... done.
注意,我需要输入密码来登录。如果想省略这一步,可以在 fabric 文件中写入密码:
from fabric.api import runfrom fabric.context_managers import envenv.password = "your password goes here"def iso():run('date -u')
运行它:
$ fab -f fab4.py -H localhost iso[localhost] Executing task 'iso'[localhost] run: date -u[localhost] out: Sun Feb 23 05:31:00 UTC 2014[localhost] out:Done.Disconnecting from localhost... done.
把密码放在代码中非常不安全。更好的方法是使用公钥和密钥配置 SSH,可以使用
ssh-keygen(https://help.github.com/articles/generating-ssh-keys/)。
3. Salt
Salt(http://saltstack.com/)最初的目的是实现远程运行,但是后来变成了一个完整的系统管理平台。它是基于 ZeroMQ 开发的,不是基于 SSH,因此可以扩展到上千台服务器。
Salt 还没有兼容 Python 3,这里我不会提供 Python 2 的示例代码。如果你对它感兴趣,可以阅读文档并等待它兼容 Python 3。
puppet(http://puppetlabs.com/)和chef(http://www.getchef.com/chef/),它们和 Ruby 关系密切。ansible(http://www.ansible.com/home)包是 Python 写成的另一个类似 Salt 的系统,也值得一试。它可以免费下载和使用,但是支持和一些插件包需要商业许可。它默认使用 SSH,并且并不需要在机器上安装其他特殊软件。
salt和ansible都包含了fabric的功能,可以进行初始化配置、部署和远程执行。
11.2.10 大数据和MapReduce
当 Google 和其他互联网公司成长起来之后,它们发现传统的计算机解决方案不能扩展。可以运行在单机或者少量机器上的软件无法支持上千台机器。
存储数据的数据库和文件需要多次寻道,这会产生多次磁头移动。(想想黑胶唱片和它移动唱针的时间,再想想唱针放下时造成的噪音和人们说话的声音。)但是,连续读取磁盘上的区块时速度很快。
开发者发现把数据分布在网络的不同机器上并进行分析会比只用一台机器快很多。它们会使用那些听起来很简单但是效率很高的算法来快速处理分布式数据。其中之一就是 MapReduce,它可以在许多机器上执行计算并收集结果,很像队列。
Google 在论文中发表这个成果之后,Yahoo 发布了一个基于 Java 的开源包,名为 Hadoop(这个名字来源于项目领导者儿子的一个玩具大象)。
这里要说一下大数据这个词。通常来说,它的意思是“数据对于我的机器来说太大了”:数据超出了已有的磁盘、内存、CPU 时间或者所有这些。对于某些组织来说,一旦遇到大数据问题,那解决方案总是 Hadoop。Hadoop 会把数据复制到其他机器上,通过 map 和 reduce 程序来处理它们并把每一步的结果存储到磁盘上。
这个过程可能很慢。更快的方法是 Hadoop 流,就像 Unix 的管道一样,把每一步产生的数据流直接传输给下一步,这样就可以避免存储到磁盘。你可以用任何语言来编写 Hadoop 流程序,包括 Python。
已经有很多关于 Hadoop 的 Python 模块,“Python Hadoop 框架教程”(http://blog.cloudera.com/blog/2013/01/a-guide-topython-frameworks-for-hadoop/)这篇博文介绍了很多。Spotify 公司的流媒体音乐很出名,它开源了自己处理 Hadoop 流的 Python 部件 Luigi(https://github.com/spotify/luigi)。不过现在还不兼容 Python 3。
Hadoop 有一个竞争对手 Spark(http://spark.apache.org/docs/latest/index.html),它的目标是大大加快运行速度。它可以读取和处理所有 Hadoop 的数据结构和格式。Spark 包含 Python 和其他语言的 API,可以参见在线安装文档(http://spark.apache.org/downloads.html)。
另一个类似的产品是 Disco(http://discoproject.org/),它使用 Python 来完成 MapReduce 过程,使用 Erlang 完成通信部分。不过,只可惜无法使用 pip 来安装,具体方法参见文档(http://disco.readthedocs.org/en/latest/start/download.html)。
附录 C 有并行编程相关的示例,可以在分布式集群中执行大规模结构化计算。
11.2.11 在云上工作
不久之前,你还需要买自己的服务器,把它们放在数据中心的机柜上,安装各种软件:操作系统、设备驱动、文件系统、数据库、Web 服务器、邮件服务器、域名服务器、负载均衡、监控程序,等等。当你做过很多遍之后,就会失去新鲜感,并且需要一直担心安全问题。
许多托管服务都提供有偿维护,但是你仍然需要租用物理设备并且按照峰值负载来付费。
机器数量多了之后,就很容易出现问题。你需要横向扩展服务并对数据做冗余存储。网络操作和单机完全不同,Peter Deutsch 说过,分布式计算的八大误解是:
网络是可靠的;
延迟为零;
带宽无限;
网络是安全的;
拓扑结构不会改变;
传输成本为零;
网络是同构的。
你可以试着搭建复杂的分布式系统,但这非常困难,并且需要另一组工具集。借用一个比喻,如果你只有少数几个服务器,你会像对待宠物一样对待它们——给它们命名,了解它们的特点,在需要时尽量治疗它们。但是规模变大之后,你像对待牲口一样对待它们:它们看起来都一样,每个都有编号,如果遇到问题可以被替换掉。
除了自己搭建,你还可以租用云上的服务器。使用这种模式时,维护是其他人的问题,你可以专注在你的服务、博客或者任何你想展示给世界的东西上。使用 Web 仪表盘和 API 可以快速和轻松地创建任何你需要的服务器——它们是有弹性的。你可以监控它们的状态,如果某些参数超过阈值会收到提醒。目前,云是一个非常火的话题,企业在云组件上的支出在不断飙升。
下面我们来看看如何在 Python 中使用现在流行的云平台。
1. Google
Google 内部大量使用 Python,它还招聘了很多高级 Python 开发者(连吉多 · 范 · 罗苏姆都工作过一段时间)。
打开 App Engine 网站(https://developers.google.com/appengine/),在“选择语言”下面点击 Python。你可以在云编辑器中输入 Python 代码,可以直接在下方看到运行结果。在结果后面是链接,可以下载 Python SDK,这样你就可以在自己的硬件上使用 Google 的云 API 进行开发。下面是把应用部署到 AppEngine 的一些细节。
在 Google 云的主页(https://cloud.google.com/)上可以找到服务的详细介绍。
- App Engine
一个高层平台,包含一些 Python 工具,比如 flask 和 django。
- Compute Engine
创建一个虚拟机集群来进行大规模分布式计算。
- Cloud Storage
对象存储(对象是文件,但是没有目录结构)。
- Cloud Datastore
大型 NoSQL 数据库。
- Cloud SQL
大型 SQL 数据库。
- Cloud Endpoints
用 Restful 来访问应用。
- BigQuery
类似 Hadoop 的大数据处理。
如果硬要说,Google 的服务在和 Amazon、OpenStack 竞争。
2. Amazon
当 Amazon 的服务器数量剧增之后,开发者遇到了许多分布式系统带来的问题。大约是 2002 年的某一天,CEO Jeff Bezos 向所有员工宣布,从今往后,Amazon 的所有数据和功能都要通过网络服务接口来使用——再也没有文件、数据库或者本地调用。他们必须把这些接口设计成可以公开使用。最后 Jeff 说:“做不到的人会被解雇。”
不出所料,开发者们开发出一个非常大的面向服务的架构。他们借鉴了很多解决方案,最终完成了 Amazon Web Services(AWS,http://aws.amazon.com/cn/)。这个庞然大物现在已经统治了市场。目前,AWS 包含很多服务。和我们关系最密切的有以下这些服务。
- Elastic Beanstalk
高层应用平台
- EC2(Elastic Compute)
分布式计算
- S3(Simple Storage Service)
对象存储
- RDS
关系数据库(MySQL、PostgreSQL、Oracle、MSSQL)
- DynamoDB
NoSQL 数据库
- Redshift
数据仓库
- EMR
Hadoop
更多关于 AWS 服务的细节,请下载 Amazon Python SDK(http://aws.amazon.com/developers/gettingstarted/python/)并阅读帮助部分。
官方的 Python AWS 库 boto(http://docs.pythonboto.org/en/latest/)是另一个类似的工具,还没有完全兼容 Python 3。你需要使用 Python 2 或者使用其他类似的工具,可以在 Python 包索引(https://pypi.python.org/pypi)中搜索“aws”或者“amazon”。
3. OpenStack
第二个非常流行的云服务是由 Rackspace 提供的。2010 年,Rackspace 和 NASA 达成了不寻常的合作关系,把它们的一些云设施合并成了 OpenStack(http://www.openstack.org/)。这是一个免费的开源平台,可以搭建公有云、私有云和混合云。每 6 个月发布一个新版本,最近的版本有超过 125 万 Python 代码,有很多贡献者。越来越多的组织在产品中使用 OpenStack,包括 CERN 和 PayPal。
OpenStack 的主要 API 是 RESTful 的,它的 Python 模块还提供了程序级别的接口和用于 shell 自动化的命令行 Python 程序。下面是当前发行版中的一些标准访问。
- Keystone
认证服务,提供认证(比如用户名 / 密码)、授权(功能)和服务发现。
- Nova
计算服务,通过网络上的服务器进行分布式工作。
- Swift
对象存储,类似 Amazon 的 S3。它被用于 Rackspace 的 Cloud Files 服务。
- Glance
中层的镜像存储服务。
- Cinder
低层次的块存储服务。
- Horizon
基于 Web 的所有服务的仪表盘。
- Neutron
网络管理服务。
- Heat
配置管理(多个云)服务。
- Ceilometer
遥测(度量、监控)服务。
经常有新服务被提出,有些经过孵化过程后,可能会成为标准 OpenStack 平台的一部分。
OpenStack 运行在 Linux 或者 Linux 虚拟机中。核心服务的安装还是有些复杂。在 Linux 上安装 OpenStack 最快捷的方法就是使用 Devstack(http://docs.openstack.org/developer/devstack/)来一键安装。完成后,你可以使用一个 Web 仪表盘来查看和配置其他服务。
如果想手动安装 OpenStack,可以使用 Linux 的包管理工具。所有的主要 Linux 发行版都支持 OpenStack 并且在下载服务器上提供了官方安装包。可以在 OpenStack 官网上查看安装文档、新闻和相关信息。
OpenStack 的开发和企业支持正在逐步推进,很像当年 Linux 和 Unix 竞争的情景。
11.3 练习
(1) 使用原始的 socket 来实现一个获取当前时间的服务。当客户端向服务器发送字符串 time 时,服务器会返回当前日期和时间的 ISO 格式字符串。
(2) 使用 ZeroMQ 的 REQ 和 REP 套接字实现同样的功能。
(3) 使用 XMLRPC 实现同样的功能。
(4) 你可能看过那部很老的《我爱露西》(I Love Lucy)电视节目。露西和埃塞尔在一个巧克力工厂里工作(这是传统)。他们落在了运输甜点的传送带后面,所以必须用更快的速度进行处理。写一个程序来模拟这个过程,程序会把不同类型的巧克力添加到一个 Redis 列表中,露西是一个客户端,对列表执行阻塞的弹出操作。她需要 0.5 秒来处理一块巧克力。打印出时间和露西处理的每块巧克力类型以及剩余巧克力的数量。
(5) 使用 ZeroMQ 发布第 7 章练习 (7) 中的诗(参见 7.3 节),每次发布一个单词。写一个 ZeroMQ 客户端来打印出每个以元音开头的单词,再写另一个客户端来打印出所有长度为 5 的单词。忽略标点符号。
