第 3 章 用决策树预测获胜球队
本章介绍另一种分类算法——决策树,用它预测NBA篮球赛的获胜球队。比起其他算法,决策树有很多优点,其中最主要的一个优点是决策过程是机器和人都能看懂的,我们使用机器学习到的模型就能完成预测任务。正如我们将在本章讲到的,决策树的另一个优点则是它能处理多种不同类型的特征。
本章主要内容有:
用pandas库加载、处理数据
决策树
随机森林
对真实数据集进行数据挖掘
创建新特征,用强有力的框架对其进行测试
3.1 加载数据集
本章将介绍怎样预测NBA获胜球队。如果你看过NBA,可能知道比赛中两支球队比分咬得很紧,难分胜负,有时最后一分钟才能定输赢,因此预测赢家很难。很多体育赛事都有类似的特点,预期的大赢家也许当天被另一支队伍给打败了。
以往很多对体育赛事预测的研究表明,正确率因体育赛事而异,其上限在70%~80%之间。体育赛事预测多采用数据挖掘或统计学方法。
3.1.1 采集数据
我们将使用NBA 2013—2014赛季的比赛数据。http://Basketball-Reference.com网站提供了NBA及其他赛事的大量资料和统计数据。请按以下方法下载数据。
(1) 在浏览器中打开http://www.basketball-reference.com/leagues/NBA_2014_games.html。
(2) 点击标题Regular Season旁边的Export按钮。
(3) 将文件下载到Data文件夹,记录文件的路径。
数据文件格式为CSV,包含了NBA常规赛季的1230场比赛。
CSV为简单的文本格式文件,每行为一条用逗号分隔的数据(文件格式的名字就是这么来的)。在记事本里输入内容,保存时使用.csv扩展名,也能生成CSV文件。只要能阅读文本文件的编辑器,就能打开CSV文件,也可以用Excel把它作为电子表格打开。
我们用pandas(Python Data Analysis的简写,意为Python数据分析)库加载这些数据,pandas在数据处理方面特别有用。Python内置了读写CSV文件的csv库。但是,考虑到后面创建新特征时还要用到pandas更强大的一些函数,所以我们干脆用pandas加载数据文件。
本章需要安装
pandas。最简单的方法就是用pip3来安装,第1章中安装scikitlearn库时用的就是pip3。pandas的安装方法如下:
$pip3 install pandas安装过程中若遇到任何困难,请访问http://pandas.pydata.org/getpandas.html,根据自己的系统,阅读相关安装指南。
3.1.2 用pandas加载数据集
pandas库是用来加载、管理和处理数据的。它在后台处理数据结构,支持诸计算均值等分析方法。
如果做过大量数据挖掘实验,就会发现自己翻来覆去地编写文件读取、特征抽取等函数。而这些函数每重新实现一次,都可能引入新错误。使用pandas等封装了很多功能的库,能有效减少反复实现上述函数所带来的工作量,并能保证代码的正确性。
本书后面会陆续介绍更多的数据挖掘案例,我们将大量使用pandas。
用read_csv函数就能加载数据集:
import pandas as pddataset = pd.read_csv(data_filename)
上述代码会加载数据集,将其保存到数据框(dataframe)中。数据框提供了一些非常好用的方法,后面会用到。我们来看看数据集是否有问题。输入以下代码,输出数据集的前5行:
dataset.ix[:5]
输出结果如下。
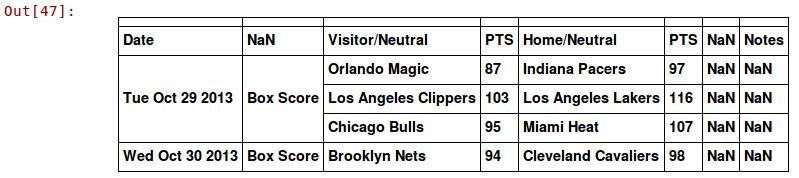
从输出结果来看,这个数据集可以用,但存在几个小问题。下面我们就来修复这些问题。
3.1.3 数据集清洗
从上面的输出结果中,我们发现了以下几个问题。
日期是字符串格式,而不是日期对象。
第一行没有数据。
从视觉上检查结果,发现表头不完整或者不正确。
这些问题来自数据,我们可以改动数据本身,但是这样做的话,容易忘记之前做过哪些操作,落下步骤或是弄错哪一步,因而无法重现之前的结果。我们像前一章用流水线跟踪数据预处理流程那样,用pandas对原始数据进行预处理。
pandas.read_csv函数提供了可用来修复数据的参数,导入文件时指定这几个参数就好。导入后,我们还可以修改文件的头部,如下所示:
dataset = pd.read_csv(data_filename, parse_dates=["Date"],skiprows=[0,])dataset.columns = ["Date", "Score Type", "Visitor Team","VisitorPts", "Home Team", "HomePts", "OT?", "Notes"]
经过这些处理之后,结果会有很大改善,我们再来输出前5行看看:
dataset.ix[:5]
结果如下。
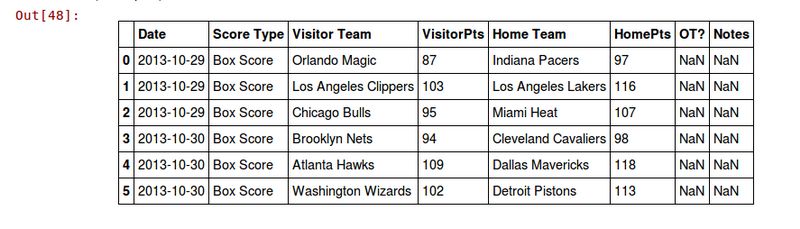
即使原始数据很规整,比如刚使用的这个,我们仍需要对其做些调整。其中一个原因是,文件可能来自不同的系统,由于存在兼容性问题,文件也许会发生变化。
既然数据已经准备好,在开始编写预测算法之前,我们先定下一个正确率作为基准。该基准任何算法都应该能达到。
每场比赛有两个队:主场队和客场队。最直接的方法就是拿几率作为基准,猜中的几率为50%。猜测任意一支球队获胜,都有一半胜算。
3.1.4 提取新特征
我们接下来通过组合和比较现有数据抽取特征。首先,确定类别值。在测试阶段,拿算法得到的分类结果与它对比,就能知道结果是否正确。类别可以有多种表示方法,我们这里用1表示主场队获胜,用0表示客场队获胜。对于篮球比赛而言,得分最多的队伍获胜。虽然数据集没有明确给出各球队的胜负情况,但是稍加计算就能得到。
找出主场获胜的球队:
dataset["HomeWin"] = dataset["VisitorPts"] < dataset["HomePts"]
我们把主场获胜球队的数据保存到NumPy数组里,稍后要用scikitlearn分类器对其进行处理。当前pandas和scikitlearn并没有进行整合,但是借助NumPy数组,它们配合地很好。我们用pandas抽取特征后再用scikitlearn抽取特征具体的值。
y_true = dataset["HomeWin"].values
上面的y_true数组保存的是类别数据,scikitlearn可直接读取该数组。
我们还可以创建一些特征用于数据挖掘。有时候,只要把原始数据丢给分类器就行了,但通常需要先抽取数值型或类别型特征。
首先,创建两个能帮助我们进行预测的特征,分别是这两支队伍上场比赛的胜负情况。赢得上场比赛,大致可以说明该球队水平较高。
遍历每一行数据,记录获胜球队。当到达一行新数据时,分别查看该行数据中的两支球队在各自的上一场比赛中有没有获胜的。
创建(默认)字典,存储球队上次比赛的结果。
from collections import defaultdictwon_last = defaultdict(int)
字典的键为球队,值为是否赢得上一场比赛。遍历所有行,在此过程中,更新每一行,为其增加两个特征值:两支球队在上场比赛有没有获胜。
for index, row in dataset.iterrows():home_team = row["Home Team"]visitor_team = row["Visitor Team"]row["HomeLastWin"] = won_last[home_team]row["VisitorLastWin"] = won_last[visitor_team]dataset.ix[index] = row
请注意,上述代码假定数据集是按照时间顺序排列的。我们所使用的数据集是按这种顺序排列的,如果你的数据集不是这样,你需要把代码中的dataset.iterrows()替换为dataset.sort("Date").iterrows()。
用当前比赛(遍历到的那一行数据所表示的比赛)的结果更新两支球队上场比赛的获胜情况,以便下次再遍历到这两支球队时使用。代码如下:
won_last[home_team] = row["HomeWin"]won_last[visitor_team] = not row["HomeWin"]
上述代码运行结束后,我们多了两个新特征:HomeLastWin和VisitorLastWin。我们再来看下数据集。这次只看前5条意义不大。只有一个球队参加过两场比赛后,我们才知道它在上场比赛表现如何。以下代码将输出本赛季第20~25场比赛:
dataset.ix[20:25]
输出结果如下:
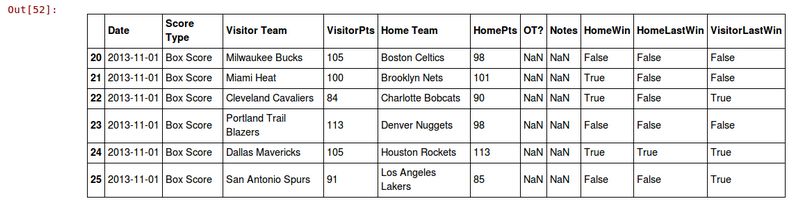
更换上述代码中的索引值,查看其他部分数据。别忘了,一共有1000多场比赛呢!
现在,每个队(包括上个赛季的冠军!)在数据集中第一次出现时,都假定它们在上场比赛中失败。其实可以用上一年的数据弥补缺失的信息,从而改进这个特征,但这里就先做简单处理了。
3.2 决策树
决策树是一种有监督的机器学习算法,它看起来就像是由一系列节点组成的流程图,其中位于上层节点的值决定下一步走向哪个节点。
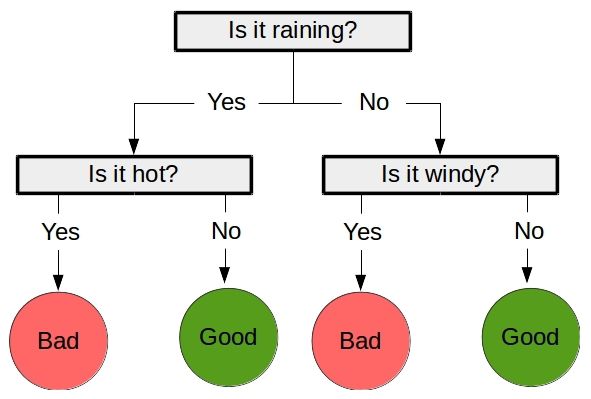
跟大多数分类算法一样,决策树也分为两大步骤。
首先是训练阶段,用训练数据构造一棵树。上一章的近邻算法没有训练阶段,但是决策树需要。从这个意义上说,近邻算法是一种惰性算法,在用它进行分类时,它才开始干活。相反,决策树跟大多数机器学习方法类似,是一种积极学习的算法,在训练阶段完成模型的创建。
其次是预测阶段,用训练好的决策树预测新数据的类别。以上图为例,
["is raining", "very windy"]的预测结果为“Bad”(坏天气)。
创建决策树的算法有多种,大都通过迭代生成一棵树。它们从根节点开始,选取最佳特征,用于第一个决策,到达下一个节点,选择下一个最佳特征,以此类推。当发现无法从增加树的层级中获得更多信息时,算法启动退出机制。
scikitlearn库实现了分类回归树(Classification and Regression Trees,CART)算法并将其作为生成决策树的默认算法,它支持连续型特征和类别型特征。
3.2.1 决策树中的参数
退出准则是决策树的一个重要特性。构建决策树时,最后几步决策仅依赖于少数个体,随意性大。使用特定节点作出推测容易导致过拟合训练数据,而使用退出准则可以防止决策精度过高。
除了设定退出准则外,也可以先创建一棵完整的树,再对其进行修剪,去掉对整个过程没有提供太多信息的节点。这个过程叫作剪枝(pruning)。
scikitlearn库实现的决策树算法给出了退出方法,使用下面这两个选项就可以达到目的。
min_samples_split:指定创建一个新节点至少需要的个体数量。min_samples_leaf:指定为了保留节点,每个节点至少应该包含的个体数量。
第一个参数控制着决策节点的创建,第二个参数决定着决策节点能否被保留。
决策树的另一个参数是创建决策的标准,常用的有以下两个。
基尼不纯度(Gini impurity):用于衡量决策节点错误预测新个体类别的比例。
信息增益(Information gain):用信息论中的熵来表示决策节点提供多少新信息。
3.2.2 使用决策树
从scikit-learn库中导入DecisionTreeClassifier类,用它创建决策树。
from sklearn.tree import DecisionTreeClassifierclf = DecisionTreeClassifier(random_state=14)
我们再次设定
random_state的值为14。本书中凡是用到random_state的地方,我们都用该值。使用相同的随机种子(random seed),能够保证几次实验结果相同。然而,在以后自己的实验中,为保证算法的性能不是与特定的随机状态值相关,在前后几次实验中,需使用不同的随机状态。
现在我们从pandas数据框中抽取数据,以便用scikitlearn分类器处理。指定需要的列,使用数据框的values属性,就能获取到每支球队的上一场比赛结果。
X_previouswins = dataset[["HomeLastWin", "VisitorLastWin"]].values
跟第2章的近邻算法类似,决策树也是一种估计器,因此它同样有fit和predict方法。我们仍然可以用cross_val_score方法来求得交叉检验的平均正确率:
scores = cross_val_score(clf, X_previouswins, y_true,scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
正确率为56.1%,比起随机预测来要更准确!我们应该可以做得更好。从数据集中构建有效特征(Feature Engineering,特征工程)是数据挖掘的难点所在,好的特征直接关系到结果的正确率——甚至比选择合适的算法更重要!
3.3 NBA比赛结果预测
尝试使用不同的特征,我们应该能做得更好。cross_val_score方法可用来测试模型的正确率。有了它,我们就可以尝试其他特征的分类效果。
好多潜在特征都可以拿来用。就我们这个挖掘任务而言,具体怎么选择特征呢?我们尝试问自己以下两个问题。
一般而言,什么样的球队水平更高?
两支球队上一次相遇时,谁是赢家?
我们还将加入新球队的数据,以检测算法是否能得到一个用来判断不同球队比赛情况的模型。
组装起来
对于上面第一个特征,我们创建一个叫作“主场队是否通常比对手水平高”的特征,并使用2013赛季的战绩作为特征取值来源。如果一支球队在2013赛季排名在对手前面,我们就认为它的水平更高。
战绩数据下载方法如下。
(1) 在浏览器中打开http://www.basketball-reference.com/leagues/NBA_2013_standings.html。
(2) 找到Expanded Standings部分,该部分包括所有球队的数据。
(3) 点击Export链接。
(4) 将数据保存到数据文件夹中。
回到IPython Notebook笔记本文件,在新格子里输入以下代码。请注意将战绩文件保存到data_folder变量指定的目录下。
standings_filename = os.path.join(data_folder,"leagues_NBA_2013_standings_expanded-standings.csv")standings = pd.read_csv(standings_filename, skiprows=[0,1])
在笔记本新格子里输入standings并运行,查看战绩。
standings
输出如下。
接下来,创建一个新特征,创建过程与上个特征类似。遍历每一行,查找主场队和客场队两支球队的战绩。代码如下:
dataset["HomeTeamRanksHigher"] = 0for index, row in dataset.iterrows():home_team = row["Home Team"]visitor_team = row["Visitor Team"]
有些球队2014赛季改名了,名字不同但其实还是同一支球队。类似情况在整合不同的数据集时经常遇到!所以在查找球队时,需要把它换成原来的名字,以确保正确找到该球队先前的排名。
if home_team == "New Orleans Pelicans":home_team = "New Orleans Hornets"elif visitor_team == "New Orleans Pelicans":visitor_team = "New Orleans Hornets"
现在就能得到两支球队的排名,比较它们的排名,更新特征值。
home_rank = standings[standings["Team"] ==home_team]["Rk"].values[0]visitor_rank = standings[standings["Team"] ==visitor_team]["Rk"].values[0]row["HomeTeamRanksHigher"] = int(home_rank > visitor_rank)dataset.ix[index] = row
接下来,用cross_val_score函数测试结果。首先,从数据集中抽取所需要的部分。
X_homehigher = dataset[["HomeLastWin", "VisitorLastWin","HomeTeamRanksHigher"]].values
然后,创建DecisionTreeClassifier分类器,进行交叉检验,求得正确率。
clf = DecisionTreeClassifier(random_state=14)scores = cross_val_score(clf, X_homehigher, y_true,scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
现在的正确率是60.3%——比我们之前的结果要好。还能再提高吗?
接下来,我们来统计两支球队上场比赛的情况,作为另一个特征。虽然球队排名有助于预测(排名靠前的胜算更大),但有时排名靠后的球队反而能战胜排名靠前的。原因有很多。例如,排名靠后的球队某些打法恰好能击中强者的软肋。该特征的创建方法与前一个特征类似,首先创建字典,保存上场比赛的获胜队伍,在数据框中建立新特征。代码如下:
last_match_winner = defaultdict(int)dataset["HomeTeamWonLast"] = 0
然后,遍历每条数据,取到每场赛事的两支参赛队伍。
for index, row in dataset.iterrows():home_team = row["Home Team"]visitor_team = row["Visitor Team"]
不用考虑哪支球队是主场作战,我们想看一下这两支球队在上一场比赛中到底谁是赢家。因此,按照英文字母表顺序对球队名字进行排序,确保两支球队无论主客场作战,都使用相同的键。
teams = tuple(sorted([home_team, visitor_team]))
通过查找字典,找到两支球队上次比赛的赢家。然后,更新数据框中这条数据。
row["HomeTeamWonLast"] = 1 if last_match_winner[teams] ==row["Home Team"] else 0dataset.ix[index] = row
最后,更新last_match_winner字典,值为两支球队在当前场次比赛中的胜出者,两支球队再相逢时可将其作为参考。
winner = row["Home Team"] if row["HomeWin"] else row["Visitor Team"]last_match_winner[teams] = winner
下面,用新抽取的两个特征创建数据集。观察不同特征组合的分类效果。代码如下:
X_lastwinner = dataset[["HomeTeamRanksHigher", "HomeTeamWonLast"]].valuesclf = DecisionTreeClassifier(random_state=14)scores = cross_val_score(clf, X_lastwinner, y_true,scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
正确率为60.6%。结果越来越好了。
最后我们来看一下,决策树在训练数据量很大的情况下,能否得到有效的分类模型。我们将会为决策树添加球队,以检测它是否能整合新增的信息。
虽然决策树能够处理特征值为类别型的数据,但scikitlearn库所实现的决策树算法要求先对这类特征进行处理。用LabelEncoder转换器就能把字符串类型的球队名转化为整型。代码如下:
from sklearn.preprocessing import LabelEncoderencoding = LabelEncoder()
将主场球队名称转化为整型:
encoding.fit(dataset["Home Team"].values)
接下来,抽取所有比赛的主客场球队的球队名(已转化为数值型)并将其组合(在NumPy中叫作“stacking”,是向量组合的意思)起来,形成一个矩阵。代码如下:
home_teams = encoding.transform(dataset["Home Team"].values)visitor_teams = encoding.transform(dataset["Visitor Team"].values)X_teams = np.vstack([home_teams, visitor_teams]).T
决策树可以用这些特征值进行训练,但DecisionTreeClassifier仍把它们当作连续型特征。例如,编号从0到16的17支球队,算法会认为球队1和2相似,而球队4和10不同。但其实这没意义,对于两支球队而言,它们要么是同一支球队,要么不同,没有中间状态!
为了消除这种和实际情况不一致的现象,我们可以使用OneHotEncoder转换器把这些整数转换为二进制数字。每个特征用一个二进制数字1来表示。例如,LabelEncoder为芝加哥公牛队分配的数值是7,那么OneHotEncoder为它分配的二进制数字的第七位就是1,其余队伍的第七位就是0。每个可能的特征值都这样处理,而数据集会变得很大。代码如下:
1有多少个特征,二进制数字就有多少位。——译者注
from sklearn.preprocessing import OneHotEncoderonehot = OneHotEncoder()
在相同的数据集上进行预处理和训练操作,将结果保存起来备用。
X_teams_expanded = onehot.fit_transform(X_teams).todense()
接着,像之前那样在新数据集上调用决策树分类器。
clf = DecisionTreeClassifier(random_state=14)scores = cross_val_score(clf, X_teams_expanded, y_true,scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
正确率为60%,比基准值要高,但是没有之前的效果好。原因可能在于特征数增加后,决策树处理不当。鉴于此,我们尝试修改算法,看看会不会起作用。数据挖掘有时就是不断尝试新算法、使用新特征这样一个过程。
3.4 随机森林
一棵决策树可以学到很复杂的规则。然而,很可能会导致过拟合问题——学到的规则只适用于训练集。解决方法之一就是调整决策树算法,限制它所学到的规则的数量。例如,把决策树的深度限制在三层,只让它学习从全局角度拆分数据集的最佳规则,不让它学习适用面很窄的特定规则,这些规则会将数据集进一步拆分为更加细致的群组。使用这种折中方案得到的决策树泛化能力强,但整体表现稍弱。
为了弥补上述方法的不足,我们可以创建多棵决策树,用它们分别进行预测,再根据少数服从多数的原则从多个预测结果中选择最终预测结果。这正是随机森林的工作原理。
但上述过程有两个问题。一是创建的多棵决策树在很大程度上是相同的——每次使用相同的输入,将得到相同的输出。我们只有一个训练集,如果尝试创建多棵决策树,它们的输入就可能相同(因此输出也相同)。解决方法是每次随机从数据集中选取一部分数据用作训练集。这个过程叫作装袋(bagging)。
第二个问题是用于前几个决策节点的特征非常突出。即使我们随机选取部分数据用作训练集,创建的决策树相似性仍旧很大。解决方法是,随机选取部分特征作为决策依据。
然后,使用随机从数据集中选取的数据和(几乎是)随机选取的特征,创建多棵决策树。这就是随机森林,虽然看上去不是那么直观,但这种算法在很多数据集上效果很好。
3.4.1 决策树的集成效果如何
随机森林算法内在的随机性让人感觉算法的好坏全靠运气。然而,通过对多棵几乎是随机创建的决策树的预测结果取均值,就能降低预测结果的不一致性。我们用方差来表示这种不一致。
方差是由训练集的变化引起的。决策树这类方差大的算法极易受到训练集变化的影响,从而产生过拟合问题。
对比来说,偏误(bias)是由算法中的假设引起的,而与数据集没有关系。比如,算法错误地假定所有特征呈正态分布,就会导致较高的误差。通过分析分类器的数据模型和实际数据集的匹配情况,就能降低偏误问题的负面影响。
对随机森林中大量决策树的预测结果取均值,能有效降低方差,这样得到的预测模型的总体正确率更高。
一般而言,决策树集成做出了如下假设:预测过程的误差具有随机性,且因分类器而异。因此,使用由多个模型得到的预测结果的均值,能够消除随机误差的影响——只保留正确的预测结果。本书中会介绍更多用集成方法消除误差的例子。
3.4.2 随机森林算法的参数
scikitlearn库中的RandomForestClassifier就是对随机森林算法的实现,它提供了一系列参数。因为它使用了DecisionTreeClassifier的大量实例,所以它俩的很多参数是一致的,比如决策标准(基尼不纯度/信息增益)、max_features和min_samples_split。
当然,集成过程还引入了一些新参数。
n_estimators:用来指定创建决策树的数量。该值越高,所花时间越长,正确率(可能)也越高。oob_score:如果设置为真,测试时将不使用训练模型时用过的数据。n_jobs:采用并行计算方法训练决策树时所用到的内核数量。
scikitlearn库提供了用于并行计算的Joblib库。n_jobs指定所用的内核数。默认使用1个内核——如果CPU是多核的,可以多用几个,或者将其设置为-1,开动全部马力。
3.4.3 使用随机森林算法
scikitlearn库实现的随机森林算法使用估计器接口,用交叉检验方法调用它即可,代码跟之前大同小异。
from sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(random_state=14)scores = cross_val_score(clf, X_teams, y_true, scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
只是靠更换分类器,正确率就提升了0.6%,达到60.6%。
随机森林使用不同的特征子集进行学习,应该比普通的决策树更为高效。下面来看一下多用几个特征效果如何。
X_all = np.hstack([X_home_higher, X_teams])clf = RandomForestClassifier(random_state=14)scores = cross_val_score(clf, X_all, y_true, scoring='accuracy')print("Accuracy: {0:.1f}%".format(np.mean(scores) * 100))
正确率为61.1%——又有所提升!可以使用GridSearchCV类搜索最佳参数,代码如下:
parameter_space = {"max_features": [2, 10, 'auto'],"n_estimators": [100,],"criterion": ["gini", "entropy"],"min_samples_leaf": [2, 4, 6],}clf = RandomForestClassifier(random_state=14)grid = GridSearchCV(clf, parameter_space)grid.fit(X_all, y_true)print("Accuracy: {0:.1f}%".format(grid.best_score_ * 100))
这次正确率提升较大,达到了64.2%!
输出用网格搜索找到的最佳模型,查看都使用了哪些参数。代码如下:
print(grid.best_estimator_)
下面的代码将给出正确率最高的模型所用到的参数。
RandomForestClassifier(bootstrap=True, compute_importances=None,criterion='entropy', max_depth=None, max_features=2,max_leaf_nodes=None, min_density=None, min_samples_leaf=6,min_samples_split=2, n_estimators=100, n_jobs=1,oob_score=False, random_state=14, verbose=0)
3.4.4 创建新特征
从上述几个例子中,我们看到改变特征对算法的表现有很大影响。经过小规模测试发现,仅仅是因为选用不同的特征,正确率竟然提升了10%。
用pandas提供的函数创建特征。代码如下:
dataset["New Feature"] = feature_creator()
feature_creator函数返回数据集中每条数据的各个特征值。常用数据集作为参数。
dataset["New Feature"] = feature_creator(dataset)
最直接的做法是一开始为新特征设置默认的值,比如0。如下所示:
dataset["My New Feature"] = 0
接下来,遍历数据集,计算所需特征。本章曾多次用下面这种形式创建新特征。
for index, row in dataset.iterrows():home_team = row["Home Team"]visitor_team = row["Visitor Team"]# Some calculation here to alter rowdataset.ix[index] = row
请注意,上面这种遍历方法效率不高。如果你要用的话,请一次性处理所有特征。常用的“最佳做法”就是每条数据最好只处理一次。
你可以创建下述特征并看一下效果。
球队上次打比赛距今有多长时间?短期内连续作战,容易导致球员疲劳。
两支球队过去五场比赛结果如何?这两个数据要比
HomeLastWin和VisitorLastWin更能反映球队的真实水平(抽取特征方法类似)。球队是不是跟某支特定球队打比赛时发挥得更好?例如,球队在某个体育场里打比赛,即使是客场作战也能发挥得很好。
如果抽取上面这些特征遇到困难,请参考pandas的文档http://pandas.pydata.org/pandas-docs/stable/。此外,还可以尝试从Stack Overflow等社区寻求帮助。
更极致的做法是,借助球员数据来分析每个队的实力以预测输赢。其实,赌徒和体育博彩机构每天都在用这些复杂的特征预测赛事结果来牟利。
3.5 小结
本章使用scikitlearn库的另一个分类器DecisionTreeClassifier,并介绍了如何用pandas处理数据。我们分析了真实的NBA赛事的比赛结果数据,创建新特征用于分类,并在这个过程中发现即使是规整、干净的数据也可能存在一些小问题。
我们发现好的特征对提升正确率很有帮助,还使用了一种集成算法——随机森林,进一步提升正确率。
下一章将会扩展在第1章使用的亲和性分析算法,用来发现相似的电影。我们还将学到如何用算法解决排序问题,以及如何提升数据挖掘算法的可扩展性。
